Erlang进程中的结构化编程实践
需积分: 9 101 浏览量
更新于2024-09-15
收藏 86KB PDF 举报
"Erlang - 结构化编程利用进程"
Erlang是一种函数式编程语言,特别适合构建高并发、容错性强的分布式系统。本文档深入探讨了如何在Erlang中运用结构化编程技术,特别是通过进程来实现这一目标。作者Jay Nelson来自DuoMark International, Inc.,他提出了一系列方法,这些方法对于提高软件的可靠性和容错性具有重要意义。
首先,文档强调了强封装的重要性,这是确保代码模块化和可维护性的关键。在Erlang中,进程天然支持消息传递,从而允许各部分代码之间保持清晰的边界,减少相互依赖。这种设计能够帮助开发者创建独立、可替换的组件,进一步增强了系统的可扩展性。
其次,通过进程的分区,可以实现故障隔离。在Erlang中,如果一个进程出现错误,它不会影响到其他进程,这大大降低了系统整体崩溃的风险。此外,数据流的仪器化也是通过进程实现的,使得追踪和分析程序执行中的数据流动变得更加简单。
代码重用是提高效率和减少错误的有效手段。Erlang支持函数式编程,函数可以作为一等公民,使得代码模块可以被轻易地复用。同时,Erlang的模式匹配功能允许开发者抽象出通用的处理逻辑,以适应不同的输入情况。
接口抽象和适应是另一个重要的设计原则。Erlang的进程间通信模型鼓励开发者定义清晰的接口,即使在系统演进过程中,也能灵活地调整和适应变化的需求。
模拟输入、资源管理和分布式资源分配是Erlang进程模型的强项。开发者可以创建模拟环境来测试系统行为,而分布式资源管理则使得Erlang成为构建大规模分布式应用的理想选择。
文档中引入了归纳分解的概念,这是一种根据系统随时间动态行为来模块化代码的方法,而非静态的程序结构。这种方法促进了代码的继承、行为抽象、自动化测试、动态数据版本控制和动态代码修订。所有这些特性共同作用,提高了软件的可靠性,使其更具有容错能力。
总结来说,"Erlang - 结构化编程利用进程"这篇文档提供了一种使用Erlang进程来实现结构化编程的全面视角,展示了如何利用Erlang的独特特性和机制来设计和构建更加可靠、容错的软件系统。文档涵盖了设计工具和技术,特别是模块和接口方面的内容,对于Erlang程序员和分布式系统设计者来说是一份宝贵的参考资料。
defines the DB organization and the other module defines the
format of DB records plus the functions that access their contents.
Listing B-2 is the erlang implementation of the dbtree module. It
defines the in memory DB organization as a general-balanced tree
of records that are identified by a unique sequence number.
Listing B-4 is the xact module which defines the record format for
DB records, each representing an account transaction.
Each of these modules is a compilation unit that exposes only its
exported functions; together they represent a dynamic process unit
that exhibits the behaviour of the message protocol interface. The
joining of these three modules is created dynamically as a call to
the start_link function, passing the module name of the DB
organization as well as the module name of the DB record format.
This implementation may be replaced at runtime by naming a
different module when start_link is called. Likewise, the frame-
work can be modified without concern to the implementation or
organization of records. Mechanism is completely separate from
data structure and data organization.
The process defined above is an example of strong encapsula-
tion. The boundaries of the process space cannot be violated,
even accidentally, by any other code because the OS will prevent
it. To interact with this component of the design, an external
process must send a message to either add, update, delete, get a
single record, get the number of records, filter the records, export
them or stop the server process. All other messages will be
ignored.
The filter message is designed to create a clone of the core
memory DB, which will contain a subset of the records. This is
the technique for obtaining only the entertainment expense
records, or, given only the entertainment expenses, all entertain-
ment transactions for a week long vacation. The main DB will
have an application controller as its parent process. A subset
database will have a main DB process as its parent. A manage
process can only receive modification messages from its parent
process, thus ensuring that messages received which affect the
state of the DB can be propagated to the receiver’s children and so
on in succession, so that all dependent record subsets may be
synchronized. For example, one person could be editing the DB
while a second person requests a report. The report will be a live
clone of a subset of the main DB and will reflect any
modifications to the DB subsequent to the initiation of the report.
The design technique illustrated here is termed inductive
decomposition. It is used when a feature set of a system design
can be reduced to a series of identical processes operating on
different subsets of the data. Since the report processes reuse
code already needed by the core DB manager, the design can
reduce the amount of code needed and the number of modules
implemented, thus increasing the probability of producing a
reliable system. Other benefits may result from the code sub-
sumption illustrated: behavior abstraction, automated testing,
dynamic data versioning and dynamic code revision, while at the
same time allowing parallelism across multiple CPUs. Because
all the processes share the same interface, their behavior can be
abstracted and adapted by an external management process. The
user can control a single process that can direct its messages to
any of the dynamically created reports using the same code and
mechanism for altering their behavior. If the management process
were to read a set of test cases, apply them and verify the results,
the abstracted interface could be used for test automation. The
strong encapsulation of the process also allows for two core DB
managers to be co-resident, each with a different data version
module, for example two versions of the xact record formats.
Each report or record subset created will retain the characteristics
and data version of its parent process, while at the same time the
behavior abstraction will be consistent so any automated testing
tools or user control process can simultaneously interact with
either version of data. In the same manner, a particular version of
software running in a single process can load a replacement
version and continue without disrupting the system, provided the
message interface does not change. In Ericsson’s full
implementation for a non-stop environment [1], this latter
restriction is lifted by introducing system messages which notify
processes prior to a code change.
3.2. Abstracted and Adapted Interfaces;
Transformers
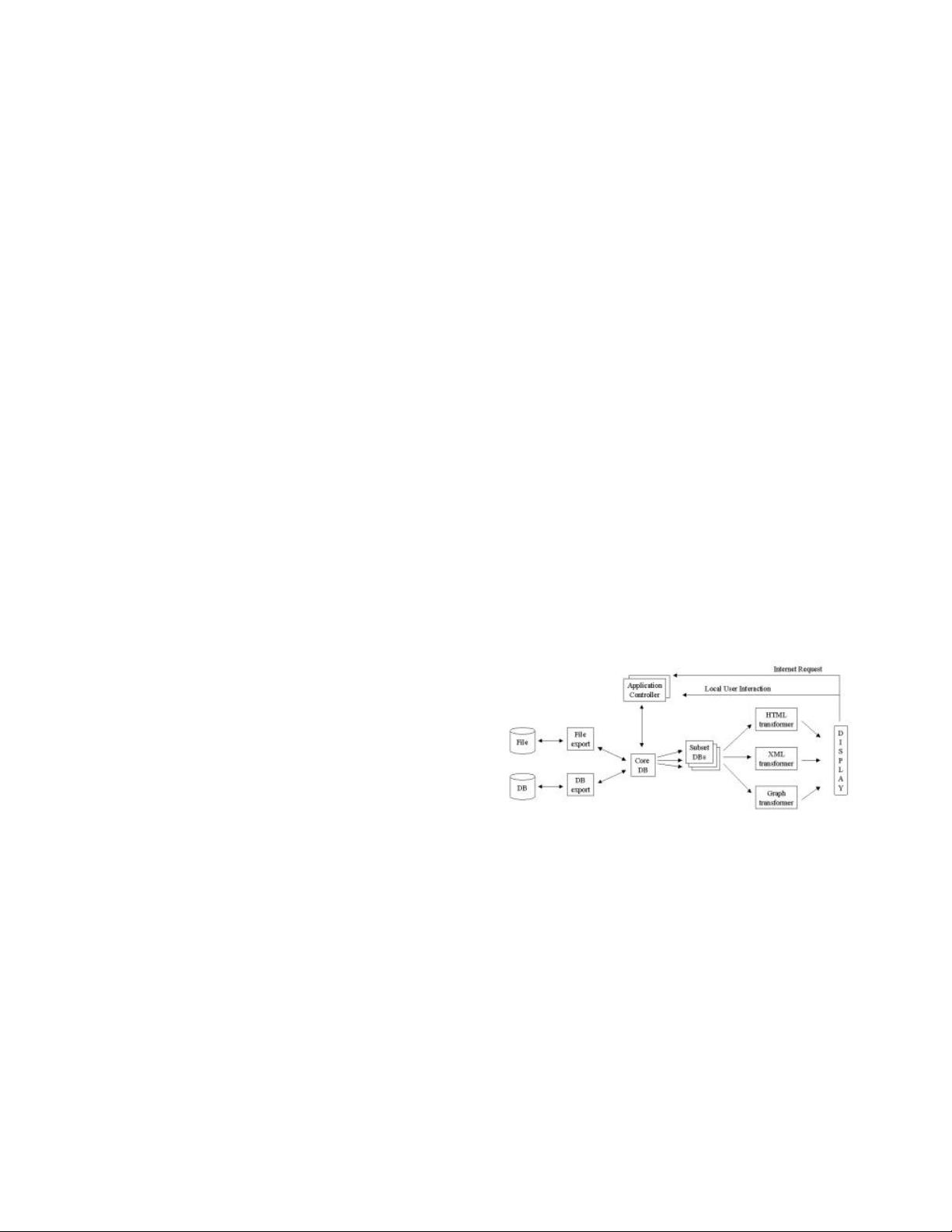
Figure 1 diagrams the full design with the inductively derived
core DB and subset DB processes shown in the middle. Consider
next the export function provided by the xact module. Instead of
generating a report, it formats a record as a binary. The DB
servers export records as a list of binaries, sending the list to the
calling process. Because strong encapsulation requires the
transmission of data from one process to another, each is free to
store it in the format most advantageous for the process’ own
purposes. The OOPL approach is to add interface methods to the
xact object to export in the proper format, or adaptors to transform
the internal data structure to the desired output format. The COPL
approach introduces a transformer process which can be used as
an abstracted interface to avoid unnecessary code growth in the
xact module. It also adds runtime flexibility in the conversion of
export data to target formats.
Figure 1. Personal Accounting Application design diagram
One export transformer per DB process can maintain a current
reflection of each of the core DB or subset DB processes, or
multiple can exist per subset DB if snapshot views prior to recent
DB modifications need to be maintained. In any case, the exported
data can be adapted to output an HTML report, raw ASCII text or
even a graph through the introduction of transformer processes
which generate the desired output data and pass them to the
requesting process. A single export process can catch the
exported data records and then deliver them to any number of
requesting processes by replacing or extracting bytes much as
UNIX character stream tools such as awk or sed work [7].
The problem description calls for both a file for storage of
剩余10页未读,继续阅读
2020-08-27 上传
2019-12-08 上传
2020-08-27 上传
2023-06-16 上传
2022-09-14 上传
2021-02-04 上传
2009-06-08 上传
2021-06-18 上传
2021-06-29 上传

hkx1n
- 粉丝: 119
- 资源: 208
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
