Python机器学习:k-NN算法与特征缩放实战
需积分: 5 15 浏览量
更新于2024-06-22
收藏 1.61MB PDF 举报
"Python机器学习(scikit-learn)的k近邻(k-NN)算法与特征缩放技术"
k近邻(k-NN)算法是一种基于实例的学习方法,它属于非参数监督学习算法,广泛应用于分类和回归问题。k-NN算法的核心思想是:通过寻找训练集中与待预测样本最相似的k个邻居,根据这些邻居的类别或属性来预测新样本的类别或属性。其简单易懂,无需训练模型,只需存储训练数据,适合小规模数据集。但在大规模数据集上,由于计算复杂度较高,可能会变得效率低下。
在scikit-learn库中,`sklearn.neighbors`包提供了k-NN相关的实现。其中,`KNeighborsClassifier`是用于分类任务的k-NN分类器,可以根据最近的k个邻居的类别进行投票,决定新样本的类别。`KNeighborsRegressor`则用于回归任务,通过最近邻的属性值来预测目标变量。
特征缩放是k-NN算法中一个重要的预处理步骤。在特征尺度不一的情况下,具有较大数值范围的特征可能在距离计算中占据主导地位,导致距离度量失真。特征缩放的目标是将所有特征调整到同一尺度,常见的方法有标准化(StandardScaler)和归一化(MinMaxScaler)。
标准化,也称为Z-score标准化,通过减去特征的平均值并除以其标准差,将数据转换为均值为0,标准差为1的标准正态分布。公式为:\(X_{std} = \frac{X - \mu}{\sigma}\),其中,\(\mu\)是特征的平均值,\(\sigma\)是特征的标准差。标准化对于符合正态分布或者对波动范围敏感的算法(如k-NN)特别有用。
归一化,通常是指最小-最大缩放,将特征值映射到0到1的区间内。公式为:\(X_{norm} = \frac{X - X_{min}}{X_{max} - X_{min}}\),其中,\(X_{min}\)和\(X_{max}\)分别是特征的最小值和最大值。这种缩放方法对于数据分布没有特定假设,适用于所有数值型特征。
在scikit-learn中,可以使用`StandardScaler`进行标准化操作,`MinMaxScaler`进行归一化操作。在使用之前,通常需要先对训练数据进行缩放,然后用缩放后的参数对测试数据进行同样的处理,以保持数据的相对比例。
下面是一个简单的k-NN分类器和特征缩放的Python代码示例:
```python
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
# 假设X_train, y_train是训练数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train_scaled, y_train)
# 对新的未标记数据X_test进行预测
X_test_scaled = scaler.transform(X_test)
y_pred = knn.predict(X_test_scaled)
```
k-NN算法在scikit-learn中的实现提供了方便的接口,结合特征缩放技术,可以在多种机器学习场景下得到良好的预测效果。在实际应用中,需要注意选择合适的k值、距离度量方法以及特征缩放策略,以优化算法性能。
https://xiets.blog.csdn.net/article/details/130957522
4/17
估
计
器
有
许
多
属
性
,
有
些
属
性
以
下
划
线
_
结
尾
的
,
表
示
该
属
性
是
训
练
模
型
后
(
调
⽤
fit()
⽅
法
后
)
设
置
的
值
。
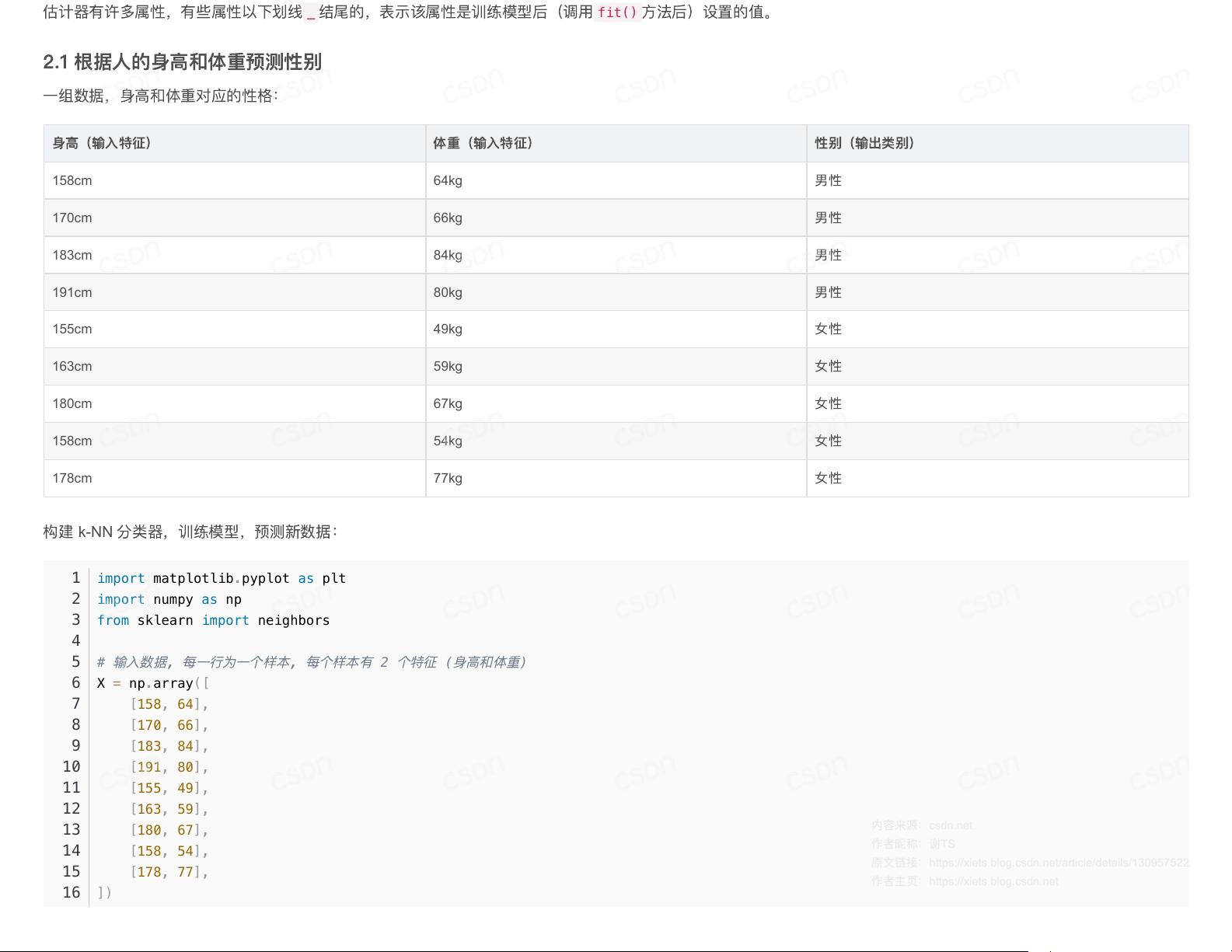
2.1
根
据
⼈
的
身
⾼
和
体
重
预
测
性
别
⼀
组
数据
,
身
⾼
和
体
重
对
应
的
性
格
:
身
⾼
(
输
⼊
特
征
)
体
重
(
输
⼊
特
征
)
性
别
(
输
出
类
别
)
158cm 64kg
男
性
170cm 66kg
男
性
183cm 84kg
男
性
191cm 80kg
男
性
155cm 49kg
⼥
性
163cm 59kg
⼥
性
180cm 67kg
⼥
性
158cm 54kg
⼥
性
178cm 77kg
⼥
性
构
建
k-NN
分
类
器
,
训
练
模
型
,
预
测
新数据
:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import neighbors
#
输
⼊
数据
,
每
⼀
⾏
为
⼀个
样本
,
每
个
样本有
2
个
特
征
(
身
⾼
和
体
重
)
X = np.array([
[158, 64],
[170, 66],
[183, 84],
[191, 80],
[155, 49],
[163, 59],
[180, 67],
[158, 54],
[178, 77],
])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
内
容
来
源
:
csdn.net
作
者
昵
称
:
谢
TS
原
⽂
链
接
:
https://xiets.blog.csdn.net/article/details/130957522
作
者
主
⻚
:
https://xiets.blog.csdn.net
剩余16页未读,继续阅读
2018-11-21 上传
2016-11-01 上传
2021-02-04 上传
2023-09-21 上传
2024-10-27 上传
2024-12-20 上传
2023-07-04 上传
2023-09-23 上传
2023-07-13 上传

谢TS
- 粉丝: 2w+
- 资源: 23
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
