基于DSP的高速实时语音识别系统设计与实现
92 浏览量
更新于2024-09-01
1
收藏 173KB PDF 举报
"基于DSP的高速实时语音识别系统在单片机与DSP技术中扮演着重要角色,通过优化编程实现高效处理。"
在实时语音识别系统的设计中,由于语音信号的大量数据和复杂的运算需求,处理器的选择至关重要。数字信号处理器(DSP)因其高速处理能力和灵活性而成为理想的选择。TMS320C6713是一种常见的高性能DSP,它在语音识别应用中表现出色,能够有效地缩短识别时间,满足实时系统的需求。
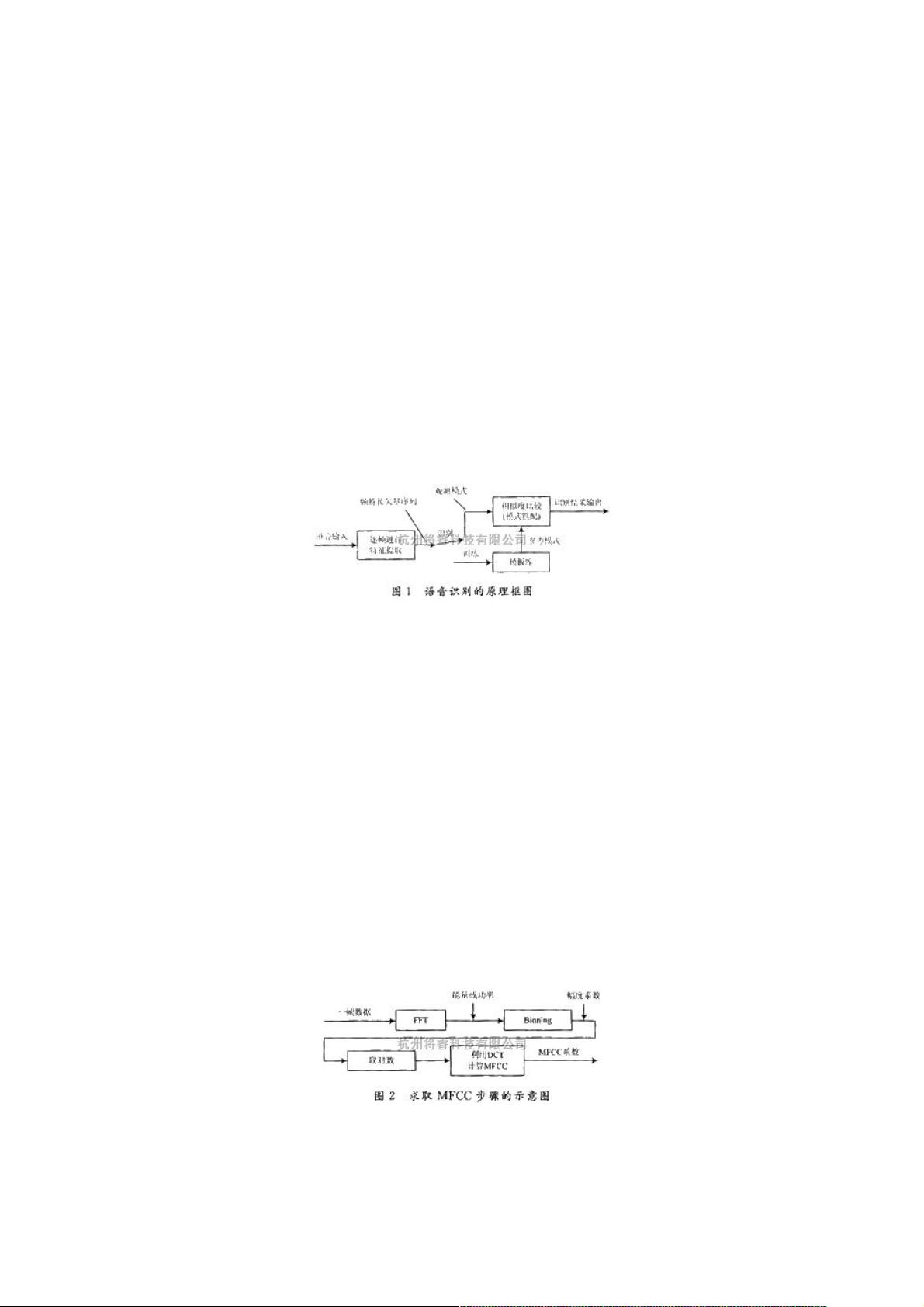
语音识别系统的核心在于从语音信号中提取关键信息,这一过程通常涉及特征提取。一个典型的语音识别系统原理如图1所示,它包括预处理、特征提取、建模和匹配等步骤。特征提取是系统的基础,目的是从复杂的语音信号中挑选出能有效区分不同语音模式的特征参数。
MFCC(梅尔频率倒谱系数)是语音识别中最常用的特征参数之一。它满足了特征参数的三个主要要求:能有效地反映语音特征、各阶参数间有良好独立性以及计算简便,适合实时识别。MFCC的计算流程大致分为以下几个步骤:
1. 对每一帧语音信号应用窗口函数,然后进行快速傅里叶变换(FFT),得到频域表示的幅度谱。
2. 将幅度谱与一组按照梅尔尺度排列的三角滤波器进行归一化,这个过程称为Binning。
3. 将Binning后的结果转换为对数尺度,模拟人耳对声音频率的感知。
4. 应用离散余弦变换(DCT)对对数谱进行变换,从而得到MFCC系数。通常会选取前几阶系数,例如本文中使用的12阶MFCC,以减少计算量并保留主要信息。
除了MFCC,系统可能还会结合其他特征,如过零率和差分能量,来增强识别性能。在实际应用中,如固定文本的说话人辨识,这种基于DSP的语音识别系统能显著提高准确性和响应速度。
在实现高速实时处理时,对DSP的优化编程至关重要。这包括了针对特定硬件结构的算法优化,如利用并行处理能力,以及内存访问策略的调整,以平衡存储容量和速度的需求。此外,合理的任务调度和中断管理也是保证系统实时性的关键因素。
基于DSP的高速实时语音识别系统是通过高效的硬件平台和优化的软件设计,来处理语音信号的复杂运算,实现快速且准确的识别。TMS320C6713 DSP在该领域提供了强大的支持,使得实时语音识别技术得以广泛应用。
单片机与单片机与DSP中的基于中的基于DSP的高速实时语音识别系统的设计的高速实时语音识别系统的设计
实时语音识别系统中,由于语音的数据量大,运算复杂,对处理器性能提出了很高的要求,适于采用高速DSP
实现。虽然DSP提供了高速和灵活的硬件设计,但是在实时处理系统中,还需结合DSP器件的结构及工作方
式,针对语音处理的特点,对软件进行反复优化,以缩短识别时间,满足实时的需求。因此如何对DSP进行优
化编程,解决算法的复杂性和硬件存储容量及速度之间的矛盾,成为实现系统性能的关键。本文基于
TMS320C6713设计并实现了高速实时语音识别系统,在固定文本的说话人辨识的应用中效果显著。 1 语音识别
的原理 语音识别的基本原理框图如图1所示。语音信号中含有丰富的信息,从中提取对语音识别有用的信息
的过程
实时语音识别系统中,由于语音的数据量大,运算复杂,对处理器性能提出了很高的要求,适于采用高速DSP实现。虽
然DSP提供了高速和灵活的硬件设计,但是在实时处理系统中,还需结合DSP器件的结构及工作方式,针对语音处理的特
点,对软件进行反复优化,以缩短识别时间,满足实时的需求。因此如何对DSP进行优化编程,解决算法的复杂性和硬件存
储容量及速度之间的矛盾,成为实现系统性能的关键。本文基于TMS320C6713设计并实现了高速实时语音识别系统,在固定
文本的说话人辨识的应用中效果显著。
1 语音识别的原理语音识别的原理
语音识别的基本原理框图如图1所示。语音信号中含有丰富的信息,从中提取对语音识别有用的信息的过程,就是特征提
取,特征提取方法是整个语音识别系统的基础。语音识别的过程可以被看作足模式匹配的过程,模式匹配是指根据一定的准
则,使未知模式与模型库中的某一模型获得最佳匹配。
1.1 MFCC
语音识别中对特征参数的要求是:
(1) 能够有效地代表语音特征;
(2) 各阶参数之间有良好的独立性;
(3) 特征参数要计算方便,保证识别的实时实现。
系统使用目前最为常用的MFCC(Mel FrequencyCepstral Coefficient,美尔频率倒谱系数)参数。
求取MFCC的主要步骤是:
(1) 给每一帧语音加窗做FFT,取出幅度;
(2) 将幅度和滤波器组中每一个三角滤波器进行Binning运算;
(3) 求log,换算成对数率;
(4) 从对数率的滤波器组幅度,使用DCT变换求出MFCC系数。
本文中采用12阶的MFCC,同时加过零率和delta能量共14维的语音参数。
1.2 DTW
语音识别中的模式匹配和模型训练技术主要有DTW(Dynamic Time Warping,动态时间弯折)、HMM(HideMarkov
Model,隐马尔科夫模型)和ANN(Artificial Neu-ral Network,人工神经元网络)。
DTW是一种简单有效的方法。该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别中出现较
下载后可阅读完整内容,剩余3页未读,立即下载
2009-10-03 上传
2020-10-21 上传
2020-12-10 上传
2020-11-08 上传
2020-12-06 上传
2020-12-10 上传
2020-12-10 上传
2020-12-08 上传
2020-11-08 上传

weixin_38632797
- 粉丝: 6
- 资源: 946
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
