YOLOv2深度解析:原理、改进与实现(附YOLOv3概述)
需积分: 0 148 浏览量
更新于2024-06-30
收藏 1.39MB PDF 举报
"这篇资源是关于目标检测领域中YOLOv2模型的原理与实现的详细解析,同时提及了YOLOv3的改进。文章基于YOLOv1的基础,介绍了YOLOv2如何通过一系列优化策略提升检测精度和速度,包括在COCO数据集和ImageNet数据集上的应用,以及与Faster R-CNN和SSD等模型的性能对比。"
YOLOv2是YOLO(You Only Look Once)目标检测算法的第二版,由Joseph Redmon等人在2016年提出,其主要改进点在于提高了检测精度并保持了快速检测速度。相比于YOLOv1,YOLOv2在多个方面进行了优化:
1. **Batch Normalization**:引入批量归一化层,加速模型训练,减少过拟合,提高网络的泛化能力。
2. **Convolutional with Anchor Boxes**:使用预定义的锚框(Anchor Boxes),针对不同大小和比例的对象,提高了检测框的准确性,增强了对不同尺度目标的检测能力。
3. **High-Resolution Classifier**:增加高分辨率的分类器,有助于捕捉更细致的目标特征,提高定位精度。
4. **Skip Connections**:采用残差学习框架,允许信息直接从低层传递到高层,帮助解决梯度消失问题,提高训练效率。
5. **Dimension Clusters**:根据训练数据自动生成锚框尺寸,更好地匹配实际物体的尺寸分布。
6. **Fine-Tuning with Pre-Trained Weights**:利用ImageNet预训练权重进行微调,加速收敛并提升模型性能。
7. **Multi-Scale Training**:在训练过程中使用不同尺度的图像,增强模型对不同大小对象的适应性。
8. **Darknet-19**:YOLOv2采用了更深层次的Darknet-19网络结构,提供更丰富的特征表示。
在YOLOv2的基础上,YOLOv3进一步提升了性能,引入了以下改进:
1. **Large Anchor Boxes**:使用更大尺度的锚框,增强对大物体的检测能力。
2. **Feature Pyramid Network (FPN)**:结合不同层次的特征,形成特征金字塔,兼顾小、中、大三种尺寸的目标检测。
3. **SPP-Block**:空间金字塔池化层,提高了模型对输入尺寸变化的鲁棒性。
4. **New Activations**:采用Leaky ReLU或Swish激活函数替代原来的ReLU,改善网络的非线性表达能力。
5. **Anchors Refinement**:对锚框进行更精细的调整,优化了检测框的定位。
YOLOv2和YOLOv3的这些改进使得它们在目标检测任务中保持了高效的同时,显著提升了检测精度,使得YOLO系列模型成为实时目标检测领域的热门选择。
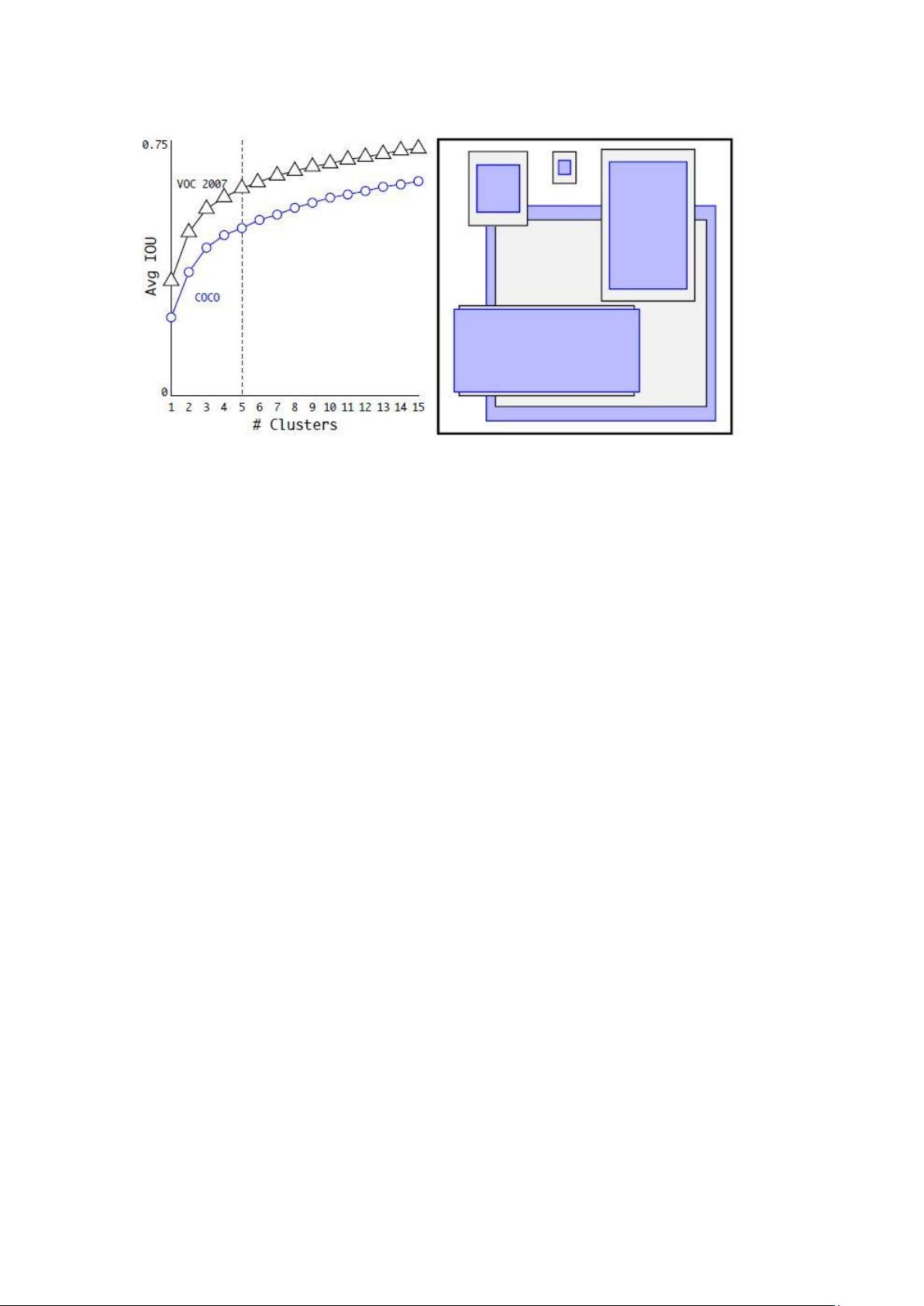
图 3:
数据集 VOC 和 COCO 上的边界框聚类分析结果
New Network: Darknet-19
YOLOv2 采用了一个新的基础模型(特征提取器),称为 Darknet-19,包括 19 个卷积层和 5
个 maxpooling 层,如图 4 所示。Darknet-19 与 VGG16 模型设计原则是一致的,主要采用 3 x3 卷
积,采用 2 x 2 的 maxpooling 层之后,特征图维度降低 2 倍,而同时将特征图的 channles 增
加两倍。与 NIN(Network in Network)类似,Darknet-19 最终采用 global avgpooling 做预测,并
且在 3 x 3 卷积之间使用 1 x 1 卷积来压缩特征图 channles 以降低模型计算量和参数。
Darknet-19 每个卷积层后面同样使用了 batch norm 层以加快收敛速度,降低模型过拟合。在
ImageNet 分类数据集上,Darknet-19 的 top-1 准确度为 72.9%,top-5 准确度为 91.2%,但是
模型参数相对小一些。使用 Darknet-19 之后,YOLOv2 的 mAP 值没有显著提升,但是计算量
却可以减少约 33%。
剩余19页未读,继续阅读
364 浏览量
200 浏览量
132 浏览量
359 浏览量
2024-09-05 上传
780 浏览量
2024-09-05 上传
323 浏览量
点击了解资源详情

lirumei
- 粉丝: 75
 我的内容管理
展开
我的内容管理
展开







最新资源
- 《ASP.NET 4.5 高级编程第8版》深度解读与教程
- 探究MSCOMM控件在单文档中的兼容性问题
- 数值计算方法在复合材料影响分析中的应用
- Elm插件支持Snowpack项目:热模块重载功能
- C++实现跨平台静态网页服务器
- C#开发的ProgaWeatherHW气象信息处理软件
- Memory Analyzer工具:深入分析内存溢出问题
- C#实现文件批量递归修改后缀名工具
- Matlab模拟退火实现经济调度问题解决方案
- Qetch工具:无比例画布绘制时间序列数据查询
- 数据分析技术与应用:Dataanalys-master深入解析
- HyperV高级管理与优化使用手册
- MTK6513/6575智能机主板下载平台
- GooUploader:基于SpringMVC和Servlet的批量上传解决方案
- 掌握log4j.jar包的使用与授权指南
- 基础电脑维修知识全解析
