贪心算法详解:哈夫曼编码压缩原理与优化
 已收录资源合集
已收录资源合集
"这篇文档是关于贪心算法在解决哈夫曼编码问题上的应用,主要讲述了哈夫曼编码的原理、特点以及如何构建最优的哈夫曼树进行编码。"
哈夫曼编码是一种高效的无损数据压缩方法,尤其适用于字符频率分布不均匀的数据。它的核心思想是利用贪心策略,为出现频率较高的字符分配较短的编码,而频率较低的字符分配较长的编码,从而在整体上降低编码的平均长度,达到压缩数据的目的。
在文档中提到,假设有一个包含100,000个字符的文件,各字符的出现频率不同。如果采用定长编码,每个字符都用3位二进制表示,那么整个文件的编码长度将是300,000位。但如果采用变长编码,即哈夫曼编码,通过为高频字符分配更短的编码,文件的编码长度可以减少到224,000位,相比于定长编码减少了约25%,体现了哈夫曼编码的优越性。
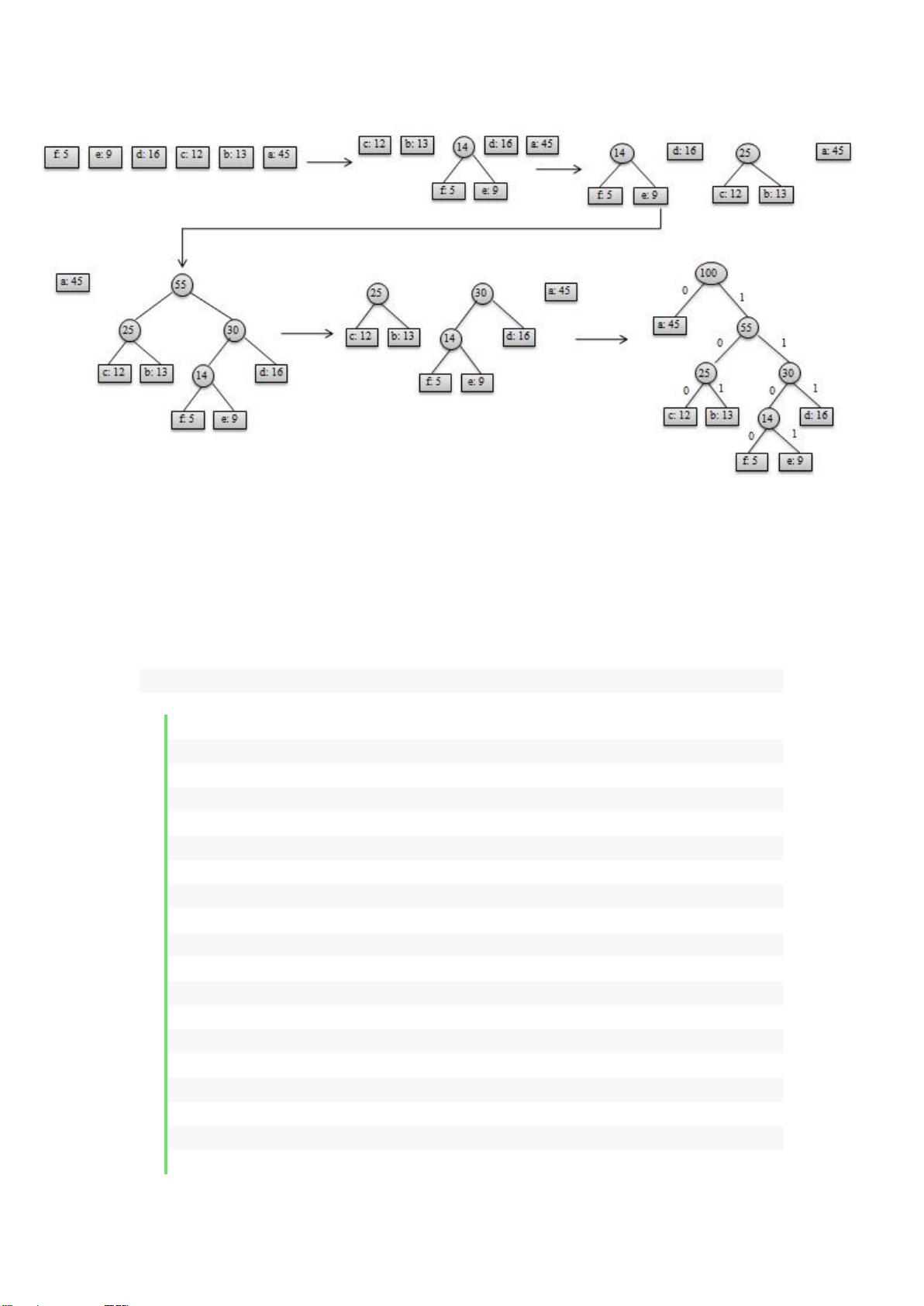
哈夫曼编码的关键特性是前缀码,也就是任何字符的编码都不能是另一个字符编码的前缀。这使得解码过程变得简单,因为一旦遇到一个完整的编码序列,就可以立即识别出对应的字符。为了实现这个特性,哈夫曼编码通常使用二叉树来表示,每个叶子节点代表一个字符,从根节点到叶子节点的路径就是该字符的编码,路径上的0和1分别指示向左或向右子节点的路径。
文档中提到了一个二叉树的例子,展示了定长编码和哈夫曼编码的对比。哈夫曼树总是完全二叉树,意味着所有叶子节点都在同一层级或靠左的层级上。而在非最优的定长编码方案中,二叉树可能不是完全二叉树,导致编码效率低下。
构建哈夫曼编码的过程通常包括以下步骤:
1. 创建一个空的优先队列(通常是堆)。
2. 将每个字符及其频率作为一个带有两个属性的节点(字符和频率)放入队列。
3. 每次从队列中取出两个频率最低的节点,合并成一个新的节点,其频率是两个取出节点的频率之和,然后将新节点放回队列。
4. 重复步骤3,直到队列中只剩下一个节点,这个节点就是哈夫曼树的根节点。
5. 从根节点到每个叶子节点的路径就构成了哈夫曼编码。
平均码长定义为所有字符编码长度乘以其相应的频率之和,然后除以总字符数。哈夫曼编码的目标就是找到一种编码方案,使得这个平均码长达到最小,这就是所谓的最优前缀码。
通过哈夫曼编码,可以有效地减少数据存储和传输的需求,特别是在文本、图像和音频压缩等领域有着广泛应用。对于特定的字符集和频率分布,可以通过哈夫曼编码构建出一棵对应的二叉树,其中的叶子节点数量等于字符集的大小,内部节点数量等于字符集大小减一。这个二叉树的结构保证了编码的前缀码特性,使得解码高效且无歧义。
第 4 页 共 16 页
具体代码实现如下:
(1)4d4.cpp,程序主文件
[cpp] view plain copy
1. //4d4 贪心算法 哈夫曼算法
2. #include "stdafx.h"
3. #include "BinaryTree.h"
4. #include "MinHeap.h"
5. #include <iostream>
6. using namespace std;
7.
8. const int N = 6;
9.
10. template<class Type> class Huffman;
11.
12. template<class Type>
13. BinaryTree<int> HuffmanTree(Type f[],int n);
14.
15. template<class Type>
16. class Huffman
17. {
18. friend BinaryTree<int> HuffmanTree(Type[],int);
19. public:
剩余15页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-11 上传
2022-11-11 上传
2018-07-04 上传
2022-10-30 上传
2022-10-30 上传
2021-09-05 上传


dllglvzhenfeng
- 粉丝: 1w+
- 资源: 1922
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
