分布式存储与计算:CAP、BASE原则在大数据时代的应用
140 浏览量
更新于2024-08-28
收藏 240KB PDF 举报
"海量数据下的分布式存储与计算"
在大数据时代,传统的集中式存储方式已无法满足数据处理的需求,因此分布式存储成为了重要的解决方案。分布式存储旨在将海量数据分散存储在多个节点上,以提高数据处理效率和系统的可扩展性。在这个过程中,理论基础如CAP定理、BASE原则以及ACID特性起着至关重要的角色。
CAP定理,由Eric Brewer提出,是分布式系统设计中的基础理论。它指出,在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)这三个属性无法同时最大化。传统的关系型数据库通常追求CA(强一致性与高可用性),而NoSQL和云存储系统则更倾向于牺牲一致性以获取更高的可用性和分区容错性,这通常表现为采用BASE原则。
ACID是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)的缩写,是传统关系型数据库遵循的事务处理原则,确保了数据库操作的准确性和完整性。而在分布式环境中,为了适应大规模数据处理和高并发需求,一些系统采用了弱化的一致性模型,如最终一致性,以换取更高的系统性能和可用性。
BASE原则,即基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventual Consistency),是NoSQL系统常采用的设计原则。基本可用意味着系统允许部分服务暂时不可用,以保证整体服务的可用性;软状态指的是系统状态可以在一段时间内存在不一致;最终一致性则保证在一段时间后,所有副本的数据会达到一致。
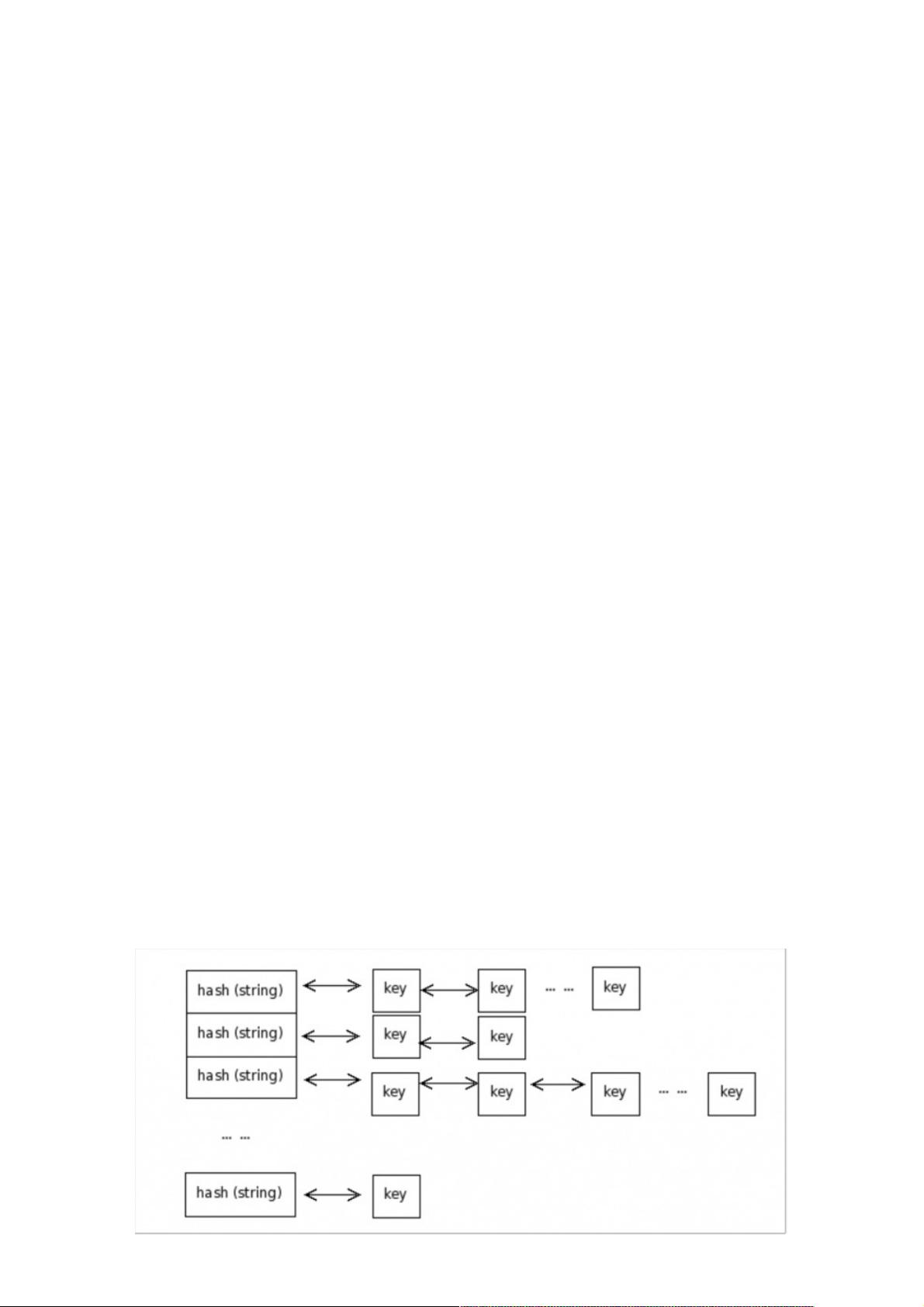
在分布式存储的实现上,常见的数据模型包括键值对(key-value)和自由模式(Schema-Free)。键值对模型如MongoDB,每个记录由键和值两部分组成,键用于定位数据,值存储实际内容。自由模式如HBase,每个记录由一个主键和多个列组成,类似于关系型数据库的行和列结构。在实现这些模型时,常用的技术包括哈希加链表和B+树。哈希加链表通过哈希函数确定数据存储位置,相同哈希值的数据形成链表,而B+树则是一种高效的索引结构,适用于大数据量的检索。
海量数据下的分布式存储与计算涉及到分布式系统的设计、数据模型的选择以及一致性策略的权衡。理解并灵活应用CAP、ACID和BASE等理论,有助于构建高效、稳定且可扩展的大数据处理平台。
海量数据下的分布式存储与计算海量数据下的分布式存储与计算
存储
从理论角度
提到大数据存储nosql是不得不提的一个部分,CAP,BASE,ACID这些原理在过去的一些年对其有着一定的指导作用(近年来
随着各种实时计算模型的发展,CAP也被渐渐打破)
CAP:(Consistency-Availability-Partition Tolerance
数据一致性(C): 等同于所有节点访问同一份最新的数据副本;
对数据更新具备高可用性(A): 在可写的时候可读, 可读的时候可写,最少的停工时间
能容忍网络分区(P)
eg:
传统数据库一般采用CA即强一致性和高可用性
nosql,云存储等一般采用降低一致性的代价来获得另外2个因素
ACID:按照CAP分法ACID是许多CA型关系数据库多采用的原则:
A:Atomicity原子性,事务作为最小单位,要么不执行要么完全执行
C:Consistency一致性,一个事务把一个对象从一个合法状态转到另一个合法状态,如果交易失败,把对象恢复到前一个合
法状态。即在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏
I:Isolation独立性(隔离性),事务的执行是互不干扰的,一个事务不可能看到其他事务运行时,中间某一时刻的数据。
D:Durability:事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚
BASE:一般是通过牺牲强一致性,来换取可用性和分布式
BA:Basically Aavilable基本可用:允许偶尔的失败,只要保证绝大多数情况下系统可用
S:Soft State软状态:无连接?无状态?
E:Eventual Consistency最终一致性:要求数据在一定的时间内达到一致性
以云存储为例:目前的云存储多以整体上采用BASE局部采用ACID,由于使用分布式使用多备份所以多采用最终一致性
Nosql常见的数据模型有key/value和Schema Free(自由列表模式)两种,
key/value,每条记录由2个域组成,一个作为主键,一个存储记录的数据(mongodb)
Schema Free, 每条记录有一个主键,若干条列组成,有点类似关系型数据库(hbase)
在实现这些模型的时候基本使用2种实现方式:哈希加链表,或者B+树的方式
哈希加链表:通过将key进行哈希来确定存储位置,相同哈希值的数据存储成链表
下载后可阅读完整内容,剩余5页未读,立即下载
2021-08-09 上传
2022-03-18 上传
2021-08-11 上传
2021-08-11 上传
2021-08-10 上传
2024-05-24 上传
2022-10-21 上传
2021-12-08 上传
点击了解资源详情

weixin_38666114
- 粉丝: 7
- 资源: 971
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
