Spark架构详解:速度提升100倍,大数据处理新选择
89 浏览量
更新于2024-08-29
收藏 823KB PDF 举报
Apache Spark是一个专为大规模数据处理而设计的高性能框架,它由加州大学伯克利分校的AMPLab于2009年开发,2010年正式成为Apache的开源项目。相较于Hadoop和MapReduce等技术,Spark以其显著的速度提升和统一的处理能力脱颖而出。Spark的优势主要体现在以下几个方面:
1. **全面统一的框架**:Spark提供了一整套处理各种类型数据(如文本、图形数据)和来源(批量或实时流)的统一框架,无论是简单的批处理还是复杂的实时分析,都能高效地应对。
2. **内存计算速度提升**:Spark通过将数据加载到内存中执行计算,官方数据显示,相比于Hadoop集群,其在内存中的应用速度可以提升100倍,磁盘上的速度也能提升10倍,极大地提高了数据处理效率。
3. **运行模式与组件**:
- **Spark Core**:是Spark的基础,提供了RDD(弹性分布式数据集)API,操作以及它们之间的动作,是构建其他Spark模块的基础。
- **Spark SQL**:允许用户通过HiveQL进行SQL查询,将数据库表抽象为RDD,简化了数据分析过程。
- **Spark Streaming**:专为实时数据流处理设计,支持类似RDD的API,便于处理连续的数据流任务。
- **MLlib**:机器学习库,封装了许多机器学习算法,支持对大量数据集的迭代操作,如分类、回归等。
- **GraphX**:针对图数据处理的工具集,扩展了RDD API,支持图操作和计算。
4. **部署模式**:
- **Standalone模式**:适用于小型、独立的集群环境,Master节点负责调度和监控Worker节点。
- **YARN模式**:与Hadoop YARN集成,利用YARN的资源管理和调度,适用于大型分布式集群环境。
5. **术语理解**:理解核心概念如Master、Worker、RDD、DataFrame、SparkContext等有助于深入掌握Spark的工作原理。
通过Spark的这些特点和组成部分,开发者可以灵活地处理大规模数据,无论是简单的数据清洗,还是深度的数据分析和机器学习任务,Spark都能提供强大的支持。Spark的架构和生态设计使得它在处理现代大数据场景中扮演了至关重要的角色。
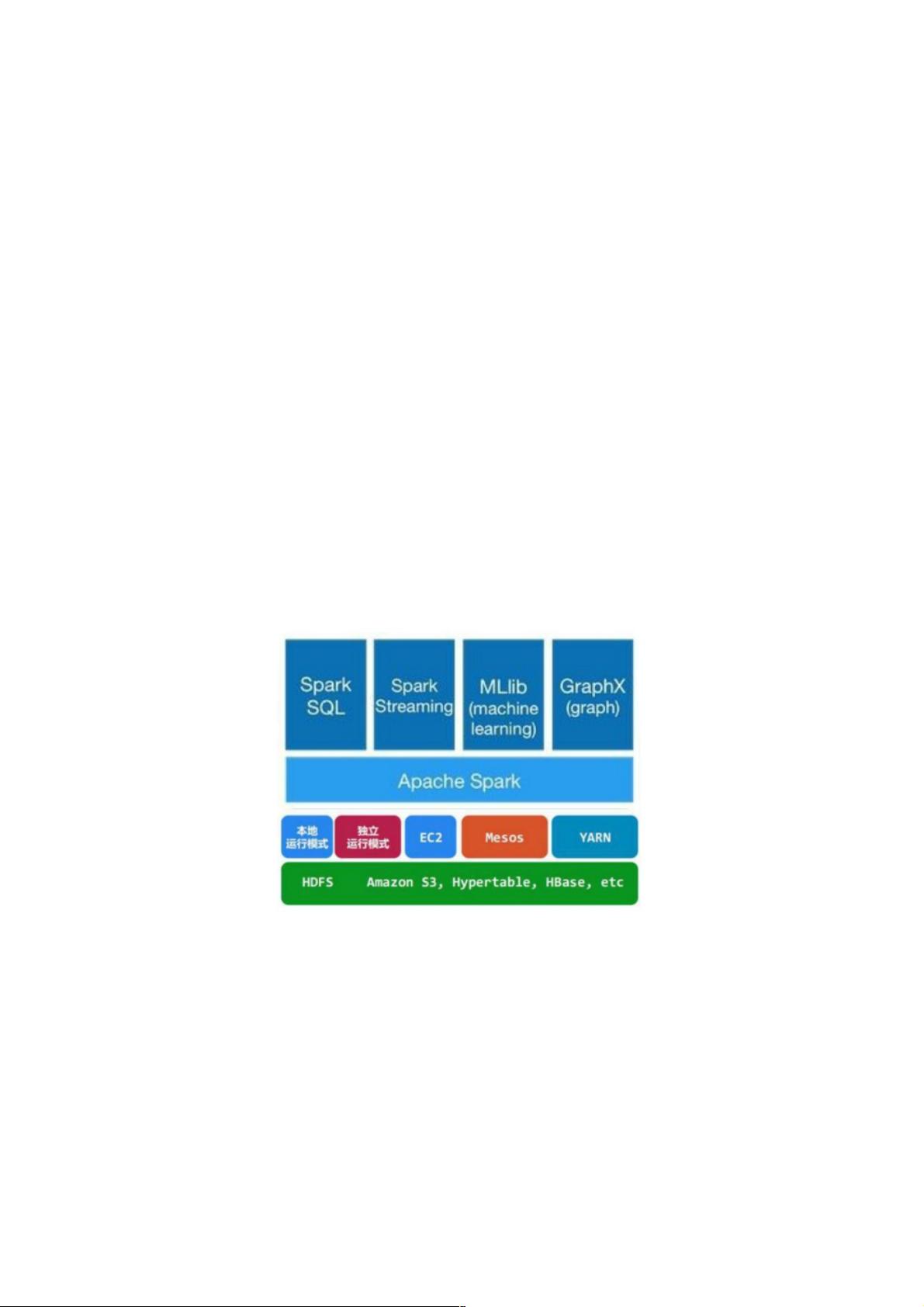
Spark基本架构及原理基本架构及原理
Apache Spark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab
开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优
势:
Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实
时的流数据)的大数据处理的需求
官方资料介绍Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10
倍
目标:
1.架构及生态
2.spark 与 hadoop
3.运行流程及特点
4.常用术语
5.standalone模式
6.yarn集群
7.RDD运行流程
架构及生态:
通常当需要处理的数据量超过了单机尺度(比如我们的计算机有4GB的内存,而我们需要处理100GB以上的数据)这时我们可以
选择spark集群进行计算,有时我们可能需要处理的数据量并不大,但是计算很复杂,需要大量的时间,这时我们也可以选择
利用spark集群强大的计算资源,并行化地计算,其架构示意图如下:
Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和
Spark Core之上的
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个
RDD,Spark SQL查询被转换为Spark操作。
Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需
要对大量数据集进行迭代的操作。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径
上所有顶点的操作
Spark架构的组成图如下:
下载后可阅读完整内容,剩余8页未读,立即下载
2018-12-02 上传
2018-05-29 上传
2021-02-24 上传
点击了解资源详情
点击了解资源详情
2023-05-17 上传
2018-01-23 上传
2018-01-29 上传
2017-12-14 上传

weixin_38748556
- 粉丝: 6
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
