尚硅谷Kafka教程:大数据实时处理中的消息队列
"尚硅谷大数据技术之Kafka安装及使用文档,涵盖了Kafka与Kafka-Eagle的内容,适合学习Kafka基础及实践操作"
在大数据处理领域,Kafka作为一个分布式的消息队列,扮演着至关重要的角色。其核心设计是基于发布/订阅模式,主要应用于实时数据流处理和构建实时数据管道。Kafka由Apache软件基金会开发,以其高吞吐量、低延迟和容错性而备受青睐。
1. Kafka概述:
Kafka是一个高性能、可扩展的开源消息系统,它支持实时数据流处理,能够处理大量的实时数据。Kafka作为一个消息中间件,它将数据以日志的形式持久化到磁盘,并且通过分区和复制策略提供高可用性和容错性。
2. 消息队列的应用场景:
- **同步处理**:在传统的系统中,业务流程通常是串行的,如用户注册流程,每个步骤紧密相连,影响整体效率。
- **异步处理**:引入消息队列后,可以实现解耦和异步化,如注册信息先写入数据库,再将发送短信的请求放入消息队列,这样即使短信服务暂时无法响应,也不会影响用户注册的流程。消息队列提供了以下好处:
- **解耦**:生产者和消费者之间无需直接交互,降低了系统的耦合度。
- **可恢复性**:消息持久化,使得系统在部分组件故障后仍能恢复未处理的消息。
- **缓冲**:平衡生产者和消费者的处理速度,避免因流量波动导致系统压力过大。
- **灵活性和峰值处理能力**:应对突发流量,保证系统稳定运行。
- **异步通信**:消息可以延迟处理,提高系统响应速度。
3. 消息队列的模式:
- **点对点模式**:在该模式中,每个消息只有一个消费者,消费者从队列中获取并消费消息后,消息会被从队列中移除,保证每个消息只被消费一次。
Kafka-Eagle是针对Kafka的监控和管理工具,它提供了直观的Web界面,用于监控Kafka集群的性能指标、进行主题管理以及提供报警功能,大大简化了Kafka的运维工作。
通过尚硅谷提供的大数据技术之Kafka文档,读者可以深入了解Kafka的安装、配置、使用以及与Kafka-Eagle的集成,从而更好地掌握大数据实时处理的核心技术。在实际应用中,理解并掌握这些知识点对于提升大数据处理系统的效能和稳定性至关重要。
尚硅谷大数据技术之 Kafka
—————————————————————————————
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --topic first
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic first
--from-beginning:会把主题中以往所有的数据都读取出来。
6)查看某个 Topic 的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper
hadoop102:2181 --describe --topic first
7)修改分区数
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper
hadoop102:2181 --alter --topic first --partitions 6
第 3 章 Kafka 架构深入
3.1 Kafka 工作流程及文件存储机制
Kafka 工作流程
Producer
Kafka cluster
broker0
broker1
broker2
TopicA-partition0-leader
TopicA-partition1-leader
TopicA-partition2-leader
TopicA-partition1-follower
TopicA-partition2-follower
TopicA-partition0-follower
0
1
2
3
4
5
0
1
2
3
0
1
2
3
4
0
1
2
3
0
1
2
3
4
5
0
1
2
3
4
Consumer
Consumer
Consumer
group
Zookeeper
offset
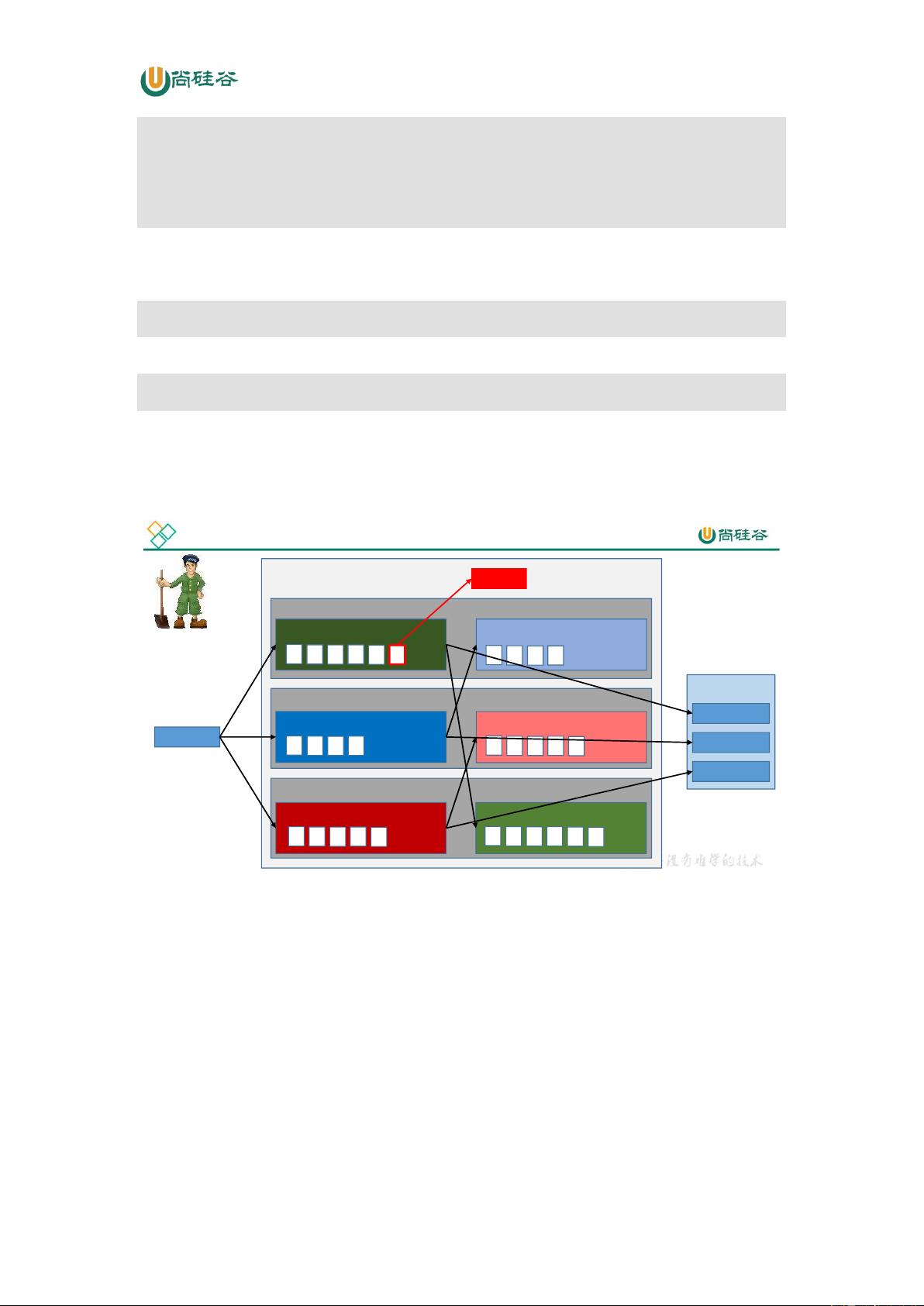
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic
的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文
件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该
log 文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己
消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
剩余35页未读,继续阅读
2019-05-28 上传
2022-08-04 上传
2019-09-15 上传
107 浏览量
2021-06-29 上传
2022-08-08 上传
2020-07-30 上传

东纪元
- 粉丝: 2777
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
