Java实现Cassandra分页操作详解
60 浏览量
更新于2024-09-01
1
收藏 134KB PDF 举报
"java实现cassandra高级操作之分页实例,主要介绍如何在Java中处理Cassandra数据库的分页查询,适合有项目实际需求的情况。"
在Cassandra数据库中,分页查询与传统的关系型数据库如MySQL有所不同,由于其数据模型和分布式特性,Cassandra的分页通常基于令牌(token)进行,这导致了它不支持直接跳转到特定页数的查询,而是更适合于向前或向后翻页。以下将详细解释如何在Java中进行Cassandra的分页操作。
首先,设置抓取大小(fetch size)是控制分页的关键。抓取大小定义了一次从Cassandra节点获取的数据行数,也就是每一页的记录数。默认情况下,如果不设定,Cassandra的fetch size为5000。你可以通过以下方式在建立Cluster实例时设置fetch size:
```java
Cluster cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.withQueryOptions(new QueryOptions().setFetchSize(2000))
.build();
```
或者在运行时修改:
```java
cluster.getConfiguration().getQueryOptions().setFetchSize(2000);
```
同时,你也可以在Statement对象上单独设置fetch size,这样将覆盖Cluster级别的设置:
```java
Statement statement = new SimpleStatement("your query");
statement.setFetchSize(2000);
```
需要注意的是,即使设置了fetch size,Cassandra也可能返回略多于或略少于指定数量的结果,这是因为数据分布的不确定性。
进行分页查询时,你需要保存上一次查询的最后一个结果的主键,以便在下次查询时作为起点。例如,如果要获取下一页,你可以将上一页最后一个记录的主键传递给新的Statement。这是因为Cassandra的分页是基于令牌范围的,每个分页查询都需要知道前一个查询的结束点来确定下一个查询的开始点。
迭代结果集也是分页的重要部分。使用`ResultSet`的迭代器,你可以逐个处理每一页的数据,直到没有更多结果:
```java
ResultSet resultSet = session.execute(statement);
Row row;
while ((row = resultSet.one()) != null) {
// 处理每一行数据
}
```
`resultSet.one()`方法会返回下一行,当没有更多数据时返回`null`,从而结束迭代。
在实际项目中,你可能还需要处理分页边界的情况,比如处理最后一页不足fetch size的情况,或者用户请求的页数超出实际存在的页数。此外,考虑到性能,避免在不必要的情况下存储和传递大量主键信息也很重要。
Java中的Cassandra分页涉及到fetch size的设定和主键管理,理解这些概念对于优化数据检索和提升系统性能至关重要。在设计和实现分页功能时,需要根据实际业务需求来调整策略,确保用户体验的同时,保证系统的稳定性和效率。
java实现实现cassandra高级操作之分页实例(有项目具体需求)高级操作之分页实例(有项目具体需求)
主要介绍了java实现cassandra高级操作之分页实例(有项目具体需求),具有一定的参考价值,感兴趣的小伙
伴们可以参考一下。
上篇博客讲到了cassandra的分页,相信大家会有所注意:下一次的查询依赖上一次的查询(上一次查询的最后一条记录的全部
主键),不像mysql那样灵活,所以只能实现上一页、下一页这样的功能,不能实现第多少页那样的功能(硬要实现的话性能就
太低了)。
我们先看看驱动官方给的分页做法
如果一个查询得到的记录数太大,一次性返回回来,那么效率非常低,并且很有可能造成内存溢出,使得整个应用都奔溃。所
以了,驱动对结果集进行了分页,并返回适当的某一页的数据。
一、设置抓取大小(一、设置抓取大小(Setting the fetch size))
抓取大小指的是一次从cassandra获取到的记录数,换句话说,就是每一页的记录数;我们能够在创建cluster实例的时候给它
的fetch size指定一个默认值,如果没有指定,那么默认是5000
// At initialization:
Cluster cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.withQueryOptions(new QueryOptions().setFetchSize(2000))
.build();
// Or at runtime:
cluster.getConfiguration().getQueryOptions().setFetchSize(2000);
另外,statement上也能设置fetch size
Statement statement = new SimpleStatement("your query");
statement.setFetchSize(2000);
如果statement上设置了fetch size,那么statement的fetch size将起作用,否则则是cluster上的fetch size起作用。
注意:设置了fetch size并不意味着cassandra总是返回准确的结果集(等于fetch size),它可能返回比fetch size稍微多一点或者
少一点的结果集。
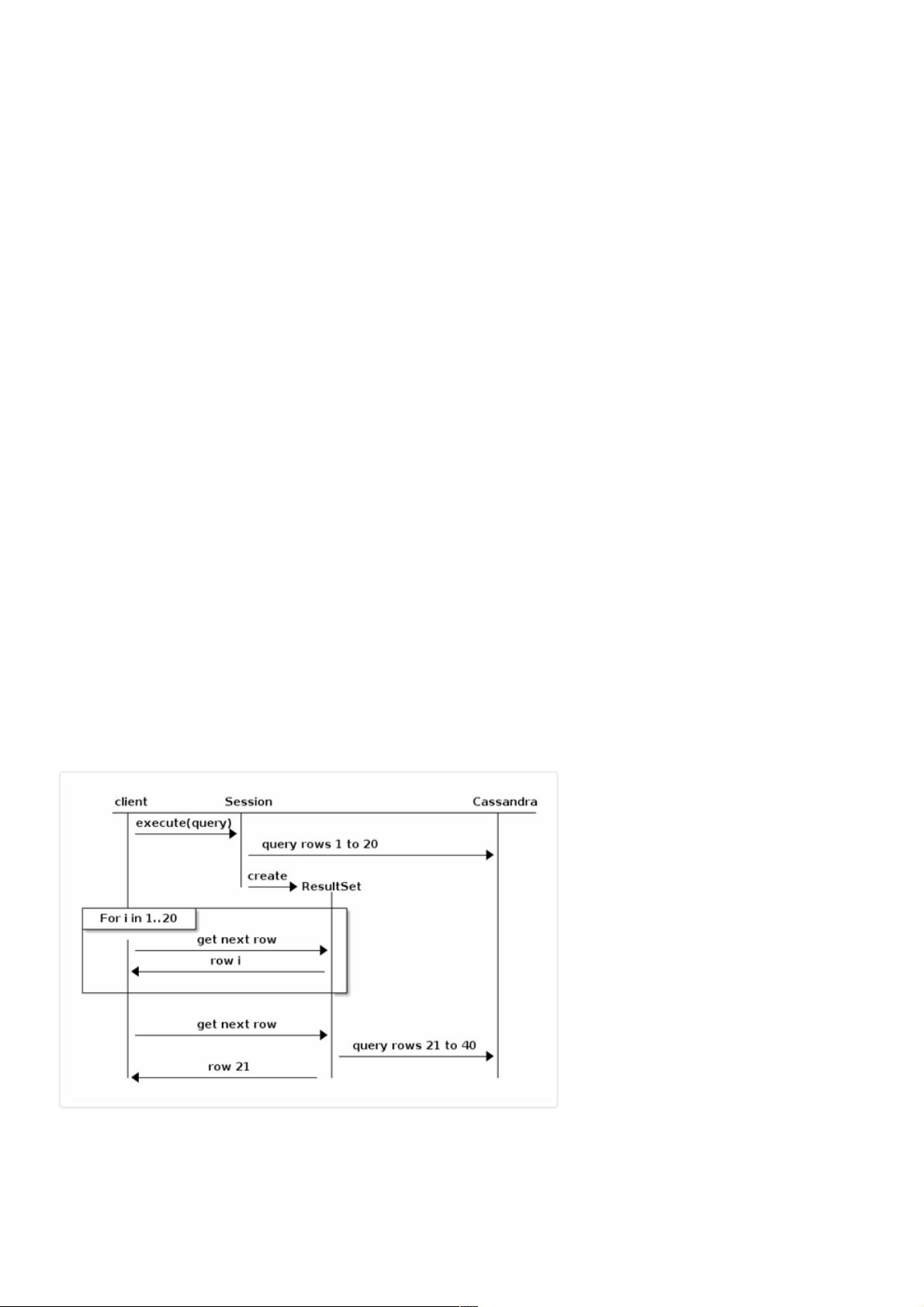
二、结果集迭代二、结果集迭代
fetch size限制了每一页返回的结果集的数量,如果你迭代某一页,驱动会在后台自动的抓取下一页的记录。如下例,fetch
size = 20:
默认情况下,后台自动抓取发生在最后一刻,也就是当某一页的记录被迭代完的时候。如果需要更好的控制,ResultSet接口
提供了以下方法:
getAvailableWithoutFetching() and isFullyFetched() to check the current state;
fetchMoreResults() to force a page fetch;
以下是如何使用这些方法提前预取下一页,以避免在某一页迭代完后才抓取下一页造成的性能下降:
下载后可阅读完整内容,剩余3页未读,立即下载
2017-06-16 上传
2021-04-04 上传
2023-12-29 上传
2022-11-15 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38668754
- 粉丝: 3
- 资源: 972
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
