
6 T DW I RESE A RCH
BIG DATA A N A LY T I C S
natural language processing, text analytics, articial intelligence, and so on. It’s quite an arsenal of
tool types, and savvy users get to know their analytic requirements before deciding which tool type is
appropriate to their needs.
All these techniques have been around for years, many of them appearing in the 1990s. e
dierence today is that far more user organizations are actually using them. at’s because most of
these techniques adapt well to very large, multi-terabyte data sets with minimal data preparation.
at brings us to big data.
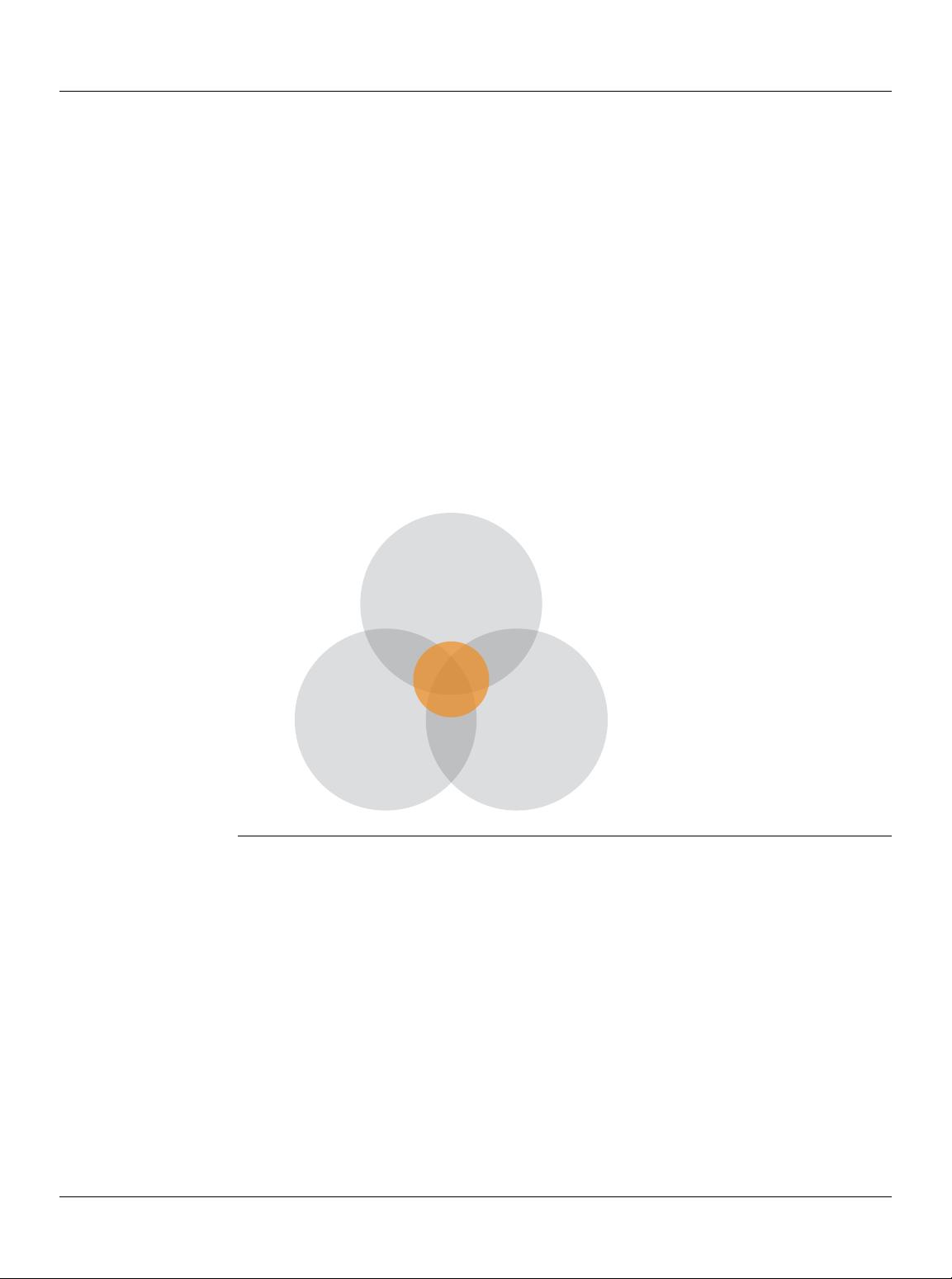
Dening Big Data Via the Three Vs
Most denitions of big data focus on the size of data in storage. Size matters, but there are other
important attributes of big data, namely data variety and data velocity. e three Vs of big data
(volume, variety, and velocity) constitute a comprehensive denition, and they bust the myth that
big data is only about data volume. In addition, each of the three Vs has its own ramications for
analytics.
2
(See Figure1.)
Figure1. e three Vs of big data
Data volume as a dening attribute of big data.
It’s obvious that data volume is the primary attribute of big data. With that in mind, most people
dene big data in terabytes—sometimes petabytes. For example, a number of users interviewed by
TDWI are managing 3 to 10 terabytes (TB) of data for analytics. Yet, big data can also be quantied
by counting records, transactions, tables, or les. Some organizations nd it more useful to quantify
big data in terms of time. For example, due to the seven-year statute of limitations in the U.S., many
rms prefer to keep seven years of data available for risk, compliance, and legal analysis.
e scope of big data aects its quantication, too. For example, in many organizations, the
data collected for general data warehousing diers from data collected specically for analytics.
Dierent forms of analytics may have dierent data sets. Some analytic practices lead a business
analyst or similar user to create ad hoc analytic data sets per analytic project. en, there’s the
entire enterprise, which in toto has its own, even larger scope of big data. Furthermore, each of these
Big data isn’t just about
data volume.
The scope of big data
varies widely.
VOLUME
VELOCITY VARIETY
•
Terabytes
•
Records
•
Transactions
•
Tables, les
•
Structured
•
Unstructured
•
Semistructured
•
All the above
•
Batch
•
Near time
•
Real time
•
Streams
3 Vs of
Big Data
2
ese denitions of big data were originally developed in TDWI blog posts, available at tdwi.org/blogs/philip-russom.

剩余37页未读,继续阅读

我没那么帅
- 粉丝: 5
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多功能HTML网站模板:手机电脑适配与前端源码
- echarts实战:构建多组与堆叠条形图可视化模板
- openEuler 22.03 LTS专用openssh rpm包安装指南
- H992响应式前端网页模板源码包
- Golang标准库深度解析与实践方案
- C语言版本gRPC框架支持多语言开发教程
- H397响应式前端网站模板源码下载
- 资产配置方案:优化资源与风险管理的关键计划
- PHP宾馆管理系统(毕设)完整项目源码下载
- 中小企业电子发票应用与管理解决方案
- 多设备自适应网页源码模板下载
- 移动端H5模板源码,自适应响应式网页设计
- 探索轻量级可定制软件框架及其Http服务器特性
- Python网站爬虫代码资源压缩包
- iOS App唯一标识符获取方案的策略与实施
- 百度地图SDK2.7开发的找厕所应用源代码分享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


