




Vote3Deep:利用稀疏卷积神经网络实现高效3D点云物体检测
需积分: 50 3 浏览量
更新于2024-09-08
收藏 1.52MB PDF 举报
本文主要探讨了在3D点云数据中使用卷积神经网络(CNN)进行快速对象检测的方法。传统的3D点云处理通常依赖于密集的网格结构,这在计算上消耗较大。作者提出了一种名为Vote3Deep的创新方法,该方法引入了特征为中心的投票机制,设计了专门针对输入稀疏性的新型卷积层,实现了对3D点云的高效处理。
在Vote3Deep架构中,关键点在于采用了一种特征导向的投票策略,这种策略能够有效地利用输入数据的稀疏特性,减少不必要的计算。通过这种方式,网络能够在保持较高精度的同时,显著提高执行速度。为了进一步优化模型的效率,研究者还提出了在卷积滤波器激活上应用L1正则化,这一策略有助于增强中间表示的稀疏性,从而进一步提升模型的性能。
在实验部分,作者将他们的方法应用于KITTI对象检测基准,这是评估3D点云对象检测性能的标准平台。结果表明,即使是只有三层的Vote3Deep模型,也能在激光和激光视觉基础上的检测任务中超越先前的最佳方法,性能提升幅度高达40%。而且,与现有技术相比,Vote3Deep在处理时间上依然保持了竞争力。
这篇论文标志着在3D点云数据处理中使用稀疏卷积层和L1正则化的先例,这对于大规模、实时的3D场景理解具有重大意义。它不仅提升了对象检测的准确性,还极大地提高了计算效率,为未来的3D计算机视觉和自动驾驶等领域开辟了新的可能性。这项工作对于那些关注3D点云处理效率和性能优化的科研人员和技术开发者来说,是一篇重要的参考文献。
Vote3Deep: Fast Object Detection in 3D Point Clouds Using Efficient
Convolutional Neural Networks
Martin Engelcke, Dushyant Rao, Dominic Zeng Wang, Chi Hay Tong, Ingmar Posner
Abstract— This paper proposes a computationally efficient
approach to detecting objects natively in 3D point clouds
using convolutional neural networks (CNNs). In particular, this
is achieved by leveraging a feature-centric voting scheme to
implement novel convolutional layers which explicitly exploit
the sparsity encountered in the input. To this end, we ex-
amine the trade-off between accuracy and speed for different
architectures and additionally propose to use an L
1
penalty
on the filter activations to further encourage sparsity in the
intermediate representations. To the best of our knowledge, this
is the first work to propose sparse convolutional layers and L
1
regularisation for efficient large-scale processing of 3D data.
We demonstrate the efficacy of our approach on the KITTI
object detection benchmark and show that Vote3Deep models
with as few as three layers outperform the previous state of the
art in both laser and laser-vision based approaches by margins
of up to 40% while remaining highly competitive in terms of
processing time.
I. INTRODUCTION
3D point cloud data is ubiquitous in mobile robotics
applications such as autonomous driving, where efficient and
robust object detection is pivotal for planning and decision
making. Recently, computer vision has been undergoing
a transformation through the use of convolutional neural
networks (CNNs) (e.g. [1], [2], [3], [4]). Methods which
process 3D point clouds, however, have not yet experienced a
comparable breakthrough. We attribute this lack of progress
to the computational burden introduced by the third spatial
dimension. The resulting increase in the size of the input
and intermediate representations renders a naive transfer of
CNNs from 2D vision applications to native 3D perception
in point clouds infeasible for large-scale applications. As a
result, previous approaches tend to convert the data into a 2D
representation first, where nearby features are not necessarily
adjacent in the physical 3D space – requiring models to
recover these geometric relationships.
In contrast to image data, however, typical point clouds
encountered in mobile robotics are spatially sparse, as most
regions are unoccupied. This fact was exploited in [5],
where the authors propose Vote3D, a feature-centric voting
algorithm leveraging the sparsity inherent in these point
clouds. The computational cost is proportional only to the
number of occupied cells rather than the total number of
cells in a 3D grid. [5] proves the equivalence of the voting
scheme to a dense convolution operation and demonstrates
its effectiveness by discretising point clouds into 3D grids
and performing exhaustive 3D sliding window detection with
Authors are from the Oxford Robotics Institute, University of Oxford.
{firstname}@robots.ox.ac.uk
Inpu t&Point&Cloud
Object&Detections
CNNs
(a) 3D point cloud detection with CNNs
(b) Reference image
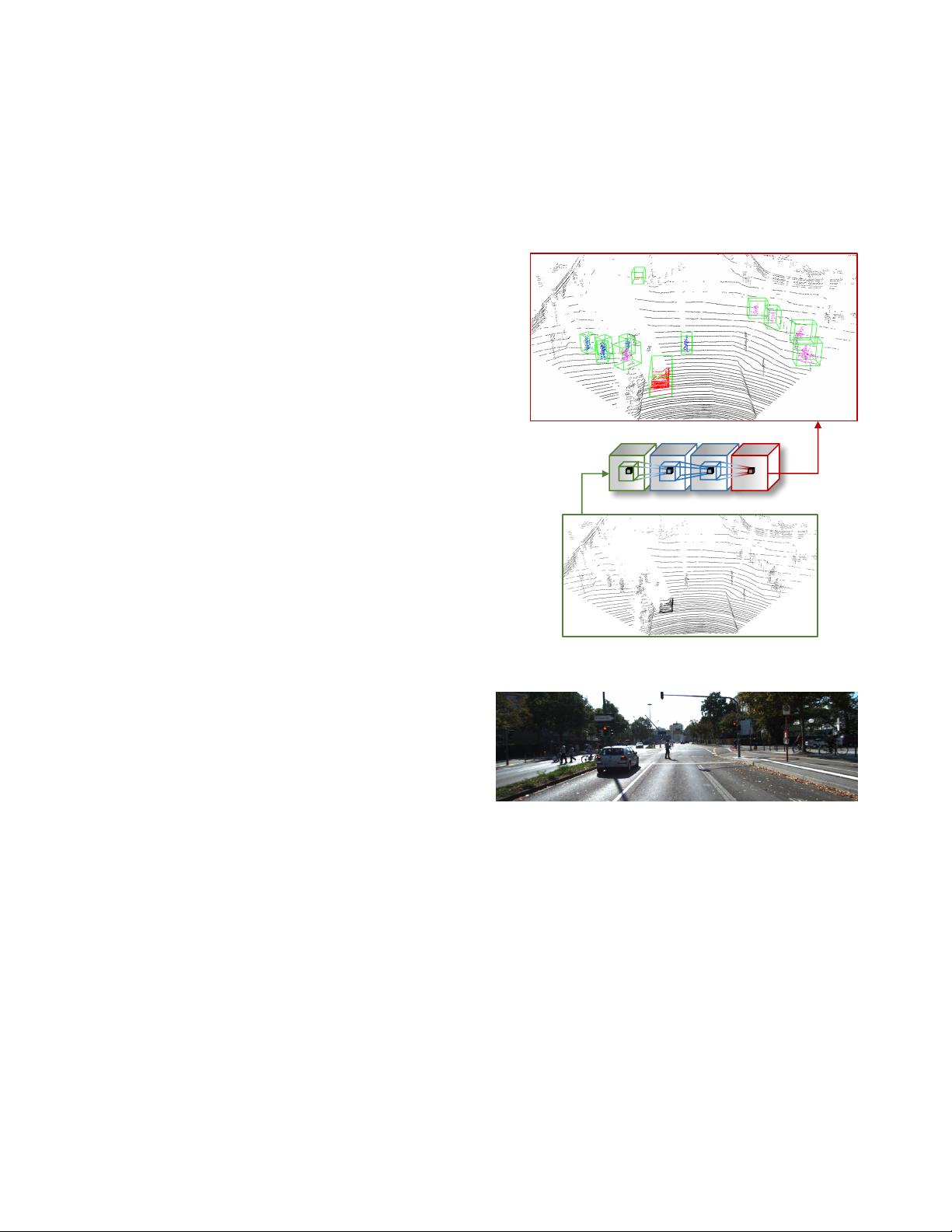
Fig. 1. The result of applying Vote3Deep to an unseen point cloud from
the KITTI dataset, with the corresponding image for reference. The CNNs
apply sparse convolutions natively in 3D via voting. The model detects cars
(red), pedestrians (blue), and cyclists (magenta), even at long range, and
assigns bounding boxes (green) sized by class. Best viewed in colour.
a linear Support Vector Machine (SVM). Consequently, [5]
achieves the previous state of the art in both performance and
processing speed for detecting cars, pedestrians and cyclists
in point clouds on the object detection task from the popular
KITTI Vision Benchmark Suite [6].
Inspired by [5], we propose to exploit feature-centric
voting to build efficient CNNs to detect objects in point
clouds natively in 3D – that is to say without projecting the
input into a lower-dimensional space first or constraining the
search space of the detector (Fig. 1). This enables our ap-
arXiv:1609.06666v2 [cs.RO] 5 Mar 2017
下载后可阅读完整内容,剩余6页未读,立即下载
249 浏览量
291 浏览量
2021-12-13 上传
2024-07-11 上传
186 浏览量
137 浏览量
164 浏览量
320 浏览量

lovefengqiang
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开








最新资源
- MFC绘图功能封装成DLL库的实现方法
- Ruby库实现特斯拉远程控制API文档
- Python代码实现详解与实践
- 深入理解C++Builder帮助文档——BCB6.HLP要点解析
- C#贪吃蛇游戏简易教程
- 电子商务平台Selenium自动化测试实战指南
- React开发Chrome扩展入门工具包:实现实时重新加载
- 西安Java招聘求职模板,后台管理系统界面设计
- C语言实现成绩分布图的顺序展示教程
- 全面掌握网站建设技术的W3C School离线教程
- VBA编程实例教程详解:方法与技巧
- Vagaa 2.6.6.7老版本发布,避免自动更新下载指南
- FirePHP扩展:在浏览器开发者工具中调试PHP
- Python编程练习示例解析
- 图片批量命名工具:高效统一文件命名解决方案
- Bink+Video+Player:Bik格式的视频播放解决方案






















