Java实现词法分析器示例代码解析
26 浏览量
更新于2024-09-01
4
收藏 112KB PDF 举报
"这篇文章主要介绍了如何使用Java实现一个简单的词法分析器,通过自定义的类和方法,对输入的代码进行分析,识别出其中的关键字、标识符、运算符等元素。"
在编程语言的编译或解释过程中,词法分析是至关重要的一步,它负责将源代码分解成一系列有意义的符号,即“标记”(Token)。这些标记随后会被语法分析阶段使用,以构建抽象语法树(AST),最终执行代码。本文将以Java为例,展示如何实现一个基础的词法分析器。
首先,我们创建一个`Lexer`类,这个类将负责读取输入的源代码,并对其进行词法分析。在`Lexer`类中,定义了几个关键属性:
1. `line`:用于记录当前处理的行号。
2. `character`:存储当前读取到的字符。
3. `keywords`:哈希表,用于存储保留字及其对应的编码。
4. `tokens`:ArrayList,保存分析出的标记。
5. `symtable`:符号表,保存标识符和它们的信息。
6. `reader`:BufferedReader对象,用于读取输入文件。
7. `isEnd`:布尔值,表示是否已到达文件末尾。
`Lexer`类中通常包含以下方法:
1. `main`方法:这是程序的入口点,创建`Lexer`实例并调用相关方法进行词法分析。
2. `Lexer`构造函数:初始化`Lexer`,例如打开文件流。
3. `printToken`:打印分析出的标记序列,方便调试和查看。
4. `printSymbolsTable`:打印符号表,展示已识别的标识符信息。
5. 读取字符和处理逻辑的方法,如`readChar`,`skipWhitespace`,`processIdentifier`,`processKeyword`等,这些方法会根据当前字符判断是否遇到关键字、标识符、运算符等,并生成相应的`Token`对象。
`Token`类通常包含标记的类型和值,而`Symbol`类则记录标识符的详细信息,比如其名称、类型和所在行号。
在实际的词法分析过程中,`Lexer`会按照以下步骤进行:
1. 读取源代码的第一个字符。
2. 判断字符类型,如果它是空格或换行符,则跳过;如果是数字,则开始读取数字序列;如果是字母,则可能是一个标识符或关键字,需要继续读取直到遇到非字母或非数字字符。
3. 对于遇到的运算符、分隔符(如括号、逗号)等,直接生成对应的标记。
4. 遇到未知字符时,可能抛出错误。
5. 这些过程会不断重复,直到文件读取结束。
在本文中,作者提供了使用Java实现词法分析器的实例代码,通过这个例子,我们可以理解词法分析的基本思路,并能根据自己的需求扩展和优化词法分析器,使其支持更多语言特性或提供更高效的分析。
总结来说,词法分析是编译器设计的基础,通过Java实现词法分析器,可以帮助我们更好地理解编译原理,并为编写更复杂的解析器打下基础。本文提供的代码实例是一个很好的起点,适合初学者参考和实践。
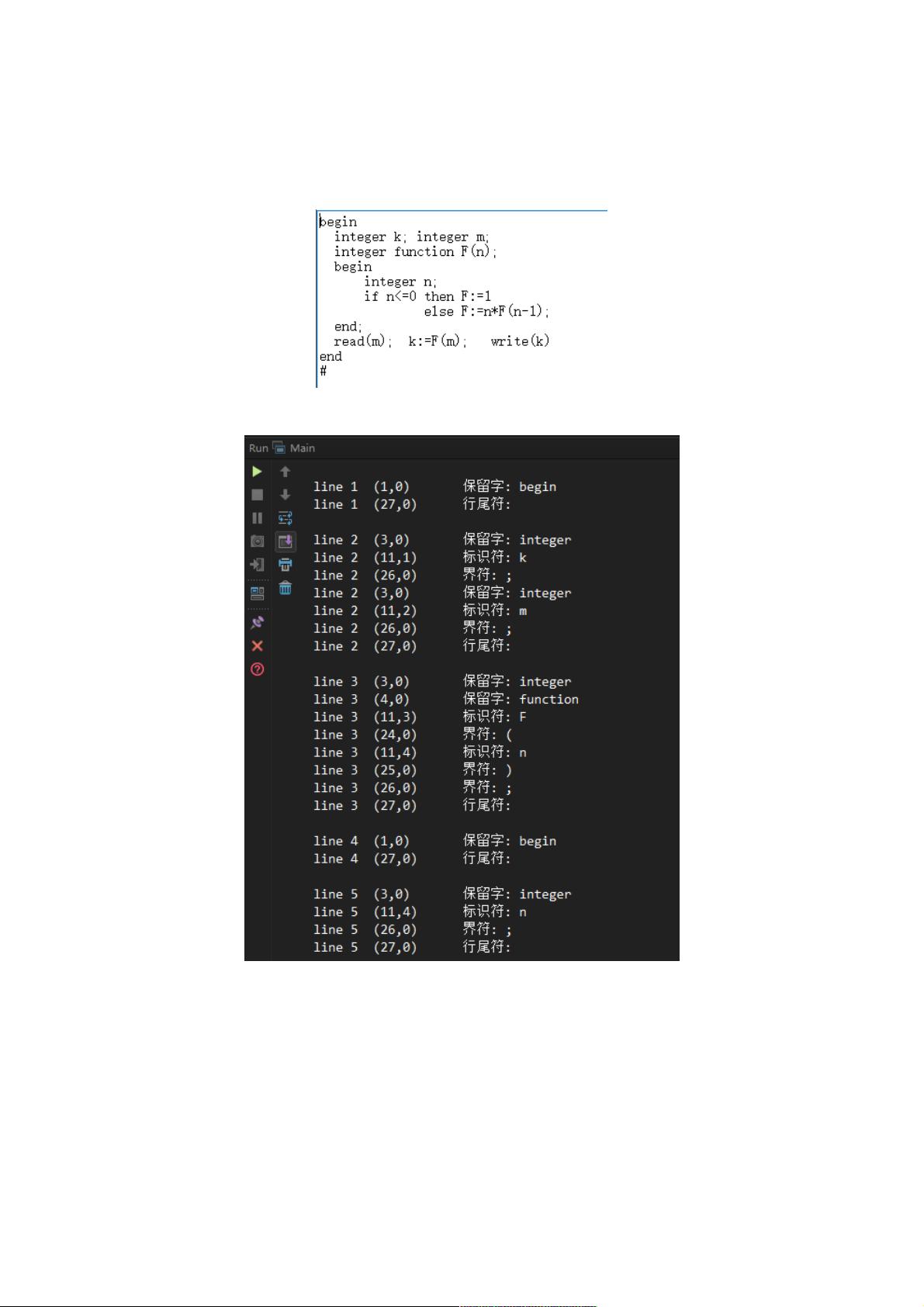
利用利用Java实现简单的词法分析器实例代码实现简单的词法分析器实例代码
众所周知编译原理中的词法分析算是很重要的一个部分,原理比较简单,不过网上大部分都是用C语言或者
C++来编写,因为最近在学习Java,故用Java语言实现了简单的词法分析器。感兴趣的朋友们可以参考借鉴,
下面来一起看看吧。
首先看下我们要分析的代码段如下:首先看下我们要分析的代码段如下:
输出结果如下:输出结果如下:
输出结果(a).PNG
下载后可阅读完整内容,剩余8页未读,立即下载
583 浏览量
448 浏览量
2010-04-21 上传
点击了解资源详情
1314 浏览量
2009-05-21 上传
156 浏览量
125 浏览量

weixin_38556541
- 粉丝: 6
- 资源: 970
 我的内容管理
展开
我的内容管理
展开







最新资源
- saturn::globe_with_meridians:新的迷你快速浏览器
- 企业前台大厅模型设计
- 基于python+django+vue开发的工作数据获取与可视化
- NodeJS-Sample-Project:使用Express的节点Js上的样本项目,具有基本结构和数据库连接
- 战利品
- myBinomTest(s,n,p,Sided):具有任意二项式概率的 1 或 2 边二项式检验-matlab开发
- 银行存款余额调节表格excel模版下载
- 演唱会舞台3D模型
- autoprop:从访问器方法推断属性
- ABAssignment04
- 物品交接明细表excel模版下载
- desafio_conceitos_node
- vewa_app2:VEWA 网络应用程序
- 中式现代风会议室模型
- gritjz.github.io:史蒂芬·张的个人网站
- 工程质量验收记录表excel模版下载
