深度学习图像分类优化策略:提升ResNet性能
需积分: 0 98 浏览量
更新于2024-08-30
1
收藏 481KB PDF 举报
"图像分类调参技巧-李沐.pdf"
在深度学习领域,特别是图像分类任务中,模型性能的提升往往离不开训练过程中的优化策略和细微调整。这些所谓的"调参技巧"虽然看似微不足道,但集合起来却能显著提高模型的准确率,而不会大幅增加计算复杂度。论文《Bag of Tricks for Image Classification with Convolutional Neural Networks》就深入探讨了这些技巧,并在ResNet-50等不同网络架构上进行了实验验证。
首先,数据增强(Data Augmentation)是提高模型泛化能力的关键一环。通过对训练集进行随机翻转、裁剪、颜色扰动等操作,可以模拟真实世界中的多样性和不确定性,使模型在未见过的数据上表现更优。此外,混合采样(MixUp)和CutMix等新型数据增强技术也得到了广泛应用,它们通过混合不同样本的特征来引导模型学习更平滑的决策边界。
其次,优化方法的选择和调整也是关键。例如,动量SGD(Momentum SGD)和Adam等优化器能够加速收敛并减少震荡。学习率调度(Learning Rate Schedule)也是必不可少的,如步降法(Step Decay)、指数衰减(Exponential Decay)以及 cosine annealing 等,能够根据训练进程动态调整学习率,帮助模型在训练后期稳定地微调权重。
再者,模型结构的微调也能带来显著效果。例如,调整卷积层的步长(stride)可以改变特征图的尺寸,进而影响模型的表达能力。同时,Batch Normalization 层的位置、残差块的设计(如 SE Block)以及模型的深度和宽度比例(如 ResNeXt)都能影响模型性能。
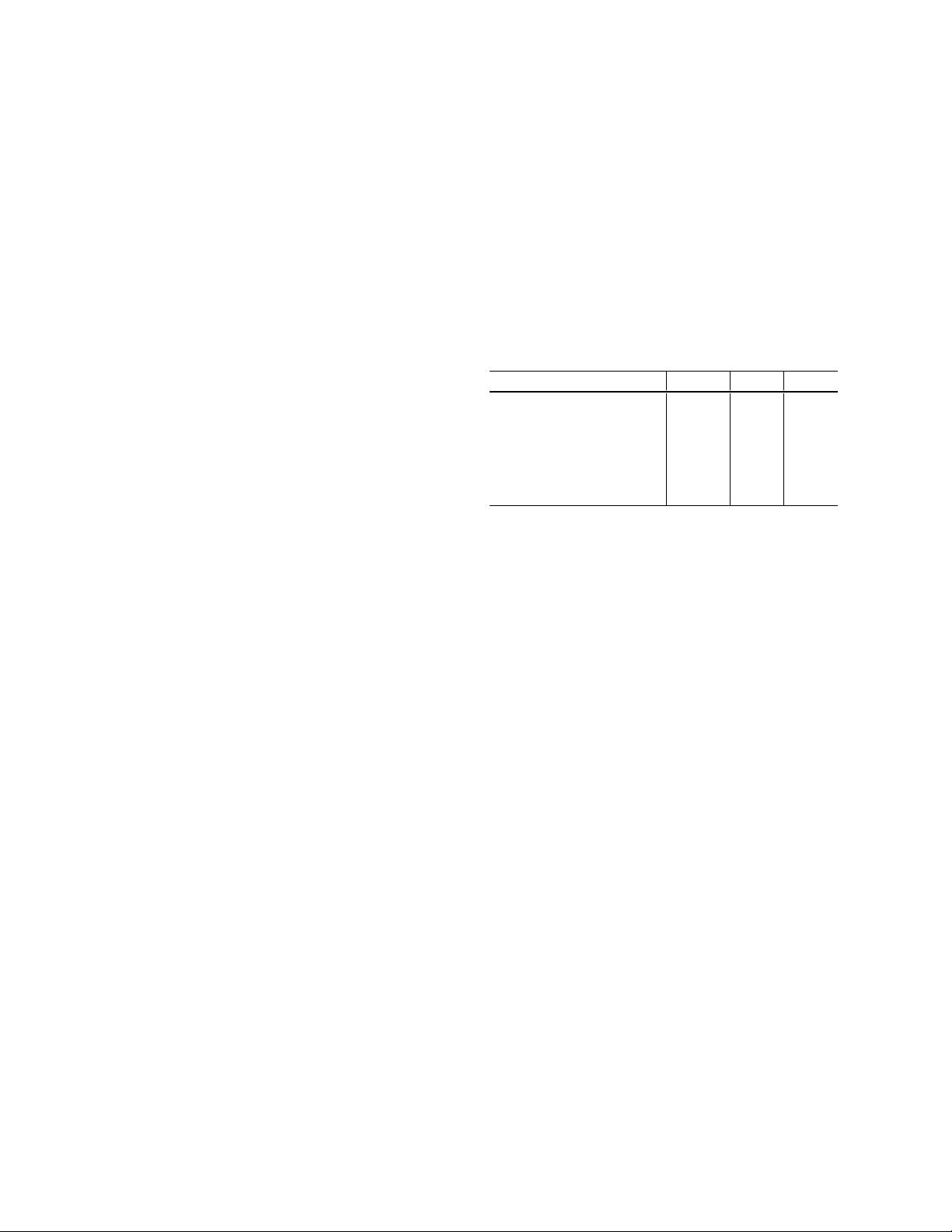
表1展示了应用这些调参技巧后的ResNet-50与其他模型在FLOPs(浮点运算次数)和验证准确率上的对比。尽管ResNet-50的计算复杂度与ResNeXt-50等新架构相当,但在应用了调参技巧后,其准确率反而超过了其他新设计的模型,证明了调参的重要性。
此外,论文还强调了模型正则化(如权重衰减、Dropout)和损失函数(如Label Smoothing)对提高模型稳定性和防止过拟合的作用。最后,作者们将这些技巧应用于多个网络架构和数据集,全面评估了它们对最终模型准确性的贡献,进一步证实了调参在深度学习实践中的价值。
图像分类领域的进步不仅依赖于新颖的网络架构设计,更在于训练过程中的微调和优化策略。通过细致入微的调参,即使相对简单的模型也能实现优秀性能,这为实际应用提供了更具性价比的选择。
Bag of Tricks for Image Classification with Convolutional Neural Networks
Tong He Zhi Zhang Hang Zhang Zhongyue Zhang Junyuan Xie Mu Li
Amazon Web Services
{htong,zhiz,hzaws,zhongyue,junyuanx,mli}@amazon.com
Model FLOPs top-1 top-5
ResNet-50 [9] 3.9 G 75.3 92.2
ResNeXt-50 [27] 4.2 G 77.8 -
SE-ResNet-50 [12] 3.9 G 76.71 93.38
SE-ResNeXt-50 [12] 4.3 G 78.90 94.51
DenseNet-201 [13] 4.3 G 77.42 93.66
ResNet-50 + tricks (ours) 4.3 G 79.29 94.63
Table 1: Computational costs and validation accuracy of
various models. ResNet, trained with our “tricks”, is able
to outperform newer and improved architectures trained
with standard pipeline.
procedure and model architecture refinements that improve
model accuracy but barely change computational complex-
ity. Many of them are minor “tricks” like modifying the
stride size of a particular convolution layer or adjusting
learning rate schedule. Collectively, however, they make a
big difference. We will evaluate them on multiple network
architectures and datasets and report their impact to the final
model accuracy.
Our empirical evaluation shows that several tricks lead
to significant accuracy improvement and combining them
together can further boost the model accuracy. We com-
pare ResNet-50, after applying all tricks, to other related
networks in Table 1. Note that these tricks raises ResNet-
50’s top-1 validation accuracy from 75.3% to 79.29% on
ImageNet. It also outperforms other newer and improved
network architectures, such as SE-ResNeXt-50. In addi-
tion, we show that our approach can generalize to other net-
works (Inception V3 [1] and MobileNet [11]) and datasets
(Place365 [32]). We further show that models trained with
our tricks bring better transfer learning performance in other
application domains such as object detection and semantic
segmentation.
Paper Outline. We first set up a baseline training proce-
dure in Section 2, and then discuss several tricks that are
1
arXiv:1812.01187v2 [cs.CV] 5 Dec 2018
In
this
paper,
we
will
examine
a
collection
of
training
tation
details
while
others
can
only
be
found
in
source
code.
literature,
most
were
only
briefly
mentioned
as
implemen-
past
years,
but
has
received
relatively
less
attention.
In
the
large
number
of
such
refinements
has
been
proposed
in
the
ing,
and
optimization
methods
also
played
a
major
role.
A
ments,
including
changes
in
loss
functions,
data
preprocess-
improved
model
architecture.
Training
procedure
refine-
However,
these
advancements
did
not
solely
come
from
from
62.5%
(AlexNet)
to
82.7%
(NASNet-A).
top-1
validation
accuracy
on
ImageNet
[23]
has
been
raised
trend
of
model
accuracy
improvement.
For
example,
the
NASNet
[34].
At
the
same
time,
we
have
seen
a
steady
NiN
[16],
Inception
[1],
ResNet
[9],
DenseNet
[13],
and
tures
have
been
proposed
since
then,
including
VGG
[24],
ing
approach
for
image
classification.
Various
new
architec-
convolutional
neural
networks
have
become
the
dominat-
Since
the
introduction
of
AlexNet
[15]
in
2012,
deep
1.
Introduction
as
object
detection
and
semantic
segmentation.
learning
performance
in
other
ap-
plication
domains
such
on
image
classification
accuracy
leads
to
better
transfer
ImageNet.
We
will
also
demon-strate
that
improvement
top-1
validation
accuracyfrom75.3%
to
79.29%
on
models
significantly.
Forexample,
we
raise
ResNet-50’s
refinements
together,
weare
ableto
improve
various
CNN
ablation
study.
Wewill
show
that,
by
combining
these
evaluate
their
im-pact
on
the
final
model
accuracy
through
examine
a
collec-tion
of
suchrefinements
and
empirically
details
or
only
vis-ible
in
source
code.
Inthis
paper,
we
will
refinements
are
ei-ther
briefly
mentioned
as
implementation
optimizationmethods.
In
the
literature,
however,
most
refinements,such
as
changes
in
data
augmentations
and
classificationresearch
can
be
credited
to
trainingprocedure
Much
of
the
recent
progress
made
in
image
Abstract
下载后可阅读完整内容,剩余9页未读,立即下载
2023-08-30 上传
2020-03-06 上传
2021-08-30 上传
2019-11-09 上传
2020-04-01 上传
2021-09-11 上传

DeepLearning小舟
- 粉丝: 2387
- 资源: 57
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
