"大数据框架安装部署与实验详解"
需积分: 6 116 浏览量
更新于2023-12-25
收藏 3.56MB PDF 举报
本文主要介绍了BigData大数据涉及到的各个框架的安装部署和实验。文档中详细记录了大数据涉及到的各个框架(Java、Hadoop、ZooKeeper、Spark、Scala)的安装部署和实验步骤,从0到1的搭建过程,同时包括了各个框架的集成实验的详细记录。
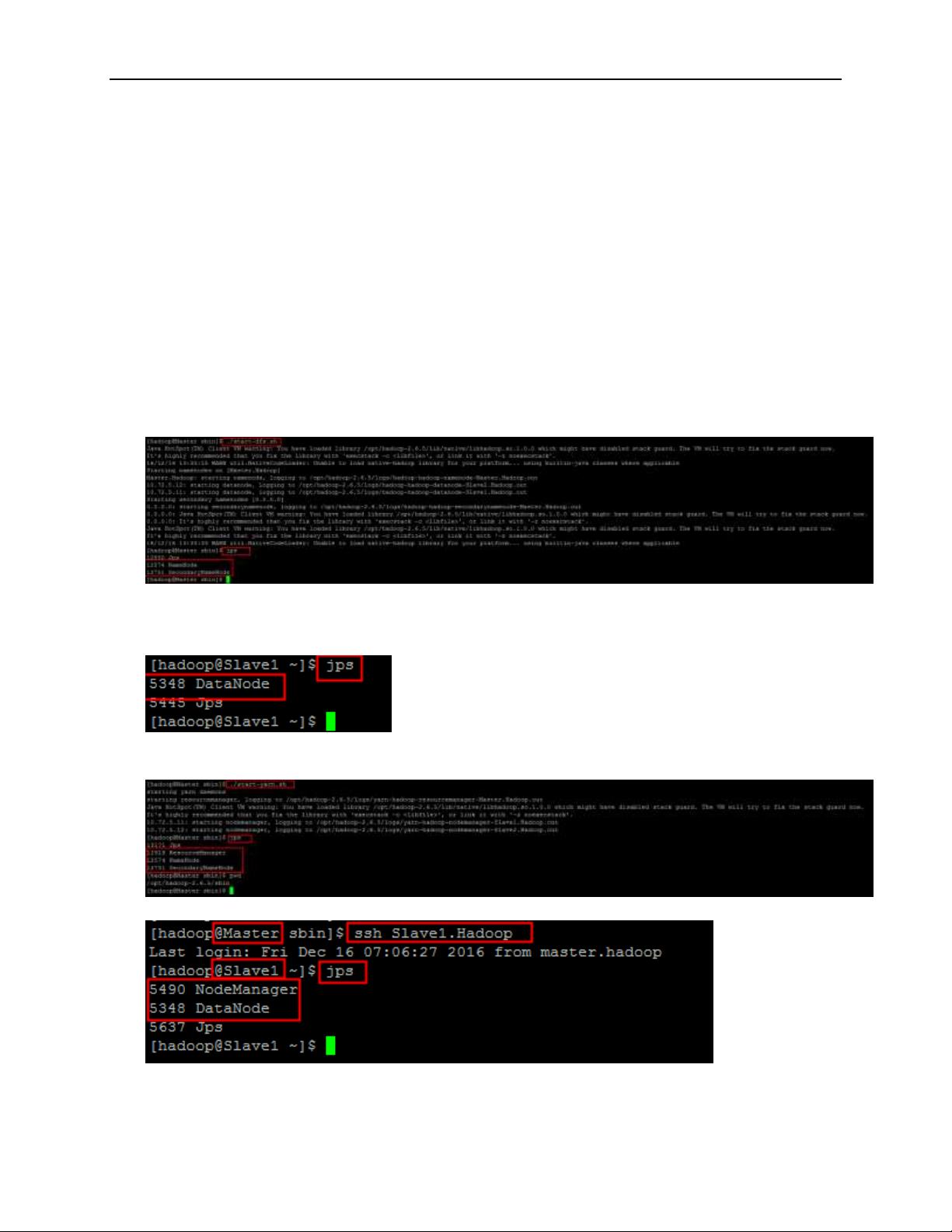
在实际操作中,本文提供了每个框架的安装目录,以及相应的Shell命令用于启动和部署。例如,Java的安装目录为/opt/jdk1.8.0_161,Hadoop的安装目录为/opt/hadoop-2.6.5,启动Hadoop集群的命令包括start-all.sh、start-dfs.sh和start-yarn.sh,ZooKeeper的安装目录为/opt/zookeeper-3.4.5,启动ZooKeeper的命令为zkServer.sh,Spark的安装目录为/opt/spark-2.2.0-bin-hadoop2.6,启动Spark集群的命令包括start-all.sh、start-master.sh和start-slaves.sh。此外,还提到了Scala的安装和使用。
在这些框架的安装部署和实验过程中,作者详细记录了每一步骤,包括所需软件的下载和安装、配置文件的修改、环境变量的设置、以及各个命令的执行结果。通过这些记录,读者可以清晰地了解各个框架的搭建和集成实验过程,从而更好地掌握BigData大数据相关的知识和技能。
总的来说,本文是一份非常实用的大数据框架安装部署和实验指南,对于希望学习和掌握BigData大数据技术的人来说,具有很高的参考价值。此外,也可以作为IT认证课程学习的辅助材料,帮助学员更好地理解和掌握相关知识。如果需要了解更多的IT认证课程,请访问美河学习在线www.eimhe.com,获取更多信息。
在这个时代,随着大数据技术的不断发展和应用,掌握和应用大数据相关的框架成为了很多人的追求。因此,这篇文档提供的实际操作过程和实验记录,对于希望深入学习BigData大数据相关技术的人来说,具有非常重要的参考价值。
总的来说,本文详细记录了BigData大数据涉及到的各个框架的安装部署和实验过程,包括Java、Hadoop、ZooKeeper、Spark、Scala等框架,通过这些记录可以帮助读者更好地了解和掌握相关知识和技能。同时,也可以作为IT认证课程学习的辅助材料,帮助学员更好地理解和掌握相关知识。

更多 IT 认证课程请访问 美河学习在线 www.eimhe.com
export JAVA_HOME=/usr/java/jdk1.6.0_14ll
7.2.2 配置 core-site.xml 文件
1. 在/usr/hadoop-1.0.0/创建 tmp 文件夹
mkdir /usr/hadoop-1.0.0/tmp
vi /usr/hadoop-1.0.0/conf/hadoop-env.sh/core-site.xml
修改 Hadoop 核心配置文件 core-site.xml,这里配置的是 HDFS 的地址和端口号。
该文件中添加如下代码:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
(备注:请先在 /usr/hadoop-1.0.0 目录下建立 tmp 文件夹)
<value>/usr/hadoop-1.0.0/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://10.69.16.166:9000</value>
</property>
</configuration>
7.2.3 配置 hdfs-site.xml 文件
修改 Hadoop 中 HDFS 的配置,配置的备份方式默认为 3。
vi /usr/hadoop-1.0.0/conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
(备注:replication 是数据副本数量,默认为 3,salve 少于 3 台就会报
错)
</property>
<configuration>
7.2.4 配置 mapred-site.xml 文件
修改 Hadoop 中 MapReduce 的配置文件,配置的是 JobTracker 的地址和端口。
<configuration>
<property>
<name>mapred.job.tracker</name>



剩余109页未读,继续阅读
2019-01-13 上传
2021-05-13 上传
2021-04-27 上传
2021-08-05 上传
2021-05-16 上传
2012-02-27 上传
2020-06-28 上传
2021-10-31 上传
2021-02-03 上传

worthcvt
- 粉丝: 91
- 资源: 407
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
