Win10环境下Python安装Scrapy与数据抓取指南
需积分: 9 152 浏览量
更新于2024-08-13
收藏 739KB DOCX 举报
"本文档详细介绍了在Windows 10操作系统上如何安装Python的Scrapy框架,并利用该框架进行数据抓取。首先,建议使用Anaconda作为Python环境的管理工具,因为Anaconda集成了许多常用的数据科学库,方便后续开发。接下来,我们将分步骤介绍安装过程。
1. **安装Anaconda**
- 访问官方网站[https://www.anaconda.com/products/individual](https://www.anaconda.com/products/individual),下载适用于Windows 10的Anaconda版本。根据个人需求选择Python 3.x的64位安装包。
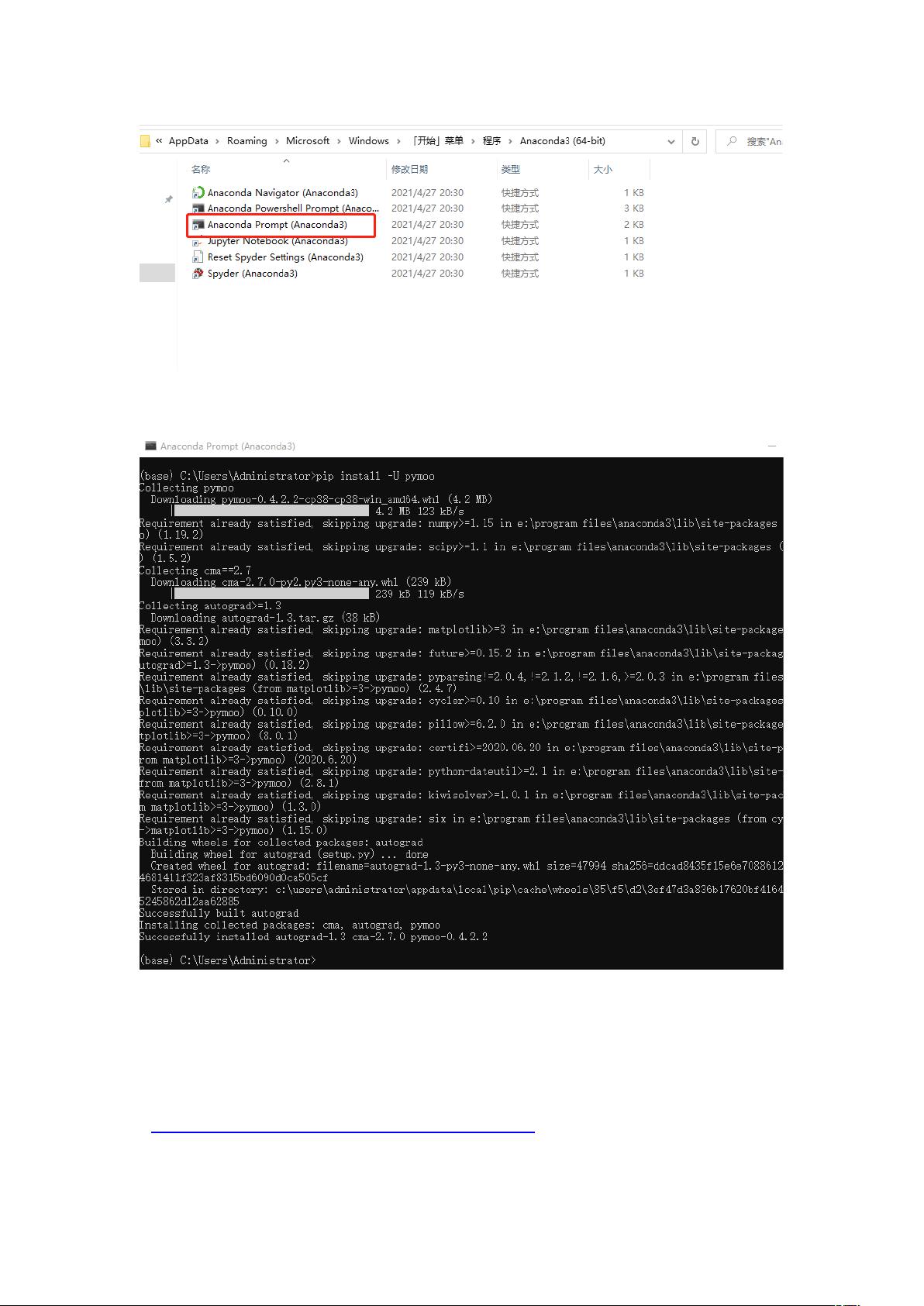
- 完成安装后,启动Anaconda。你可以通过开始菜单找到Anaconda的快捷方式,或者在`C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\StartMenu\Programs\Anaconda3(64-bit)`路径下找到启动程序。
- 在Anaconda的命令行环境中,使用`pip install upymoo`来安装额外的库,如upymoo,这虽然不是安装Scrapy的必要步骤,但可能对某些用户有用。
2. **安装Scrapy**
- 打开命令提示符(cmd),使用`pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple/`命令来安装Scrapy。这里使用了清华大学的镜像源,可以提高国内用户的下载速度。
- 安装完成后,运行`pip list`检查已安装的库,确认Scrapy出现在列表中,表明安装成功。
3. **使用PyCharm配置Scrapy项目**
- 在PyCharm中创建一个新的项目,选择Scrapy项目模板。这会自动创建Scrapy项目的结构。
- 进入项目设置,确保Python解释器是Anaconda环境下的Python,这样项目就能使用到Anaconda中的所有已安装库,包括Scrapy。
4. **开发Scrapy爬虫**
- 在项目中的`maoyan/spiders`目录下,创建一个新的Python文件,例如`maoyan.py`,在这个文件中编写Scrapy爬虫代码。
- 编写完成后,设置好爬虫的起始URL和其他配置。
5. **运行Scrapy爬虫**
- 在命令提示符中,导航到你的项目根目录,然后运行`scrapy crawl maoyan`命令来执行刚创建的`maoyan`爬虫。
通过以上步骤,你已经在Windows 10上成功安装了Scrapy并创建了一个简单的数据抓取项目。Scrapy是一个强大的Web爬虫框架,它提供了丰富的功能,如请求调度、解析HTML、处理异步操作等,非常适合用于数据抓取和网络数据的分析。在实际应用中,你还可以根据需要添加更多的中间件、管道和设置,以适应不同的爬取需求。记得在抓取数据时遵守网站的robots.txt规则和相关法律法规,确保合法合规地进行数据获取。"
剩余12页未读,继续阅读
2021-12-07 上传
516 浏览量
187 浏览量
2023-05-30 上传
290 浏览量
2023-06-11 上传
107 浏览量
293 浏览量

风之梦丽
- 粉丝: 320
 我的内容管理
展开
我的内容管理
展开







最新资源
- Laravel框架介绍:Web开发的新选择
- SURF与RANSAC在图像细配准中的应用研究
- 单片机期末设计项目:贪吃蛇、俄罗斯方块与打砖块
- EthPIPE FPGA实现以太网性能提升方案
- 朴实无华的仿中企动力手机wap企业网站模板
- M1卡控制字算法程序深入解析
- 易语言实现文本显示的打字效果教程
- JavaScript巴布奎兹:压缩包子主文件解析
- 基于JSP和MYSQL的物流信息网站毕业设计项目
- Objective-C中自定义单例警报控制器的实现
- Linux下使用iptables实现静态无状态双向NAT教程
- UCI机器学习二分类数据集资源下载
- Java测试技术分析与实践
- QRCodeFactory:快速高效的二维码批量生成
- 易语言超级列表框行间距调整模块源码解析
- 克洛夫:HTML技术的最新动向与进展
