Spark2集群数据倾斜分析与治理策略
76 浏览量
更新于2024-09-02
收藏 1.59MB PDF 举报
"Spark2运算效率,数据倾斜,ETL,分区表,大数据,效率,集群,聚合数据,任务执行,资源管理,心跳失败,GC,任务重跑,临时表,shuffle partition,KEY分布不均"
在分布式计算环境中,Spark2的运算效率是至关重要的,尤其是在大数据处理的生产集群中。数据倾斜是影响这些集群运算效率的一个关键因素。数据倾斜指的是在数据分布过程中,部分键(key)对应的值(value)远超过其他键,导致某些executor处理的数据量远大于其他executor,从而引起任务执行时间过长甚至任务失败。这种情况会显著增加任务执行的延迟,加大集群的运营压力,因为长时间的任务可能面临心跳失败或被GC回收的风险,进而需要重跑任务。
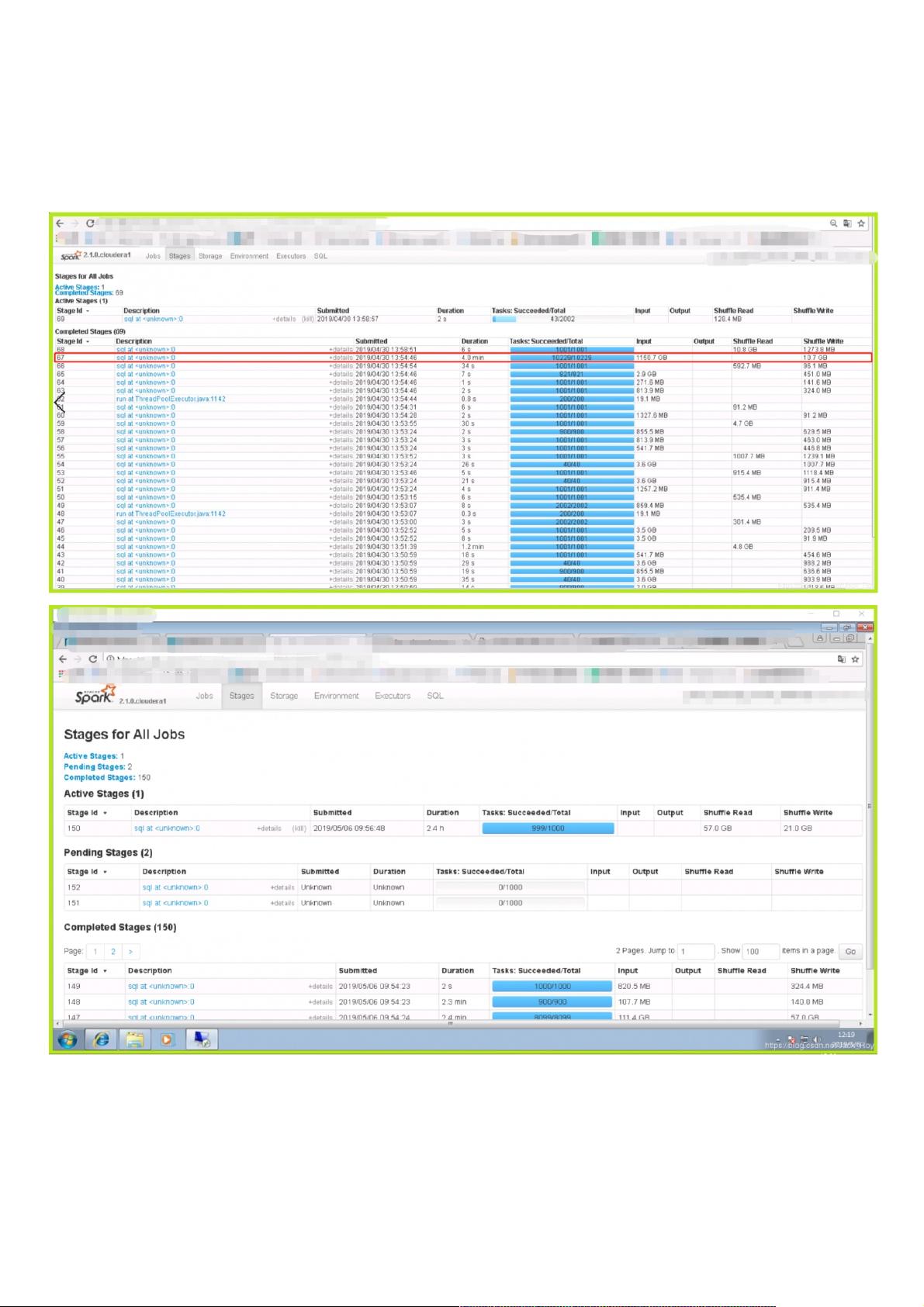
倾斜实例展示了这一问题的严重性,例如,stage67在处理TB级别的数据时出现了数据倾斜,导致大部分任务完成后,仍有少量任务耗时极长。这种情况在stage150中尤为明显,一个任务卡住2.4小时未完成,对整个工作流造成了严重阻塞。在资源紧张的集群环境中,这种问题可能导致任务频繁重跑,执行时长波动极大。
为了解决数据倾斜问题,首先需要确保任务提交时分配足够的资源,特别是对于分区表操作,因为这类表通常包含大量数据。并发性也是关键,需要确保足够的并发执行能力以充分利用集群资源。其次,如果在处理分区表并进行查询和聚合后写入临时表,可以调整`spark.sql.shuffle.partition`参数来优化数据分发和聚合,提高执行效率。然而,如果是追加操作(如INSERT INTO TABLE),则需要考虑避免小文件的积累,因为这会影响后续的读取性能。
针对数据倾斜的根本原因——键值分布不均,一种常见的策略是对聚合操作进行优化,比如在join操作中使用广播小表,或者采用更复杂的hash分区策略来均匀分布数据。此外,还可以尝试数据预处理,通过哈希或取模等方式重新分布数据,以减轻特定键的数据积压。
理解并有效应对数据倾斜是优化Spark2在生产集群中运行效率的关键步骤。开发人员需要注意代码编写,合理分配资源,以及选择合适的处理策略,从而避免或缓解数据倾斜问题,提高大数据处理的效率和稳定性。
【【Spark2运算效率】第四节运算效率】第四节 影响生产集群运算效率的原因之数据倾斜影响生产集群运算效率的原因之数据倾斜
【【Spark2运算效率】【运算效率】【Spark2运算效率】第四节运算效率】第四节 影响生产集群运算效率的原因之数据倾斜影响生产集群运算效率的原因之数据倾斜前言倾斜实例治理过程结语跳转
前言前言
当ETL调度任务所能拥有的资源能够满足其在较为资源冗余的状况下实施运算,长时间的运算过程中可能是涉及了数据倾斜的现象;数据倾斜可以说是分布式运算中不可避免的一种
现象,这种现象带来的后果就是任务执行时长会随着倾斜度的增加而变长,甚至会有Fail的风险(任务重跑);
不管是任务执行延时还是任务重跑,这都在一定程度上增加了集群的运营压力,所幸的是,只要编写过程稍加注意,还是能避免很大一部分的数据倾斜事件,剩余的部分也能通过一
些固定的手法进行更正解决。
倾斜实例倾斜实例
如图所示,在查看任务执行流程时,stage67发生了超大体量TB级别的数据输入:
数据倾斜带来的现象比较明显,通常是99%的task跑完后等待最后一个task的执行,在随后的stage150发生了数据倾斜,卡了2.4个小时仍未执行完成:
在集群资源紧张的时长,单个任务时间跨度过长可能存在响应心跳失败或者卡住的task被GC的现象,这会导致任务失败重跑,以至于在治理之前,该任务的执行时长在5-9个小时之
间浮动,具体如图:
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-20 上传
2021-01-07 上传
2021-01-07 上传
2018-06-26 上传
2018-09-14 上传
2012-02-11 上传

weixin_38690522
- 粉丝: 4
- 资源: 969
 我的内容管理
展开
我的内容管理
展开







最新资源
- diagwiz:ASCII图作为代码
- userscripts:一些改善UI的用户脚本
- bsu:FAMCS BSU(专业计算机安全)上用于大学实验室的资料库
- krip:彻底的简单加密,在后台使用WebCrypto
- 费用追踪器应用
- 111.zip机器学习神经网络数据预处理
- 财务管理系统
- NNet:用于手写识别的神经网络
- 加州阳光咖啡书吧创业计划书.zip
- Pricy - Amazon Price Watch-crx插件
- AMONG_py-0.0.3-py3-none-any.whl.zip
- MIUI12.5-其他:MIUITR Beta其他语言翻译
- SnowCat:薛定谔的猫
- AMD-1.2.1-py3-none-any.whl.zip
- Slider popover(iPhone源代码)
- 实现一个3D转盘菜单效果
