CentOS6.4单机伪分布式安装Hadoop2.6教程
需积分: 36 123 浏览量
更新于2024-07-17
收藏 2.48MB PDF 举报
"这篇Hadoop安装教程主要针对在CentOS6.4系统上进行Hadoop 2.6.0的单机或伪分布式配置。教程由厦门大学数据库实验室出品,适用于Hadoop 2.7.1及2.6.0等版本。教程详细介绍了每个步骤,并提供了官方安装教程的链接作为参考,旨在帮助用户在CentOS环境中顺利安装和运行Hadoop。"
正文:
在学习和使用Hadoop之前,了解其基本概念是必要的。Hadoop是一个开源的分布式计算框架,由Apache基金会维护,主要用于处理和存储大量数据。它基于Google的MapReduce编程模型和GFS文件系统模型,设计目标是高容错性、高可扩展性和高吞吐量。
本教程中提到的"单机模式"是指在一台机器上模拟Hadoop集群的所有组件,仅用于测试和学习,不涉及真正的分布式计算。而"伪分布式模式"则是在单台机器上运行所有Hadoop服务,但每个服务都运行在不同的Java进程中,模拟了分布式环境,可以进行更真实的测试和性能分析。
在安装Hadoop前,首先需要准备一个CentOS6.4的系统环境。由于教程中提及的是32位系统,但推荐使用64位系统,因为64位系统通常能提供更好的性能。安装CentOS后,需要确保系统已经更新到最新,并安装了Java开发环境(JDK),因为Hadoop运行需要Java支持。
接下来,以下是安装Hadoop的一般步骤:
1. 下载Hadoop二进制包:访问Apache官方网站下载对应版本的Hadoop,如Hadoop 2.6.0。
2. 解压并移动到指定目录:通常将Hadoop解压到 `/usr/local` 目录下,并重命名目录为 `hadoop`。
3. 配置环境变量:在 `~/.bashrc` 或 `~/.bash_profile` 文件中添加Hadoop的环境变量,包括 `HADOOP_HOME` 和 `PATH`。
4. 配置Hadoop的配置文件:修改 `etc/hadoop` 目录下的 `core-site.xml`,`hdfs-site.xml` 和 `mapred-site.xml` 文件,设定HDFS和MapReduce的相关参数。例如,`hdfs.defaultFS` 指定HDFS的名称节点,`mapreduce.framework.name` 设置MapReduce的运行模式(本地或YARN)。
5. 初始化HDFS:在伪分布式模式下,需要格式化NameNode,这会创建HDFS的元数据。
6. 启动Hadoop服务:通过执行 `start-dfs.sh` 和 `start-yarn.sh` 命令启动Hadoop的相关服务。
7. 验证安装:通过Web界面或命令行工具检查Hadoop是否正常运行,如使用 `jps` 查看各个守护进程是否运行,或访问NameNode的Web UI(默认端口50070)。
8. 测试Hadoop:可以编写简单的MapReduce程序进行测试,如WordCount,以验证Hadoop集群的正确性。
在配置过程中,可能会遇到各种问题,如权限问题、Java环境问题或网络配置问题等,解决这些问题需要对Linux系统和Hadoop有一定理解。遵循教程中的步骤,结合官方文档,一般能够成功配置和运行Hadoop。
这个Hadoop安装教程提供了一条清晰的路径,让初学者能够在CentOS环境中搭建Hadoop环境,从而进一步学习和实践大数据处理技术。对于那些希望深入了解Hadoop分布式计算和大数据处理的人来说,这是一个很好的起点。
2016/1/8
Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0_给力星
http://www.powerxing.com/install-hadoop-in-centos/ 5/23
.
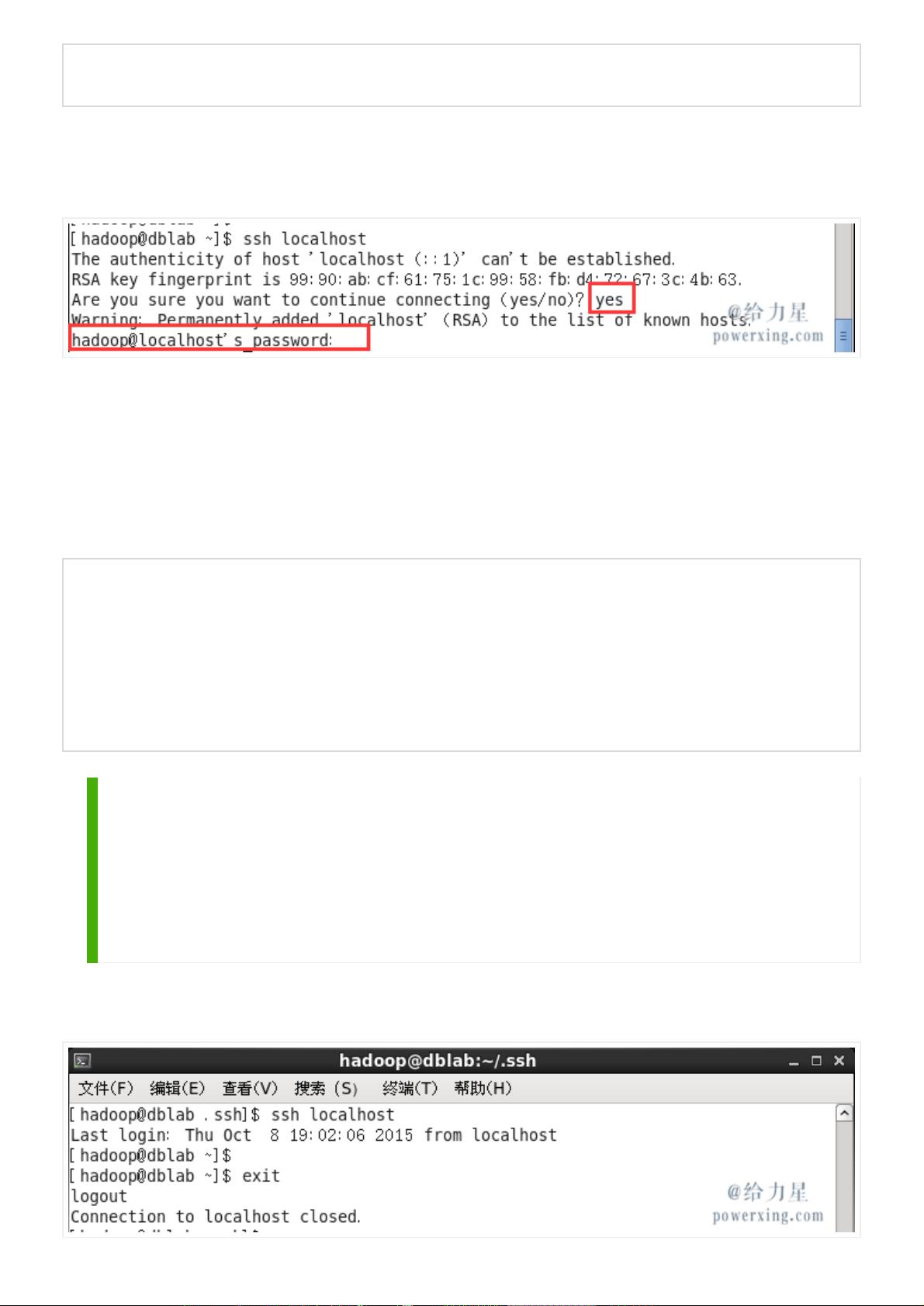
$ ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就
登陆到本机了。
测试SSH是否可用
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先输入
exit
退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生
成密钥,并将密钥加入到授权中:
.
$ exit #
退出刚才的
ssh localhost
.
$ cd ~/.ssh/ #
若没有该目录,请先执行一次
ssh loc
alhost
.
$ ssh-keygen -t rsa #
会有提示,都按回车就可以
.
$ cat id_rsa.pub >> authorized_keys #
加入授权
.
$ chmod 600 ./authorized_keys #
修改文件权限
~的含义
在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你
的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 后面的文
字是注释。
此时再用
ssh localhost
命令,无需输入密码就可以直接登陆了,如下图所示。
剩余22页未读,继续阅读
2020-03-02 上传
2018-04-08 上传
2022-08-03 上传
2022-08-03 上传
2017-11-01 上传
2024-09-20 上传
2022-09-24 上传
2024-06-21 上传

kamore
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- docsify-blog:docsify文档网站
- 大数据时代的数据中台
- Python库 | msdlib-0.0.3.10.tar.gz
- Movie Central Lobby:sid的MovieCentral具有附加功能-开源
- subway-svg-tools:地铁线路图 SVG 解析工具
- WEB API 接口签名验证入门与实战课程
- task-day-8
- RLAlgsInMDPs.zip
- 安全交易:您的在线购物顾问-crx插件
- 安装和配置 System Center 2016 Operations Manager
- typing-speed-test
- 51单片机Proteus仿真实例 T0控制LED实现二进制计数
- SIT210_Task-4.2HD
- wxFacecup:俄罗斯2018年世界杯微信小程序
- 实现图片与PDF文件切换显示
- react-gifexpertapp05:AplicaciónRe3act de API GIF
