布隆过滤器:海量数据高效判断与空间优化
需积分: 5 51 浏览量
更新于2024-08-03
收藏 1.1MB PDF 举报
布隆过滤器是一种高效的数据结构,用于在大规模数据集合中判断元素是否存在,特别适用于海量数据和频繁查询的场景。它由二进制向量(位数组)和一组随机映射函数(哈希函数)组成,通过计算元素的多个哈希值并将这些值对应的位置1来表示元素可能存在于集合中。
在处理大量元素时,传统的Collection的contain方法、Map的containsKey方法以及SQL的exists方法可能无法满足效率需求,因为它们的时间复杂度较高。而布隆过滤器的优势在于它的时间复杂度较低,约为O(k),其中k是哈希函数的数量。通过使用多个哈希函数,每个元素会产生多个哈希值,这些值被映射到位数组的不同位置,即使存储的是哈希值而非元素本身,也能节省大量的内存。
布隆过滤器的核心原理是利用位数组的状态来模拟元素可能存在的判断。状态一是当所有哈希函数对元素的映射都指向位数组中的1时,认为元素可能存在;状态二是当至少有一个哈希函数的映射指向0时,认为元素肯定不存在。然而,由于哈希函数的随机性,布隆过滤器存在误报(可能会错误地认为元素存在),但误报率可以通过调整位数组的长度(m)和哈希函数的数量(k)来控制。过小的m会导致误报率增高,而过多的k会降低效率。
在选择k和m时,需要找到一个平衡,确保误报率在可接受范围内。公式中,通常遵循一个经验公式,如m = (n * p) / (1 - p)^k,其中n是预计元素数量,p是期望的最大误报率。
布隆过滤器的优点包括:
1. 空间效率:相比其他数据结构,它能存储更多元素,占用较少的内存。
2. 高效查询:通过并行计算哈希值,查询速度较快。
缺点则在于:
1. 不确定性:判断结果不是绝对的,存在误报。
2. 删除困难:一旦数据插入,就无法删除,因为无法确认元素是否真的存在。
布隆过滤器的应用场景广泛,比如:
1. 缓存穿透防护:标记数据库中不存在的值,避免恶意请求导致的缓存雪崩。
2. 去重:在推荐系统中,可以用于检查用户已浏览的历史内容,减少重复推荐。
在实践中,可以手动实现布隆过滤器,如使用位图(位数组)存储哈希值,或者利用编程语言如Java中的Guava库提供的现成布隆过滤器实现,只需引入相关的包并设置put方法进行元素添加。
总结来说,布隆过滤器是一种高效的数据结构解决方案,尤其适用于大数据场景下的元素存在性判断,但需要权衡误报率和空间/时间效率之间的关系。
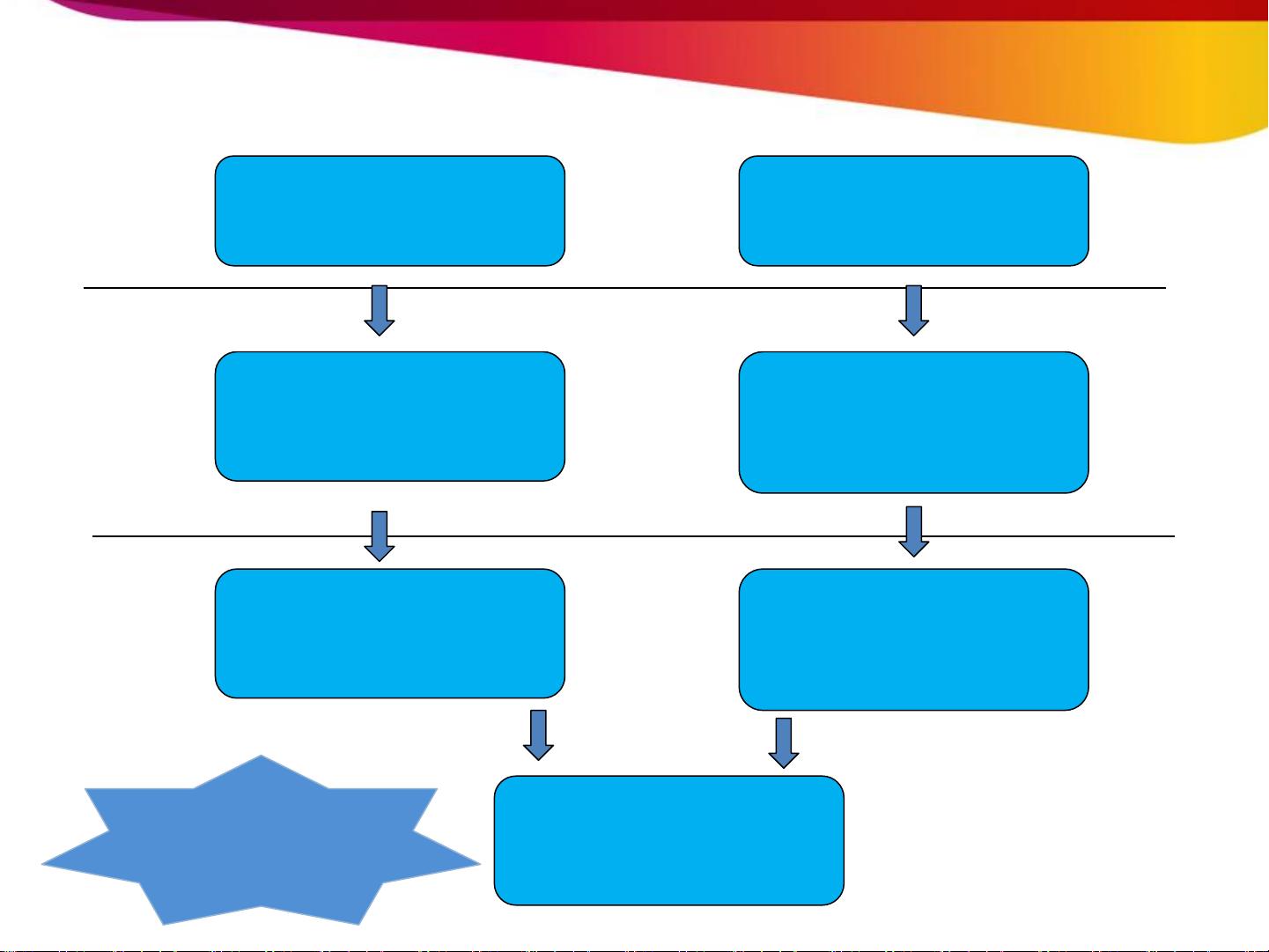
如何解决
海量数据中判断是否
存在的效率问题?
海量数据的内存占用
大的问题?
hashmap在查询时利
用哈希值直接找到哈
希桶,具有高效率
存储时,可以不存储
元素本身,可以存储
元素的哈希值
采用多个哈希函数,
可以让一个元素生成
多个哈希值
利用将位数组对应位
置置1的方式,存储多
个哈希值
布隆过滤器
问
题:
思
路:
解决
方
式:
将元素抽象为
该元素多个哈
希函数的结果
剩余13页未读,继续阅读
2022-06-06 上传
2019-08-14 上传
点击了解资源详情
2022-01-10 上传
2024-04-24 上传
2024-01-18 上传
2021-10-26 上传
2022-11-18 上传

我喜欢山,也喜欢海
- 粉丝: 23
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 13J913-1 公共厨房建筑设计与构造.rar
- N10SG模块手册.zip
- reqscraper:轻量级包装,用于Request和X-Ray JS
- simplyarch:在您选择要膨胀还是不膨胀的情况下安装Arch Linux的最简单方法
- Fork_Socket:Linux多进程服务器和客户端
- S32K1_FlexNVM:演示仿真EEPROM模块的用法
- matlab代码对齐-MATLAB:MATLAB学习笔记
- pyg_lib-0.3.1+pt20-cp311-cp311-macosx_11_0_universal2whl.zip
- sp0cket
- magic-frontend
- UIGoogleMaps:Coursera UIGoogleMaps 项目已修改为使用 Android Studio 进行编译。 确保您的 SDK 中安装了最新的 Google 存储库和 Google Play 服务。 可以在 https 找到原始来源
- MixRamp-开源
- CLRS:CLRS解决方案,包括C ++中的代码
- PROYECTOINGSOFT2
- 基于LSTM网络的外汇预测模型.zip
- i
