"基于大数据技术的岗位和求职者画像设计:爬虫收集与分析挖掘"
 已收录资源合集
已收录资源合集
需积分: 0 91 浏览量
更新于2024-01-28
8
收藏 2.73MB PDF 举报
基于大数据技术的岗位画像和求职者画像设计项目旨在通过爬虫技术对网站上的求职信息进行收集,借助大数据平台进行数据分析和挖掘,以帮助求职者更好地了解市场需求,明确自己的求职方向。大数据技术的兴起源于互联网行业的快速发展和计算机硬件、软件能力的持续提升。如今,大数据技术已被广泛应用于各个行业,而在招聘求职领域,运用爬虫技术、文本挖掘、统计分析等手段进行求职信息的收集和分析,有望为求职者提供更加准确的岗位需求和就业趋势的信息。
本项目的核心目标是通过大数据技术为求职者提供更准确的信息,帮助他们更好地了解市场需求,并为自己的求职目标做出明晰的规划。在这个项目中,我们将深入研究大数据技术在招聘求职领域中的应用,利用爬虫技术对网站上的求职信息进行抓取,并通过文本挖掘和统计分析等方法,生成岗位画像和求职者画像。通过这些画像,求职者可以更直观地了解市场需求和自身在就业市场中的竞争力,有针对性地调整自己的求职策略,提高就业成功率。
在实施这一项目的过程中,我们将利用多种技术手段,包括网络爬虫、数据清洗、数据挖掘、文本分析和可视化等,来处理网上收集的求职信息数据。通过这些技术手段,我们能够将原始数据转化为可视化的岗位需求图表和求职者画像,为求职者提供更加直观、精准的信息支持。此外,我们还将借助大数据平台的强大计算和存储能力,对海量数据进行高效处理和分析,为求职者提供及时、全面的就业市场信息。
除了为求职者提供信息支持,本项目还将为用人单位提供人才需求分析和预测服务。通过对招聘信息的分析,我们将为企业提供更加深入的人才市场信息,帮助他们更准确地把握人才供需关系,优化招聘策略,提高招聘效率。
最后,本项目将通过与用人单位、求职者的深入交流,不断优化和完善大数据平台的功能和服务,提升求职信息的准确性和前瞻性,使其成为求职者和用人单位获取就业市场信息和人才资源的重要平台,为推动就业市场的稳定和发展发挥重要作用。同时,也将不断探索大数据技术在其他领域的应用,为各行业提供更加精准、高效的数据支持。
总之,基于大数据技术的岗位画像和求职者画像设计项目将充分发挥大数据技术的优势,为求职者和用人单位提供更加精准、全面的就业市场信息支持,促进人才与岗位的精准匹配,推动就业市场的健康发展。通过这一项目,我们有信心为社会和经济发展做出更大的贡献。
列表,之后的 parse 函数就会从 start_urls 的队列中取出 url 进行访问并且获取相关信息,
并解析。
在 parse 方法中,可以利用正则表达式、xpath、beautifulsoup 等等解析网页的方法进
行解析(可以混合使用),知道获取到我们所要找的信息,利用 yield 函数返回 item 就可
以了。所以此项目是在这个基础上进行复杂化,但是基本原理没有变化,唯独要注意的
是,在解析网页的时候,由于每一个网页的网页结构不一样,所以一个网站的解析方法只
能试用与该网页,其余网页不可以。在每一个网页解析过程中,同一网站中相同的网页可
能有不同的结构,所以需要多次与长期调试代码来尽可能适应所有页面。
2.2.2、scrapyd-redis 实现分布式爬虫(宋剑波 高伟)
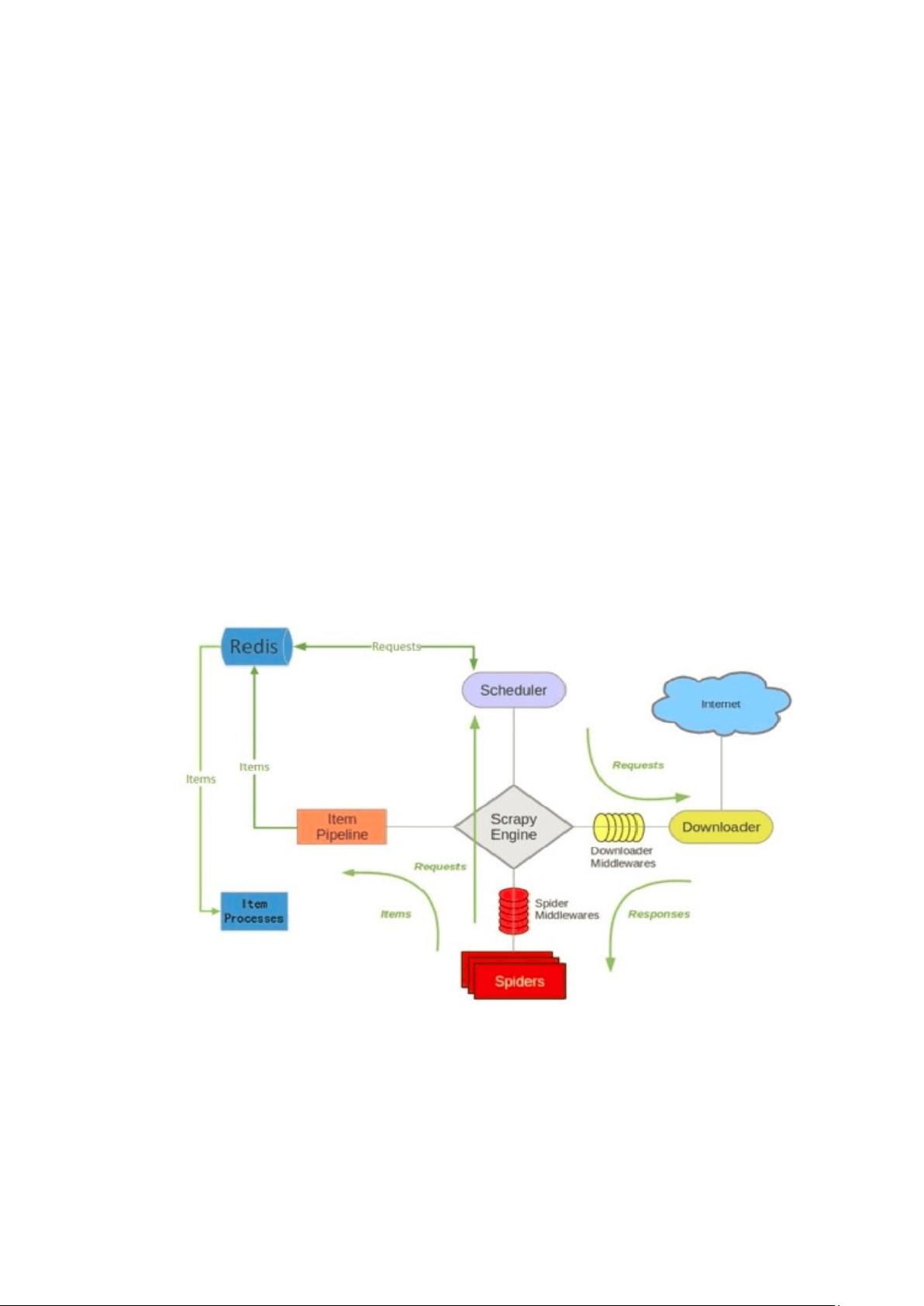
2.2.2.1、架构
Scrapy-Redis 则是一个基于 Redis 的 Scrapy 分布式组件。它利用 Redis 对用于爬取的请
求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。
scrapy-redi 重写 scrapy 一些比较关键的代码,将 scrapy 变成一个可以在多个主机上同时运
行的分布式爬虫。
加上 redis 后,上述 scrapy 的架构就变成下图所示:
基于 redis 的特性拓展了如下组件:
调度器(schedule)
scrapy-redis 调度器通过 redis 的 set 不重复的特性,巧妙的实现了 Duplication Filter 去
重(DupeFilter set 存放爬取过的 request)。 Spider 新生成的 request,将 request 的指纹到
redis 的 DupeFilter set 检查是否重复,并将不重复的 request push 写入 redis 的 request 队
列。调度器每次从 redis 的 request 队列里根据优先级 pop 出一个 request, 将此 request 发
给 spider 处理。
剩余31页未读,继续阅读
157 浏览量
141 浏览量
384 浏览量
117 浏览量
点击了解资源详情
166 浏览量
2024-11-16 上传









