大规模语义网络结构:统计分析与模型
"这篇论文深入探讨了语义网络分析,主要关注三种类型的语义网络:单词联想、WordNet和Roget's Thesaurus的大型结构。通过对这些网络的统计分析,作者揭示了它们具有小世界结构,即稀疏连接、短平均路径长度以及强烈的局部聚类特性。此外,节点连接数的分布遵循幂律,表明存在一种无标度的连接模式,大多数节点拥有相对较少的连接,而少数节点作为中心节点拥有大量连接,形成了所谓的‘枢纽’。这种规律性也在其他复杂的自然网络如万维网中被发现,但与基于继承的传统语义组织模型并不一致。"
在本文中,语义网络分析是一个关键概念,它涉及到如何理解和建模词汇之间以及概念之间的关系。通过分析不同类型的语义网络,我们可以了解到这些网络在大规模结构上的共性。例如,"小世界结构"是指尽管网络中的节点通常连接稀疏,但任意两个节点之间的平均距离(路径长度)却相对较短,这意味着信息可以在网络中快速传播。这种结构在现实世界中的许多网络中都得到了验证,包括社会网络和生物网络。
"强局部聚类"是指网络中的节点往往倾向于与其邻近的节点形成紧密的集群,这反映了语义上的相似性和相关性。例如,在WordNet中,同义词和相关概念往往紧密相连,形成了紧密的簇。
"幂律分布"则揭示了节点连接数的不均匀性,大多数节点有少量链接,而少数节点(称为“中心节点”或“枢纽”)具有大量的连接。这种分布模式在现实世界的复杂网络中非常常见,比如互联网上的网页链接分布。在语义网络中,这些中心节点可能代表一些核心概念或高频词汇,它们连接着大量其他概念,构成了网络的主要脉络。
论文还指出,这些观察到的规律与传统的基于继承的语义组织模型不一致。传统模型往往假设语义关系是自上而下的层次结构,而实际的语义网络则展现出更加复杂和非线性的拓扑结构。这一发现对于理解人类认知、自然语言处理以及知识图谱的构建具有重要意义,因为它提供了一种更为精确的语义关系建模方式。

tions in a network, it is possible for two networks to have the same number of connections but dif
-
ferent clustering coefficients(see Fig. 2).Finally, notethat because the definitionsforT
i
and k
i
are
independent of whether the connections are based on edges or arcs, the clustering coefficients for
a directed network and the corresponding undirected network are equal.
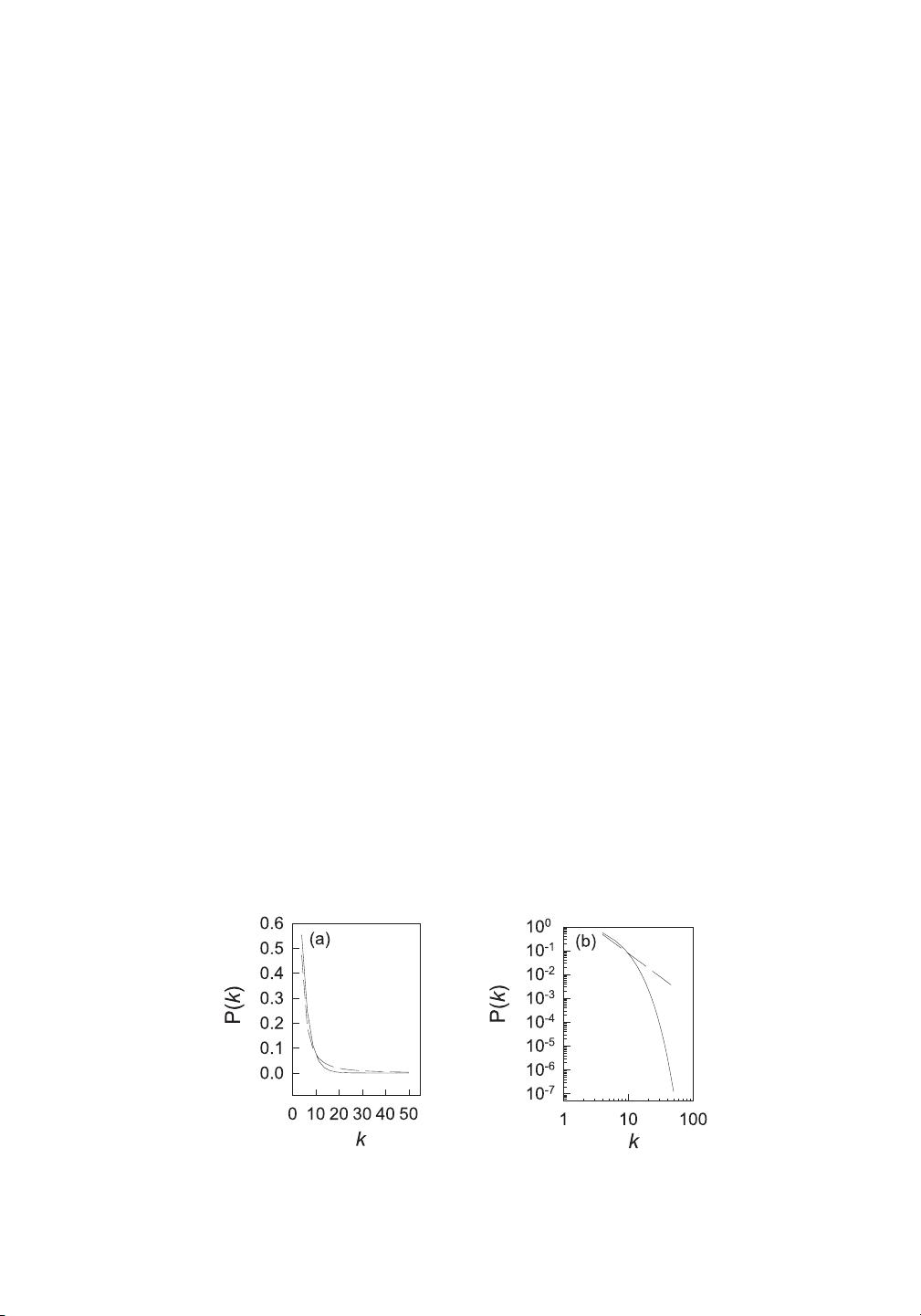
The degree distribution P(k) represents the probability that a randomly chosen node will
have degree k (i.e., will have k neighbors). For directed networks, we will concentrate on the
distribution of in-degrees, although one can also look at the out-degree distribution. We esti
-
mate these distributions based on the relative frequencies of node degrees found throughout the
network. The most straightforward feature of P(k) is the expected value <k> under P(k). This
quantity, estimated by simply averaging the degree of all nodes over the network, ranges be
-
tween 0 and n (for a fully connected network of n nodes) and represents the mean density of
connections in the network. More information can be gleaned by plotting the full distribution
P(k) as a function of k, using either a bar histogram (for small networks, as in Fig. 2), a binned
scatter plot (for large networks, as in Fig. 5), or a smooth curve (for theoretical models, as later
illustrated in Fig. 3). As we explain in the next section, the shapes of these plots provide char
-
acteristic signatures for different kinds of network structure and different processes of network
growth.
Fig. 2 shows these statistical measures for two different networks with 10 nodes and 15
edges. These examples illustrate how networks equal in size and density of connections may
differ significantly in their other structural features. Fig. 2 also illustrates two general proper-
ties of random graphs—graphs that are generated by placing an edge between any two nodes
with some constant probability p independent of the existence of any other edge (a model intro-
duced by Erdös and Réyni, 1960). First, for fixed n and <k>, high values of C tend to imply
high values of L and D. Second, the degree distribution P(k) is approximately bell shaped, with
an exponential tail for high values of k.
4
Although these two properties hold reliably for ran-
dom graphs, they do not hold for many important natural networks, including semantic net-
works in natural language. We next turn to a detailed discussion of the small-world and
scale-free structures that do characterize natural semantic networks. Both of these structures
can be thought of in terms of how they contrast with random graphs: Small-world structures
are essentially defined by the combination of high values of C together with low values of L
and D, whereas scale-free structures are characterized by non-bell-shaped degree distributions,
with power-law (rather than exponential) tails.
3. Small-world and scale-free network structures
Interest in the small-world phenomenon originated with the classic experiments of Milgram
(1967) on social networks. Milgram’s results suggested that any two people in the United
States were, on average, separated by only a small number of acquaintances or friends (popu
-
larly known as “six degrees of separation”). Although the finding of very short distances be
-
tween random pairs of nodes in a large, sparsely connected network may seem surprising, it
does not necessarily indicate any interesting structure. This phenomenon occurs even in the
random graphs described previously, where each pair of nodes is joined by an edge with proba
-
bility p. When p is sufficiently high, the whole network becomes connected, and the average
distance L grows logarithmically with n, the size of the network (Erdös & Réyni, 1960).
M. Steyvers, J. B. Tenenbaum/Cognitive Science 29 (2005) 47
剩余37页未读,继续阅读
371 浏览量
336 浏览量
238 浏览量
429 浏览量
2022-08-04 上传
238 浏览量
919 浏览量
512 浏览量
223 浏览量

u014695262
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- python-3.4.4
- elemental-lowcode:元素低码开发平台
- Logger:记录工具
- SheCodes-WeatherApp:挑战3
- 阿宾贝夫前端测试
- 银灿IS917U盘PCB电路(原理图+PCB图)-其它其他资源
- registry-url:获取设置的npm注册表URL
- ST-link驱动.rar
- keen-gem-example:一个 Sinatra 应用程序,使用敏锐的 gem 异步发布事件
- 行业分类-设备装置-一种抗菌纸.zip
- Pearl-Hacks-2021:线框的htmlcss骨架
- a2s-rs:源代码查询的Rust实现
- DotFiles:我的Dotfiles <3
- Magisk Manager-20.1.zip
- ScheduleReboot:此实用程序用于在特定时间重新引导计算机,解决了在目标时间内处于睡眠模式的计算机在唤醒后实施重新引导的问题。
- Online-Face-Recognition-and-Authentication:Hsin-Rung Chou、Jia-Hong Lee、Yi-Ming Chan 和 Chu-Song Chen,“用于人脸识别和认证的数据特定自适应阈值”,IEEE 多媒体信息处理和检索国际会议,MIPR 2019
