数据挖掘十大算法解析
需积分: 50 70 浏览量
更新于2024-07-25
收藏 783KB PDF 举报
"这篇论文是关于数据挖掘领域最知名的十种算法的综述,由2006年IEEE国际数据挖掘会议(ICDM)评选出,包括C4.5、k-Means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、朴素贝叶斯和CART。这些算法对研究社区产生了深远影响,并且在当前和未来的研究中仍然具有重要意义。"
数据挖掘是信息技术中的一个关键领域,它涉及从大量数据中发现有价值的模式、关系和规律。以下是对这十大算法的详细解释:
1. **C4.5**:这是决策树学习算法ID3的升级版,由Ross Quinlan开发。C4.5使用信息增益比来选择最佳划分属性,能处理连续和离散属性,并能处理缺失值。
2. **k-Means**:这是一种无监督学习的聚类算法,通过迭代将数据分配到k个群组中,目标是最小化组内差异并最大化组间差异。k值的选择对结果有显著影响。
3. **支持向量机(SVM)**:SVM是一种监督学习模型,用于分类和回归分析。它通过构造最大间隔超平面来区分不同类别,尤其适用于高维数据。
4. **Apriori**:这是关联规则学习的经典算法,用于发现项集之间的频繁模式。它基于“先验知识”原则,即如果一个项集不频繁,其任何子集也不可能频繁。
5. **期望最大化(EM)**:EM算法是一种用于含有隐变量的概率模型参数估计的迭代方法,常用于混合高斯模型或隐马尔可夫模型等。
6. **PageRank**:Google的原始排名算法,衡量网页的重要性。它通过计算网页间的链接结构来评估每个页面的权威性。
7. **AdaBoost**:AdaBoost是一种集成学习算法,通过迭代加权训练数据,提升弱分类器的性能,生成强分类器。
8. **k近邻(kNN)**:kNN是一种基于实例的学习,根据最近邻的类别的多数投票来预测新样本的类别。k值的选择对结果有直接影响。
9. **朴素贝叶斯**:这是一种基于贝叶斯定理的分类算法,假设特征之间相互独立,简化了模型的计算复杂度。
10. **CART(分类与回归树)**:CART算法可生成分类树和回归树,用于分类和回归任务。它通过最小化基尼不纯度或平方误差来决定最佳分割点。
这些算法不仅在数据挖掘中占有重要地位,而且在机器学习、人工智能、商业智能等领域也有广泛应用。它们各自的优势和局限性决定了在特定问题上的适用性,而随着技术的发展,这些经典算法不断被优化和改进,以适应更复杂的数据环境和需求。
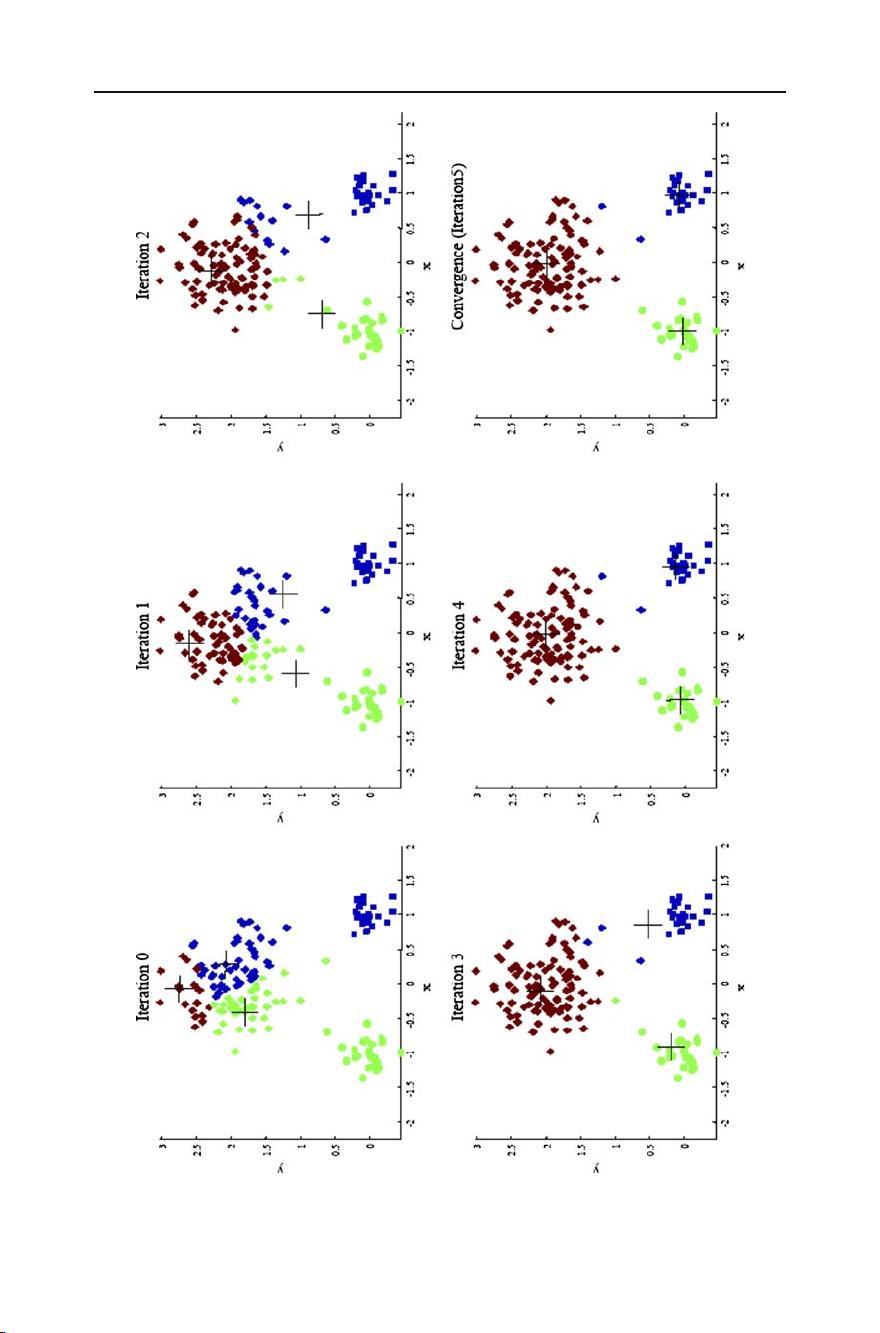
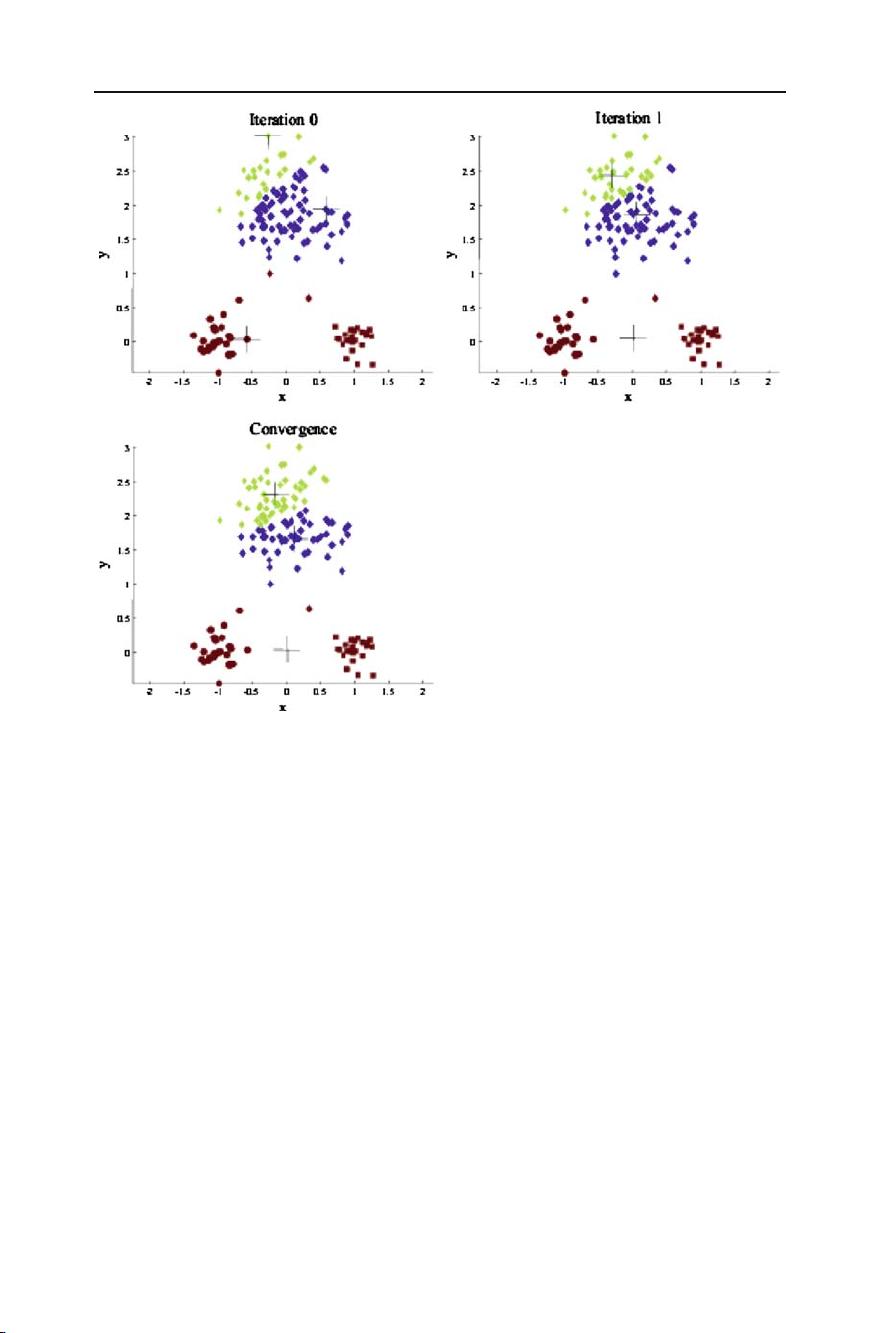
Top 10 algorithms in data mining 7
Fig. 1 Changes in cluster representative locations (indicated by ‘+’ signs) and data assignments (indicated
by color) during an execution of the k-means algorithm
123
剩余36页未读,继续阅读
2018-01-20 上传
141 浏览量
2021-04-27 上传
2021-04-28 上传
2021-05-19 上传
2021-06-29 上传
2023-04-04 上传
2021-06-29 上传
2021-01-30 上传

gumiao595
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
