"Linux环境下Hadoop等大数据软件搭建与配置详解"。
需积分: 10 128 浏览量
更新于2024-03-25
收藏 3.83MB DOCX 举报
本文档旨在描述在Linux环境下搭建包括Hadoop、Zookeeper、Flume、Kafka、MySQL、Hive、Redis、Elasticsearch、RabbitMQ、HBase、Spark、Storm、Azkaban等相关软件的步骤。首先,我们需要创建一个基于虚拟机的环境来部署这些软件。
1. 软件安装目录及版本信息:
1.1 JDK:jdk1.8.0_131
1.2 Hadoop:hadoop-2.8.2
1.3 Zookeeper:zookeeper-3.4.10
1.4 Flume:apache-flume-1.9.0
1.5 Kafka:kafka_2.12-2.3.0
1.6 MySQL:mysql-8.0.17
1.7 Hive:apache-hive-2.3.6
1.8 Redis:redis-5.0.5
1.9 Elasticsearch:elasticsearch-7.3.1
1.10 RabbitMQ:rabbitmq-server-3.7.17
1.11 HBase:hbase-2.2.1
1.12 Spark:spark-2.4.4
1.13 Storm:apache-storm-2.0.0
1.14 Azkaban:azkaban-3.50.0
在安装这些软件之前,我们首先需要确保系统已经安装了相应的依赖包。接着,我们将根据每个软件的安装文档逐步进行安装和配置工作。
首先,我们需要安装JDK。将JDK安装包解压到指定目录,并设置JAVA_HOME环境变量。接着,配置Hadoop。我们需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml以及yarn-site.xml,并启动Hadoop集群。
接下来,我们安装Zookeeper。我们需要编辑Zookeeper的配置文件zoo.cfg,设置Zookeeper的数据目录和日志目录,并启动Zookeeper集群。再安装Flume。编辑Flume的配置文件,包括flume-conf.properties,配置数据源和数据目的地,并启动Flume agent。
然后,我们安装Kafka。编辑Kafka的配置文件server.properties,配置Kafka的Broker和Zookeeper的连接信息,在Kafka集群中创建topic。继续安装MySQL。我们需要创建MySQL数据库及用户,并导入相关表结构数据。
接着,安装Hive。编辑Hive的配置文件hive-site.xml,配置Hive的数据存储位置及元数据存储数据库,并启动Hive服务。再安装Redis。编辑Redis的配置文件redis.conf,设置Redis的数据存储目录和密码,并启动Redis服务。
继续安装Elasticsearch。编辑Elasticsearch的配置文件elasticsearch.yml,配置Elasticsearch的集群名称、数据目录、内存分配等参数,启动Elasticsearch集群。再安装RabbitMQ。编辑RabbitMQ的配置文件rabbitmq.config,设置RabbitMQ的目录及用户权限,并启动RabbitMQ服务。
然后,我们安装HBase。编辑HBase的配置文件hbase-site.xml,设定HBase的数据存储目录和Zookeeper的连接信息,并启动HBase服务。接着安装Spark。配置Spark的配置文件spark-defaults.conf,设置Spark的运行参数,启动Spark集群。
继续安装Storm。编辑Storm的配置文件storm.yaml,配置Storm的数据目录及Zookeeper连接信息,启动Storm集群。最后,安装Azkaban。编辑Azkaban的配置文件azkaban.properties,配置Azkaban的数据存储位置及Web服务器端口,启动Azkaban服务。
总之,本文档详细介绍了在Linux环境下搭建Hadoop、Zookeeper、Flume、Kafka、MySQL、Hive、Redis、Elasticsearch、RabbitMQ、HBase、Spark、Storm、Azkaban等软件的步骤,为用户提供了一个完整的参考指南。希望能帮助用户顺利完成软件的安装和配置工作,实现大数据处理和分析的目标。

F网关 这里为默认网关 与你的物理机所在网段一直 如 ;;;;;;;;;
A-$EF主的 A-$
A-$EF备用 A-$
;%= 编辑完成输入’#@保存退出
;$= 重启网卡指令:
;,= 按照以上步骤即可实现 215 模式,如果 ! 不通,关闭防火
墙。
;= 关闭防火墙
46 查看防火墙:FC&3%%
46 关闭防火墙:F%%%C&3&'"
46 禁止 C&3 开机启动:F%%"!
C&3&'"
;= 设置
修改命令:'":%:%#
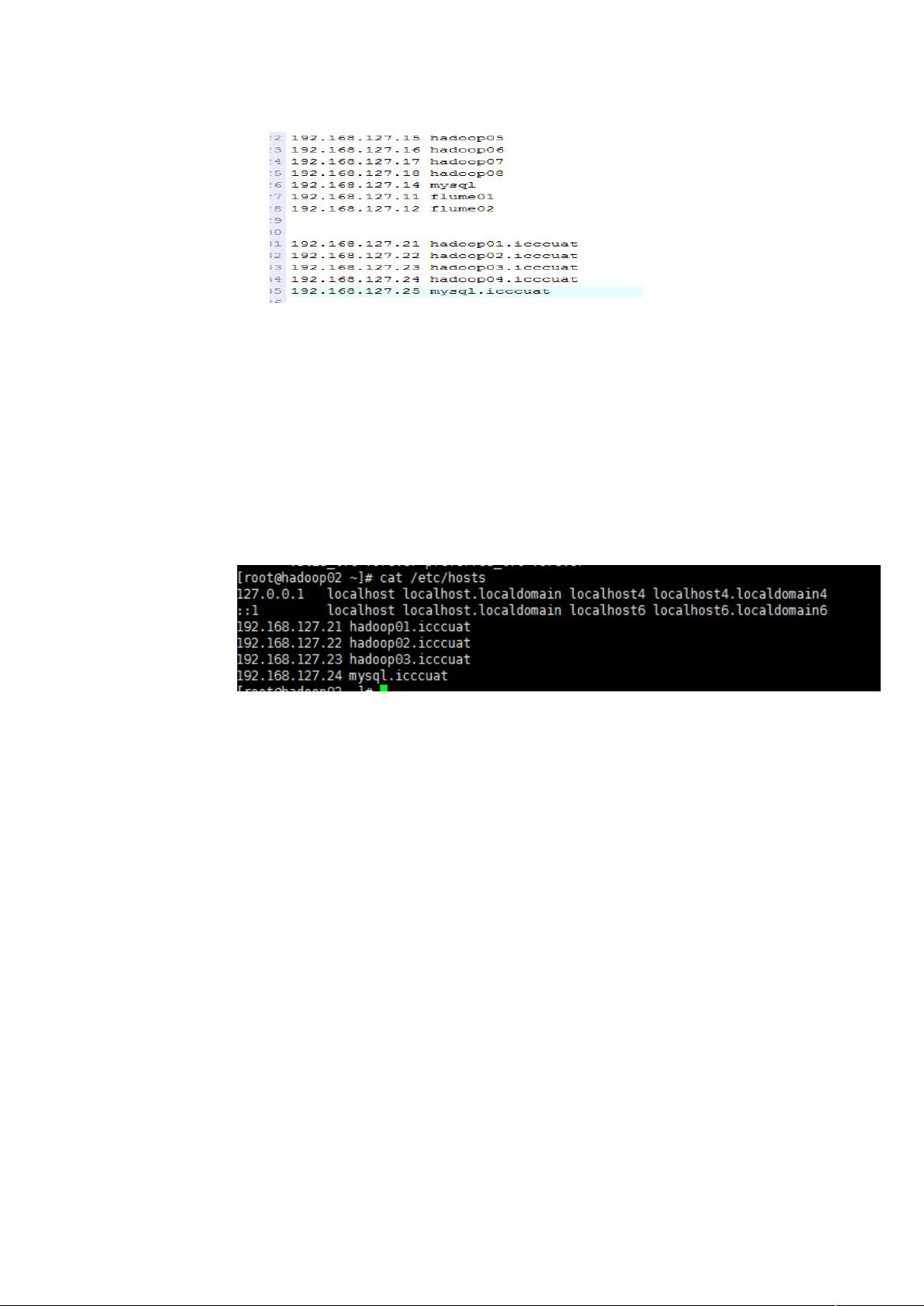
;%= 设置 配置主机名和 映射
= 在 下设置 配置主机名和 映射
I"#3 下路径:B>PI"#3P$%P&"'&P%
剩余56页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-09-09 上传
2020-04-19 上传
2020-02-27 上传

做自己的太阳·
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
