机器学习实验:KNN与多项式分类器实现与优化
需积分: 0 195 浏览量
更新于2024-08-05
收藏 471KB PDF 举报
"该实验是关于机器学习中的KNN(K-近邻)算法和多项式分类器的设计与应用,主要使用Python或C/C++语言进行实现。实验目的是理解这两种分类器的工作原理,能独立设计并评估其准确性。实验内容包括计算未知实例与已知实例的距离、选择合适的K值以及应用多数表决规则进行分类。此外,还涉及距离衡量方法(如欧氏距离和曼哈顿距离)以及K值选择对分类结果的影响。实验将使用sklearn库中的Iris数据集进行实践操作。"
在这个实验中,KNN算法是核心内容,它是一种基于实例的学习方法,无需对数据进行模型训练,而是通过查找最近邻来预测新样本的类别。以下是KNN算法的详细解释:
1. **计算距离**:KNN算法首先计算新样本与训练集中的每个样本之间的距离。常用的距离度量方法有欧氏距离和曼哈顿距离。欧氏距离是两点之间直线距离的平方和,而曼哈顿距离是各维度差的绝对值之和。
2. **选择K值**:K值代表了选取的最近邻的数量,它的大小直接影响分类结果。较小的K值更容易受噪声影响,而较大的K值可以降低噪声,但可能使类别边界模糊。通常,K值选择在2到20之间。
3. **多数表决规则**:在选择了K个最近邻后,通过统计这些邻近样本的类别出现次数,选择出现次数最多的类别作为新样本的预测类别。
实验中提到的多项式分类器通常是指在特征空间上构建多项式模型,如逻辑回归、支持向量机等,用于非线性分类任务。这部分并未给出详细步骤,但在实际应用中,多项式分类器会先对原始特征进行转换,生成高维特征空间,使得原本难以分隔的数据在新空间中变得易于处理。
在实验实践中,会使用Iris数据集,这是一个经典的多分类问题,包含鸢尾花的多个特征,如花瓣长度、宽度等,以及对应的三个类别。通过加载sklearn.datasets库中的Iris数据集,可以快速进行分类器的训练和测试。
这个实验旨在通过理论与实践相结合的方式,帮助学生深入理解KNN算法和多项式分类器的工作机制,并掌握评估分类器性能的方法。同时,实验也强调了K值选择的重要性以及距离度量的灵活性,这些都是在实际应用中调整和优化模型的关键因素。
《机器学习》实验讲义
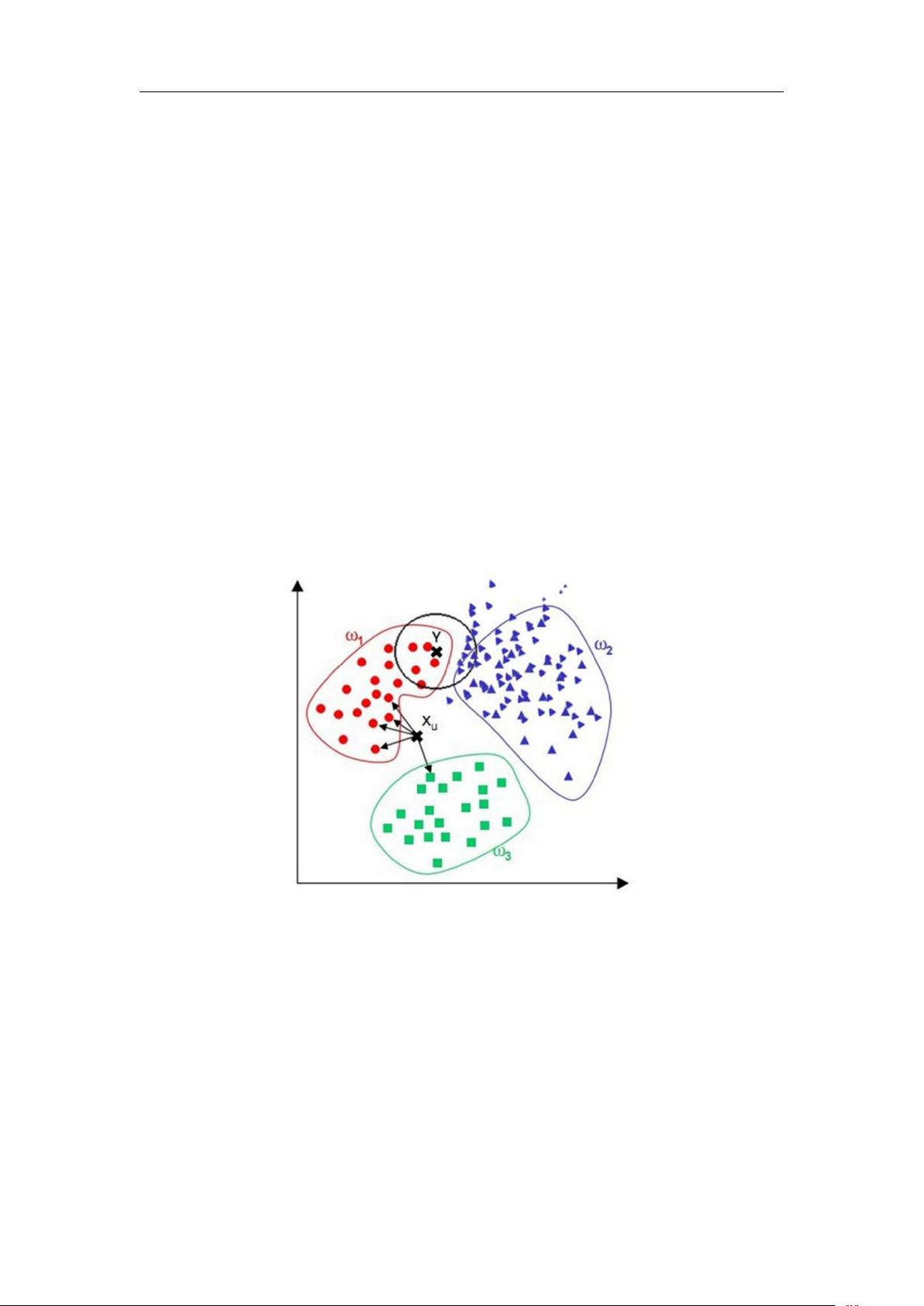
图中的数据集都打好了 label ,一类是蓝色正方形,一类是红色三角形,绿色
圆形是待分类的数据。
K = 3 时,范围内红色三角形多,这个待分类点属于红色三角形。
K = 5 时,范围内蓝色正方形多,这个待分类点属于蓝色正方形。
如何选择一个最佳的 K 值取决于数据。一般,较大 K 值能减小噪声的影响,但
会使类别之间的界限变得模糊。因此 K 的取值一般比较小 ( K < 20 )。
改进:
在点 Y 的预测中,范围内三角形类数量占优,因此将 Y 点归为三角形。但
从视觉上观测,分为圆形类更合理。根据这种情况,可以在距离测量中加入权重,
如 1/d (d: 距离)。
三、实验步骤:
剩余11页未读,继续阅读
162 浏览量
143 浏览量
2023-10-25 上传
2020-05-04 上传
2022-07-15 上传
2014-03-03 上传
2021-09-30 上传
2010-04-23 上传
2010-05-04 上传

天使的梦魇
- 粉丝: 39
- 资源: 321
 我的内容管理
展开
我的内容管理
展开







