多核处理器上的并行程序新方法:解放ILP与功能编程
需积分: 10 187 浏览量
更新于2024-07-17
收藏 2.51MB PDF 举报
本文探讨了"计算机结构并行化程序的替代方法的研究",针对多核处理器环境下的并行编程提出了创新思路。相较于传统的操作系统API,如OpenMP和MPI,作者提出了一种新的并行化方法,这种方法更加适合现代多核处理器的架构。这种方法的核心在于并行化硬件和定制的编程风格,它特别强调了指令级并行(Instruction-Level Parallelism, ILP)的利用和控制。
作者构建了一个多核设计,每个核心被设计为支持多线程,且具备创建新线程的能力。编程模式基于函数式编程,这意味着在每次函数调用时,硬件会自动创建一个并发线程,从而释放ILP。这种设计消除了函数调用之间的体系结构依赖性和函数返回后的延迟,有助于提高性能。
文章详细介绍了如何应用此方法来优化常见的计算任务,如总和减少、矩阵乘法和排序,这些操作在并行环境下表现出了随着数据规模增加而增强的并行性。研究者还对这种方法进行了性能测量,结果显示其提供的内核数量可达数千级别,这得益于ILP随着数据增大而提升的潜力。
此外,本文对比了提出的并行化方法与pthread的并行化技术,指出以下几点优势:首先,作者的方法提供了确定性的并行执行,使得代码调试更加容易;其次,与线程管理相关的缺陷在他们的设计中得到了改进;第三,他们的并行性是隐式的,这意味着程序员无需显式地声明并行区域,这增加了代码的简洁性和可读性;最后,他们的方法不仅并行化函数,也并行化循环,进一步增强了程序的并行性能。
这项工作为在多核处理器上高效并行化程序提供了一种新颖且实用的策略,其优点包括释放ILP、易于理解和调试的隐式并行性,以及针对多核架构的优化设计。这对于优化现代嵌入式系统和其他高性能计算场景具有重要意义。
GOOSSENS ET AL. 3of15
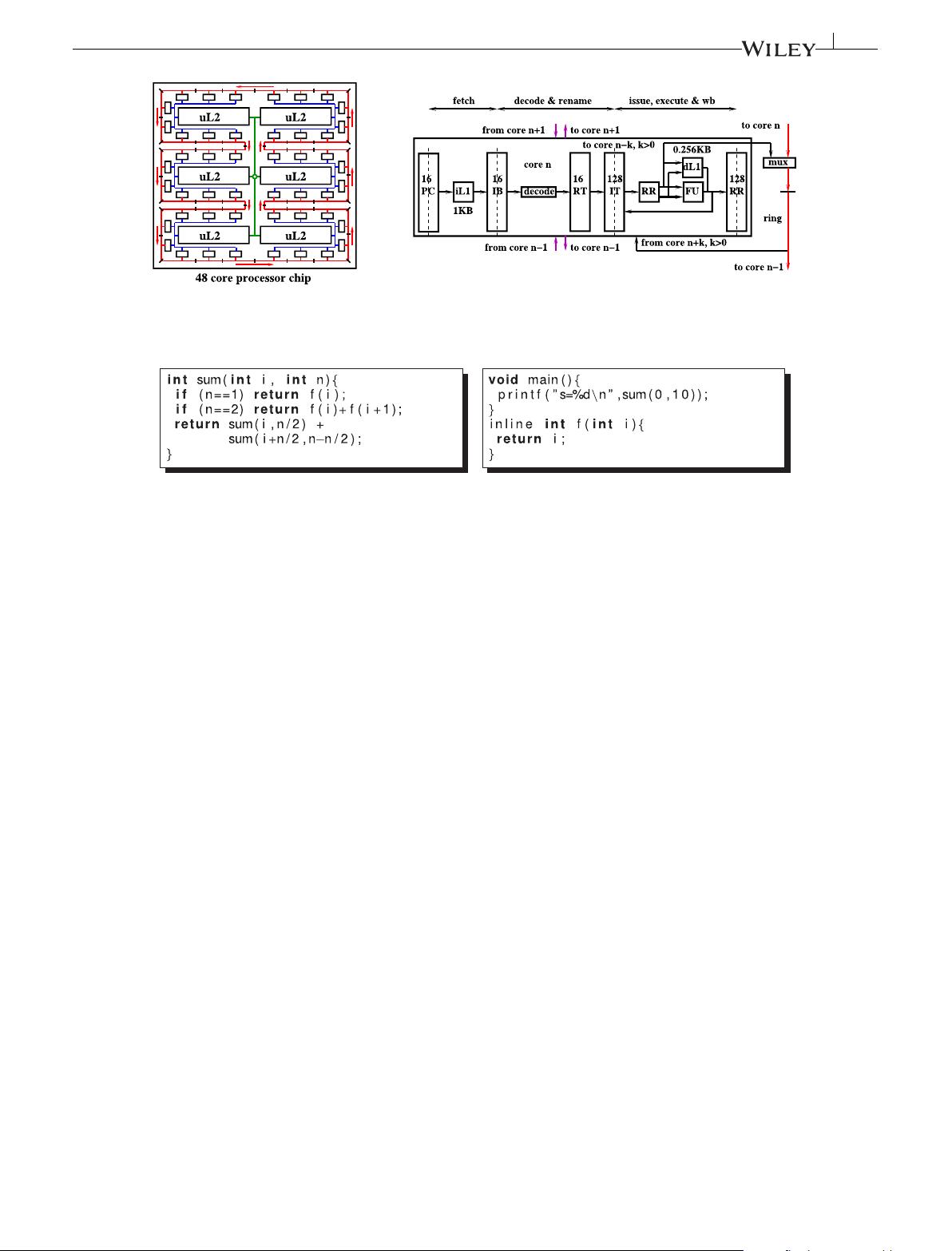
FIGURE 2 A many-core processor. dL1, data L1 cache; IB, instruction buffer; iL1, instruction L1 cache; IT, instruction table; PC, program counter;
RR, renaming registers; RT, renaming table; uL2, L2 unified cache; FU, functional unit
FIGURE 3 A sum reduction programmed in C
Once on the ring, the data moves nonstop to the destination, crossing 1
separator per cycle.
Each core hosts a set of thread slots (eg, 16 thread slots per core).
A thread is represented by its program counter (PC) and its renaming
table. The thread code is fetched from an instruction L1 cache (iL1).
The fetch stage selects one ready thread PC to fetch 1 instruction
from the iL1. The instruction is saved in the thread instruction buffer.
The decode and rename stage selects 1 full instruction buffer, and the
instruction it holds is decoded and renamed through the thread renam-
ing table. The renamed instruction is saved in the instruction table. The
issue, execute, and write back stage selects 1 ready instruction in the
instruction table, which is executed: it reads its sources from and writes
its result to the renaming registers (RR). At full speed, the processor
runs 1 instruction per cycle per core (eg, 1K instruction per cycle for a
1K-core processor).
The instruction set architecture is restricted to register-register,
control, and Input/Output (I/O) instructions. There are no
memory-access instructions. I/O instructions use a data memory hier-
archy starting from the data L1 cache (dL1). A register may be written
to an output file, at a position given by a descriptor and an offset (eg,
OUT %rdi, %rbp, %rbx: store rbx to file descriptor rdi at position rbp). A
register may also be loaded from a file descriptor and a read position
(eg,IN %rdi, %rbp, %rbx: load rbx from file descriptor rdi at position rbp).
External accesses are organized as file accesses rather than ran-
dom memory accesses to simplify memory coherency control. The
file access pattern is to synchronize a set of parallel file reads on a
matching set of parallel file writes. We replace the individual mem-
ory read-after-write (mem-RAW) dependences of each read with each
write by a unique dependence of the read phase with the write phase.
As we will see (Section 3.3), this unique dependence is a control flow
one, which is more simple to manage by hardware than memory depen-
dences. A control between a parallel read and the next parallel write
satisfies the mem-RAW dependence of each read with its matching
write.
The memory hierarchy design is out of the scope of this paper.
However, it does not have the same constraints as a traditional multi-
core shared memory hierarchy. In a traditional memory, a reader con-
sumes a data which may be produced by any thread in any core. This
implies to keep the hierarchy coherent to ensure memory consistency.
In our design, a reading thread consumes memory data coming only
from predecessor threads. We will see in this section that threads
are ordered. Hence, a writer writes to its local cache and a reader
gets its data from the closest writer. Strict consistency (a read opera-
tion always gets the data written by the most recent write operation)
is obtained without the need to invalidate prior writes. The mem-
ory write-after-read and write-after-write dependences are ensured
by a serialization from a control flow instruction, like mem-RAW
dependences.
Figure 3 is a sum reduction programmed in C and Figure 4 is its trans-
lation in
×86. The code does not use any array but a function returning
1 element (function f could return an array element read from an input
file instead of providing it itself; in the example, f
(i) returns i).
On Figure 4, the fork instruction at line 11 creates a new thread on
the successor core. The local core decoding the fork instruction allo-
cates a free thread slot in its successor. The local core initializes the
allocated thread PC when the next call instruction at line 15 is decoded.
The PC is set to the called function return address, ie, instruction at line
16. Between the fork and the call are push instructions at lines 12 to
14. A push r instruction sends its local renaming of r to the new thread
(when push r is issued, ie, r value is known). For example, the 3 push
instructions on lines 12 to 14 send RR identifiers for rdi, rsi,andrbx to
the created thread.
The call instruction sends the resume code address. Once the
new thread has received the PC value, it starts fetching. Its first
剩余14页未读,继续阅读
2022-03-13 上传
2022-07-08 上传
2023-03-13 上传
2021-10-07 上传
2022-05-28 上传
2021-10-10 上传
2021-12-03 上传
2022-06-23 上传
2021-07-12 上传

weixin_39840588
- 粉丝: 450
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
