CUDA编程入门:可伸缩并行编程模型
需积分: 10 97 浏览量
更新于2024-07-22
收藏 1.89MB PDF 举报
"CUDA入门经典——计算统一设备架构的编程指南"
CUDA(Compute Unified Device Architecture)是 NVIDIA 提出的一种并行计算平台和编程模型,专为利用 GPU(图形处理单元)的强大计算能力而设计。这份CUDA编程指南是针对版本2.0的,旨在帮助开发者理解和掌握CUDA编程,从而有效地进行GPU并行计算。
在介绍CUDA之前,我们需要理解GPU的基本特性。GPU是一种高度并行化、多线程、多核处理器,设计之初主要用于图形渲染和游戏应用。但随着技术的发展,GPU被发现非常适合大规模并行计算任务,因此CUDA应运而生,提供了一个可以直接利用GPU计算能力的编程框架。
文档结构主要分为以下几个部分:
1. **简介**:介绍了CUDA作为一个可伸缩的并行编程模型,如何使开发者能够利用GPU的并行性来加速计算密集型任务。它解释了CUDA如何通过将计算任务分布在大量的线程上,实现高效并行处理。
2. **编程模型**:这部分详细描述了CUDA的线程层次结构,包括线程块、线程网格以及在GPU上如何组织和调度这些线程。同时,还讲解了存储器层次结构,包括全局内存、共享内存、常量内存和纹理内存等,以及它们的访问特点和性能优化策略。此外,还涵盖了主机和设备间的交互,软件栈的构成,以及计算能力的定义,这是衡量GPU并行计算能力的关键指标。
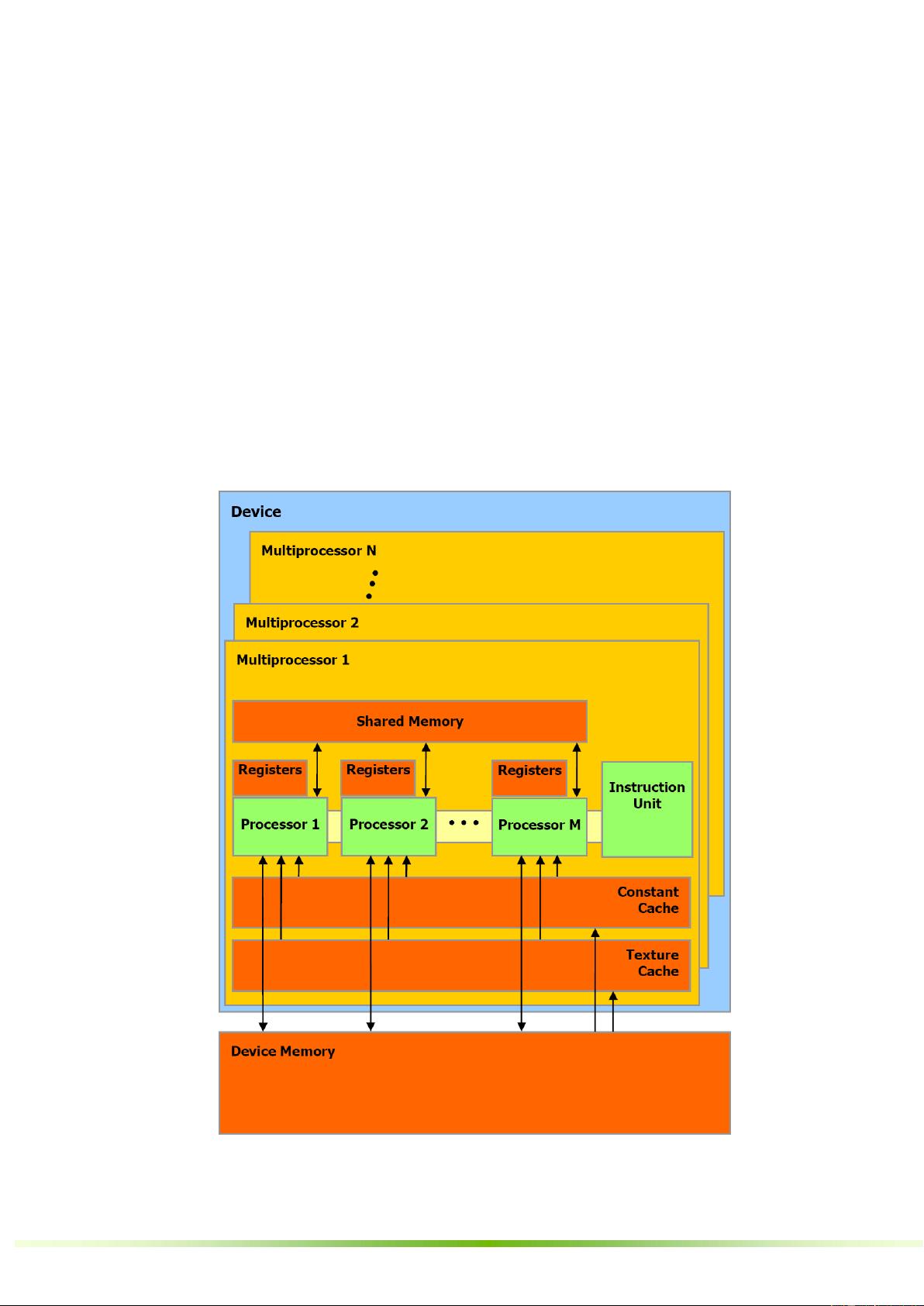
3. **GPU实现**:这部分深入到GPU的硬件实现,如SIMT(单指令多线程)多处理器,以及如何通过芯片共享存储器来支持线程间的协作。同时,讨论了多设备环境下的CUDA编程,以及模式切换机制,使得开发者可以灵活地管理多个GPU。
4. **应用程序编程接口(API)**:CUDA API是开发者与GPU通信的主要途径。这里详细列举了C语言的扩展,包括函数和变量类型限定符,如 `_device_`、`_global_`、`_host_` 和 `__constant__`,以及对应的存储空间。此外,还有执行配置、内置变量(如 `gridDim`、`blockIdx`、`threadIdx` 和 `warpSize`),以及编译指令(如 `__noinline__` 和 `__pragma unroll`)。最后,介绍了通用的运行时组件,如内置向量类型,这些优化了数据传输和运算效率。
学习CUDA编程不仅需要理解上述概念,还需要实践编写kernel函数,管理内存,优化并行计算,以及理解和利用CUDA的错误处理机制。通过这份指南,开发者可以逐步掌握CUDA编程技巧,充分利用GPU的并行计算潜力,从而在科学计算、图像处理、物理模拟等领域提升应用程序的性能。
CUDA
编程指南,版本
2.0 7
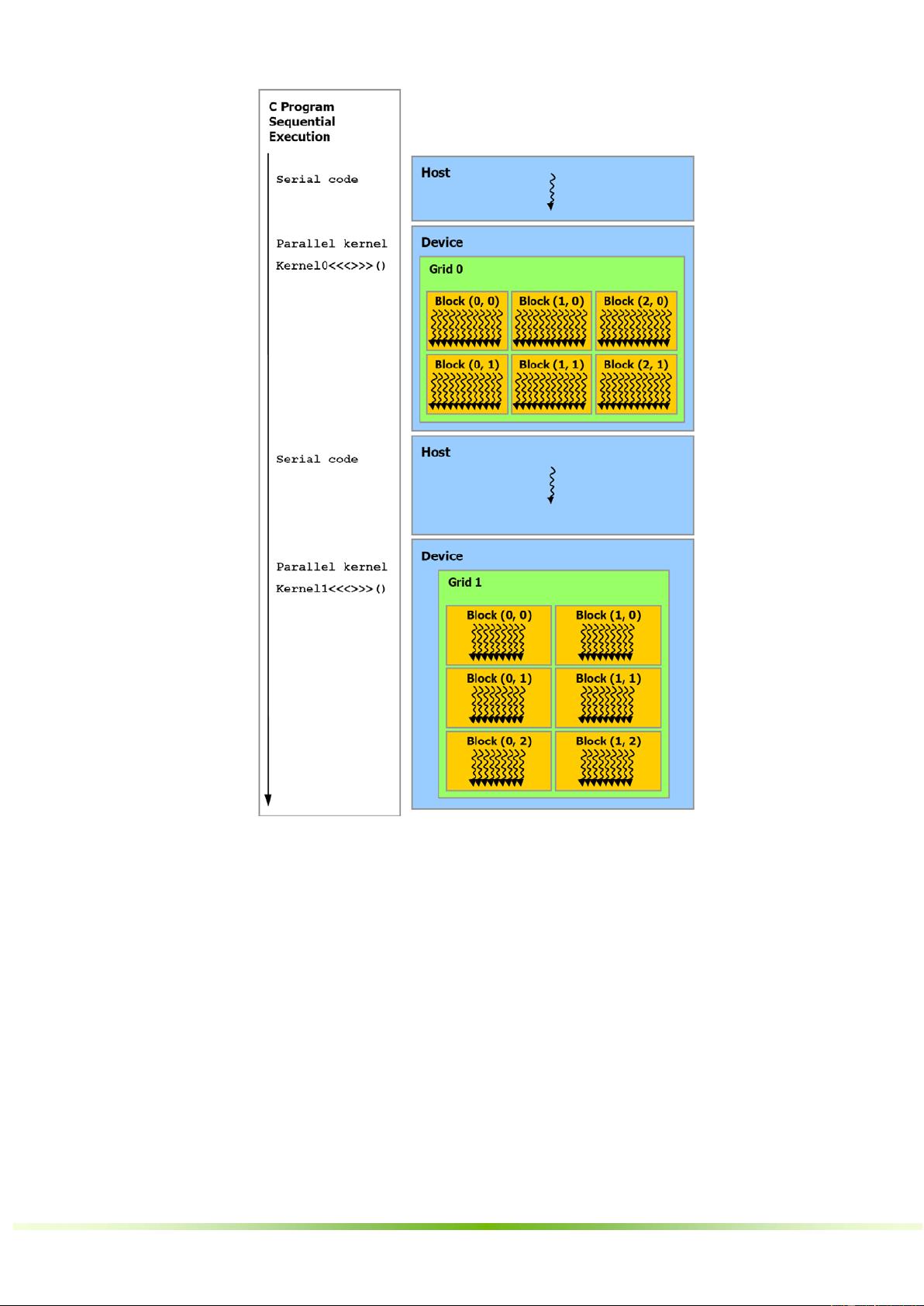
串行代码在主机上执行,而并行代码在设备上执行。
图 2-3. 异构编程
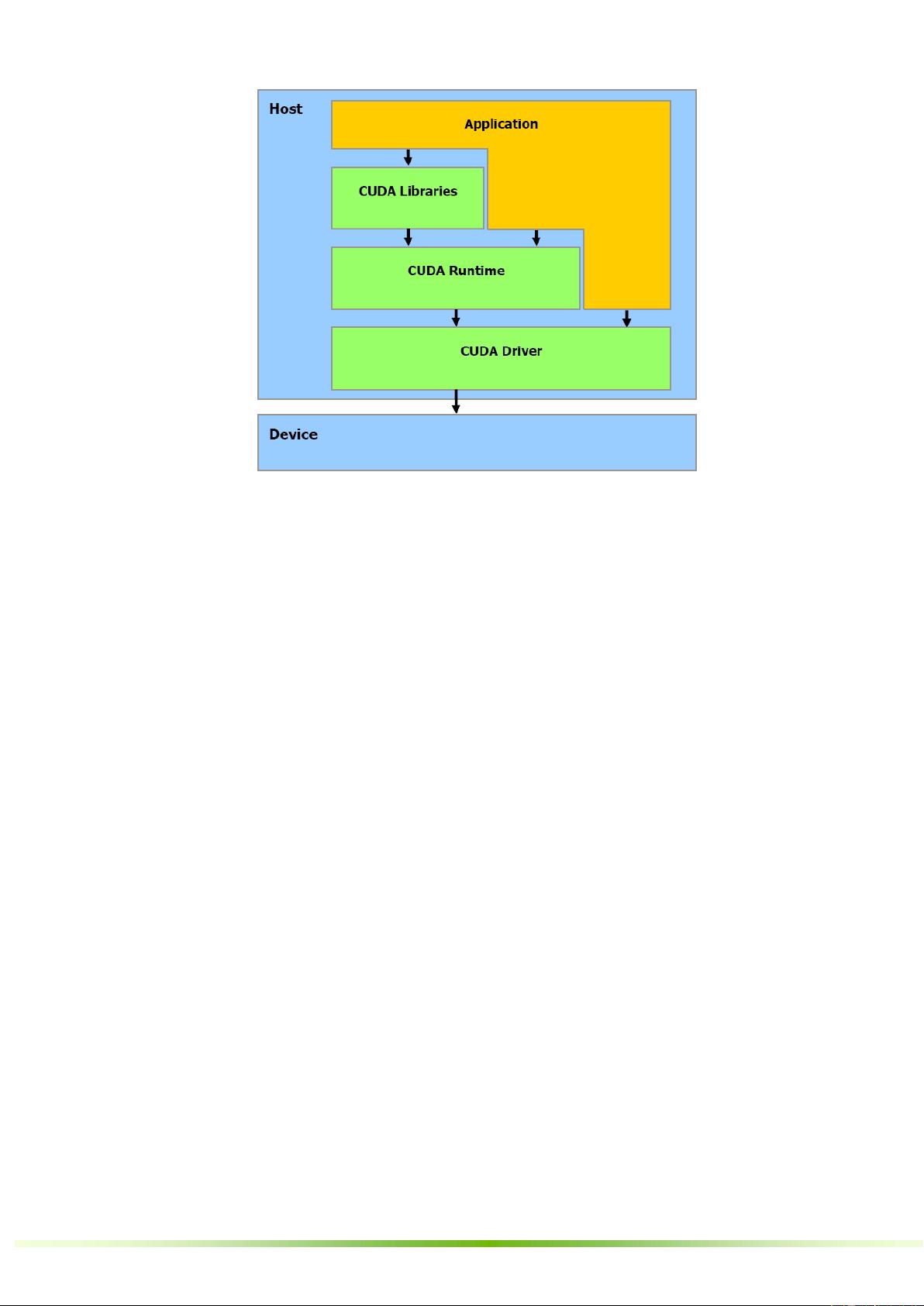
2.4 软件栈
CUDA 软件栈包含多个层,如图 2-4 所示:设备驱动程序、应用程序编程接口(API)及其运行时、两个
较高级别的通用数学库,即 CUFFT 和 CUBLAS,这些内容均在其他文档中介绍。

剩余76页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-09-14 上传
2009-06-19 上传
2012-11-20 上传
2016-02-26 上传
2018-12-30 上传

mokingkong
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
