精通Flink DataStream API:流处理概念与实战
版权申诉
"本资源详细介绍了Flink DataStream API的开发,旨在帮助学习者理解流处理的基本概念,掌握DataStream API的各个关键要素,包括source、transformation、sink算子的操作,水印机制,状态管理,容错机制,异步IO,端对端一次性语义,Streaming file sink的使用,以及如何进行Streaming综合案例开发。"
1. 流处理的基本概念:
流处理系统主要处理无限数据流,采用数据驱动的处理模式,通过预先设定的算子对到达的数据进行处理。Flink等分布式流处理引擎使用DAG(有向无环图)来表示计算逻辑,其中每个点代表一个算子。数据从Source节点流入,经过一系列算子间的处理,最终由Sink节点导出到外部系统。在分布式环境中,算子可能存在多个实例,数据传输可能涉及网络或本地通信。
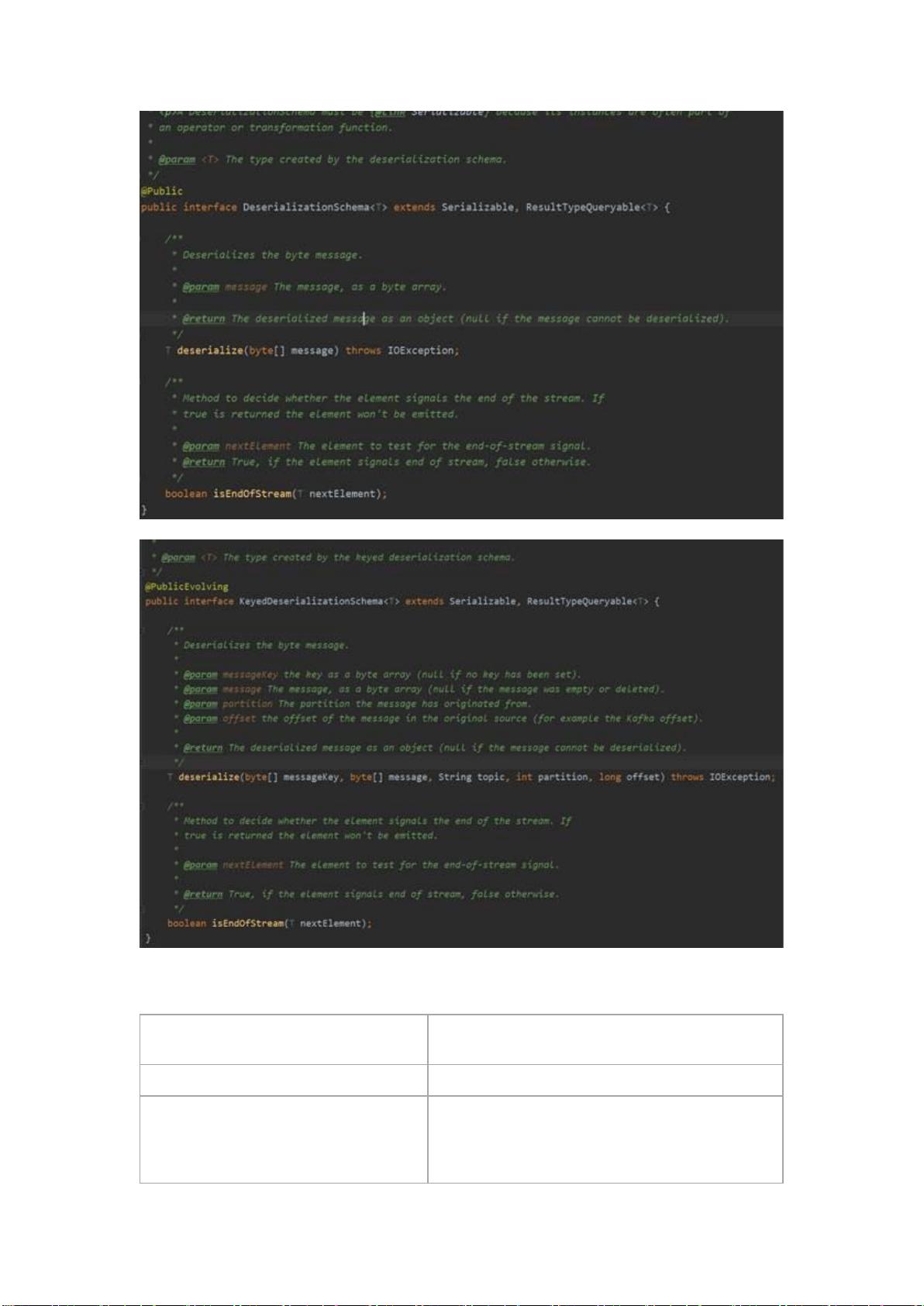
2. DataStream API的算子操作:
- Source:数据流的起点,负责从外部源读取数据,例如网络套接字、消息队列等。
- Transformation:对数据流进行转换,如map、filter、flatmap、keyBy等,定义数据处理逻辑。
- Sink:数据流的终点,将处理后的数据写入目标系统,如文件系统、数据库等。
3. 水印(Watermark)使用及其原理:
水印是处理事件时间的关键机制,用于处理乱序事件。它允许系统在某种程度上处理延迟到达的事件,确保最终的处理结果近似于事件的时间顺序。
4. 状态和容错机制:
Flink支持状态管理和容错,确保在系统故障时能够恢复计算状态。利用检查点(Checkpoint)和保存点(Savepoint),系统能够在不影响正常运行的情况下,保存并恢复计算状态,实现故障恢复和程序更新。
5. 异步IO的使用和原理:
异步IO允许在不阻塞主线程的情况下执行I/O操作,提高系统的并发性和效率。在Flink中,可以通过异步操作接口,如asyncWait,来实现非阻塞的I/O调用。
6. 端对端一次性语义(Exactly-once Semantics):
端对端一次性语义确保在系统故障后,即使处理过程重新执行,也能得到完全相同的输出结果。Flink通过事务化提交和状态一致性保障来实现这一语义。
7. Streaming file sink的使用:
Streaming file sink是Flink用来将数据持久化到文件系统的一种方式,如HDFS、S3等。它支持动态分区、压缩、滚动策略等功能,灵活适应不同的存储需求。
8. Streaming综合案例开发:
本资源还将涵盖如何结合以上知识点进行实际的流处理应用开发,提供从理论到实践的完整指南,帮助学习者掌握Flink在实际业务场景中的应用。
通过深入学习和实践这些知识点,学习者可以熟练掌握Flink DataStream API,从而在大数据处理领域游刃有余,解决各种实时流处理问题。

import java.util.UUID;
import java.util.concurrent.TimeUnit;
/**
* 使用多并行度的 source
*/
public class StreamingWithMyRichPralalleSourceDemo {
public static void main(String[] args) throws Exception {
//获取 Flink 的运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecuti
onEnvironment();
//获取数据源
DataStreamSource<Order> text = env.addSource(new MyRichParalleSource(
)).setParallelism(2);
//打印结果
text.print().setParallelism(1);
String jobName = StreamingWithMyRichPralalleSourceDemo.class.getSimple
Name();
env.execute(jobName);
}
}
/**
* 自定义实现一个支持并行度的 source
* RichParallelSourceFunction 会额外提供 open 和 close 方法
* 针对 source 中如果需要获取其他链接资源,那么可以在 open 方法中获取资源链接,
在 close 中关闭资源链接
*/
class MyRichParalleSource extends RichParallelSourceFunction<Order> {
private boolean isRunning = true;
/**
* 主要的方法
* 启动一个 source
* 大部分情况下,都需要在这个 run 方法中实现一个循环,这样就可以循环产生数据
了



剩余194页未读,继续阅读
2023-10-19 上传
2023-03-21 上传
点击了解资源详情
2023-03-16 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-07-17 上传

LENCIO0417
- 粉丝: 2
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
