SQL Server 2005文本分类教程
“Text Mining Tutorial,使用SQL Server 2005 Beta2进行文本分类的教程”
在本教程中,我们将深入探讨如何利用SQL Server 2005 Beta2的数据挖掘功能进行文本分类任务。文本挖掘是一种从非结构化文本数据中提取有价值信息的技术,它在诸如情感分析、主题建模、新闻分类等应用中具有广泛的应用。
首先,我们需要创建一个数据库来存储样本数据。在SQL Server Management Studio中,连接到本地SQL服务器(localhost)。接着,创建一个新的数据库并命名为"TDM"。这个数据库将用于存储我们要进行分类的新闻组文章。
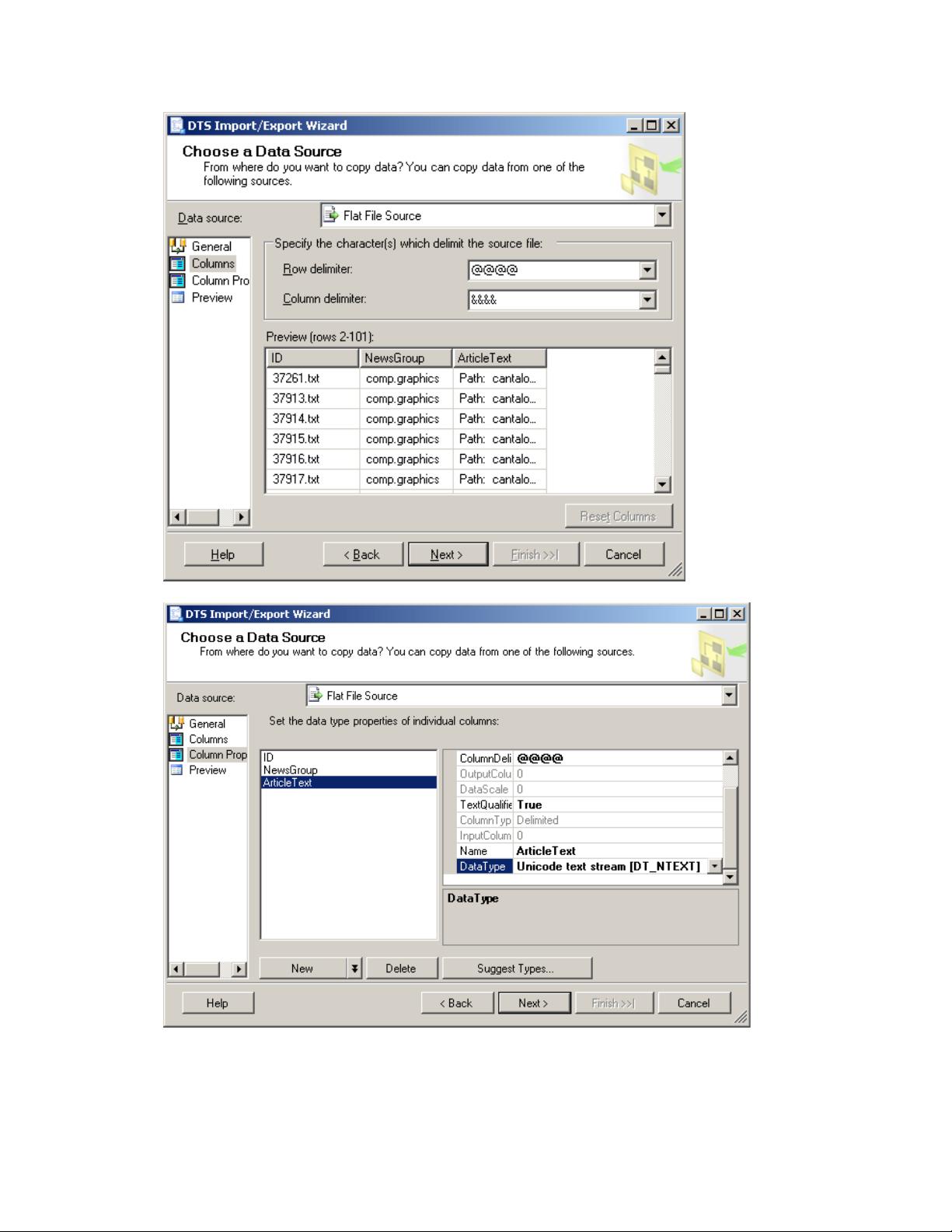
导入NewsGroup文章到数据库是接下来的步骤。右键点击新创建的数据库"TDM",选择“任务”->“导入”。在这个过程中,我们需要设置以下参数:
- 数据源:选择NGArticles.txt,这是一个从NGArticles.zip解压的平面文件。
- 表头行分隔符:@@@@
- 选中“列名在第一数据行”
- 行分隔符:@@@@
- 列分隔符:&&&&
- 对于“ArticleText”列,设置其属性为“变长字符串”。
导入完成后,数据库中应包含从news20.html获取的新闻组帖子的一个小样本集,这些帖子来自5个不同的类别。我们的目标是构建一个挖掘模型,能够将每个帖子自动归类到相应的类别中。
为了实现这个任务,我们需要执行以下步骤:
1. **预处理**:文本数据通常需要预处理,包括去除停用词、标点符号和数字,进行词干提取和词形还原,以及可能的拼写纠正。
2. **特征提取**:将文本转换为可被机器学习算法处理的形式,如TF-IDF(词频-逆文档频率)或者词袋模型。
3. **创建挖掘结构**:在SQL Server中,这可能涉及创建数据挖掘架构,定义输入列(如文章文本)和预测列(类别)。
4. **训练模型**:选择合适的分类算法,如朴素贝叶斯、决策树或支持向量机,用训练数据训练模型。
5. **评估模型**:使用交叉验证或独立测试集评估模型的性能,如准确率、召回率和F1分数。
6. **部署和应用**:一旦模型训练完成且表现良好,可以将其部署到生产环境中,对新的未分类文章进行实时分类。
7. **模型优化**:根据评估结果调整模型参数,如增减特征或改变算法,以提高分类性能。
本教程通过SQL Server 2005 Beta2提供了从数据导入到模型构建和评估的完整流程,对于初学者理解文本挖掘技术及其在实际操作中的应用非常有帮助。通过实践这个教程,读者将能够掌握如何利用数据库系统进行大规模文本分类,并能应用于自己的文本数据项目。
剩余12页未读,继续阅读
2017-02-22 上传
2021-02-04 上传
2019-09-23 上传
114 浏览量
2024-11-28 上传
2024-11-28 上传
2024-11-28 上传
2024-11-28 上传

readinguk
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
