Spark MLlib:用户画像构建与机器学习课件资源
需积分: 5 127 浏览量
更新于2024-06-18
1
收藏 4.42MB PDF 举报
Spark MLlib是Apache Spark中的一个核心模块,专注于机器学习(Machine Learning)和数据挖掘(Data Mining)功能。它是Spark生态系统中的一个重要组成部分,为大数据处理提供了强大的工具支持,尤其是在分布式环境下进行高效的学习和预测任务。
在第十章和第十一章的内容中,主要围绕Spark MLlib的用户画像应用展开讲解。用户画像,作为数据分析的重要工具,它通过对用户的各种社会属性、消费行为、偏好等多维度数据进行收集、整理和分析,形成用户的抽象表示,有助于企业更好地理解用户,做出精准的运营决策和市场策略。
1. 用户画像的定义与应用
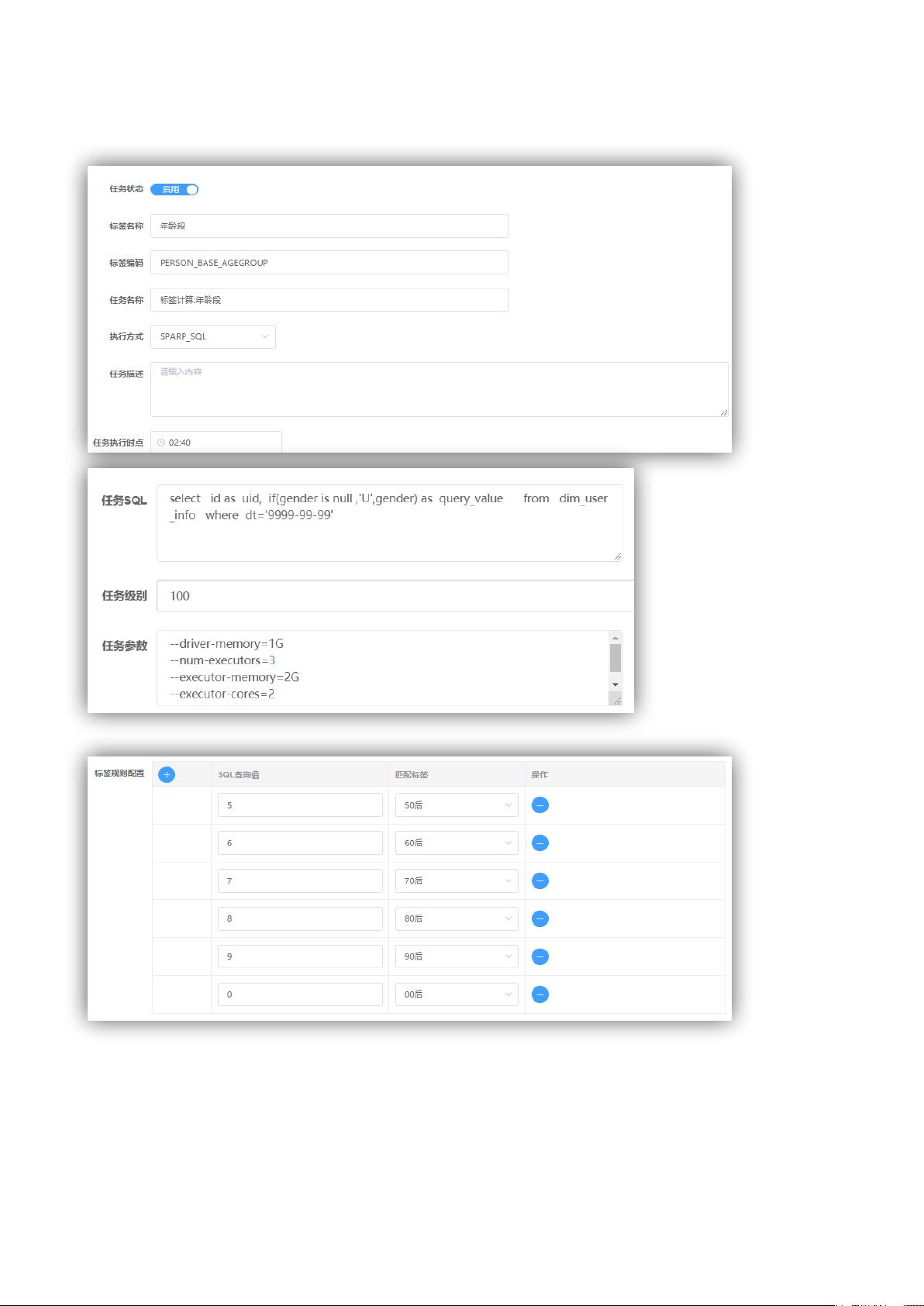
- 用户画像是一套综合性的用户特征描述,通过事实标签(如性别、年龄、消费记录等)、规则标签(由企业内部规则定义的用户类别,如高价值用户、意见领袖等)以及挖掘类标签(如预测的用户属性或行为,如潜在流失用户)来刻画用户。用户画像在运营决策、精准营销和用户分群等方面发挥关键作用,帮助企业聚焦目标市场、个性化推荐以及挽留用户。
2. 用户画像的构建方法
- 统计类标签基于直接提取的数据,具有明确的定义;规则类标签则需要根据企业特定业务规则制定;挖掘类标签则依赖机器学习算法,通过模型预测来获取,虽然开发周期长且可能不够精确,但价值极高,因为它能揭示隐藏在数据背后的深层次信息。
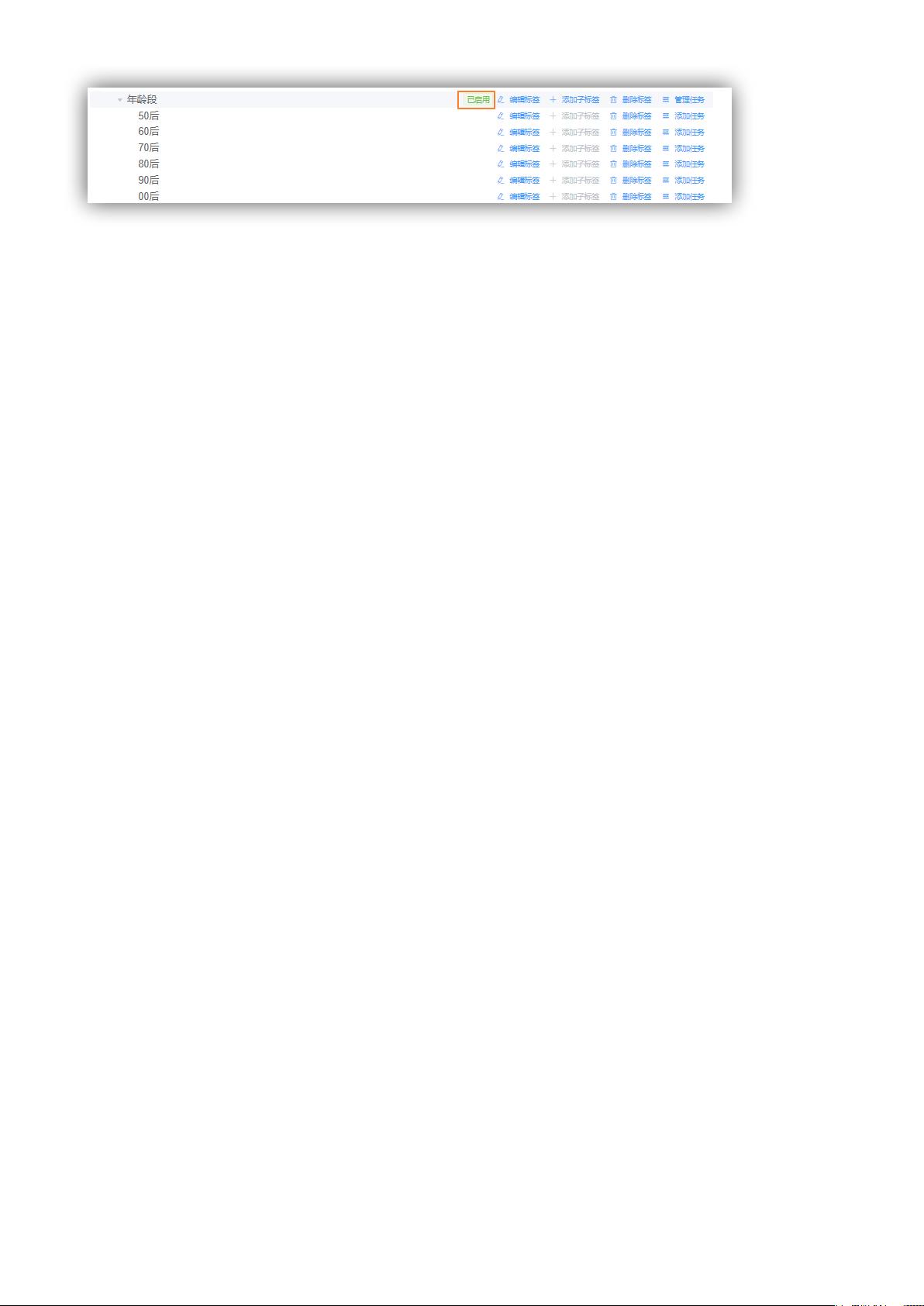
3. 用户画像管理平台
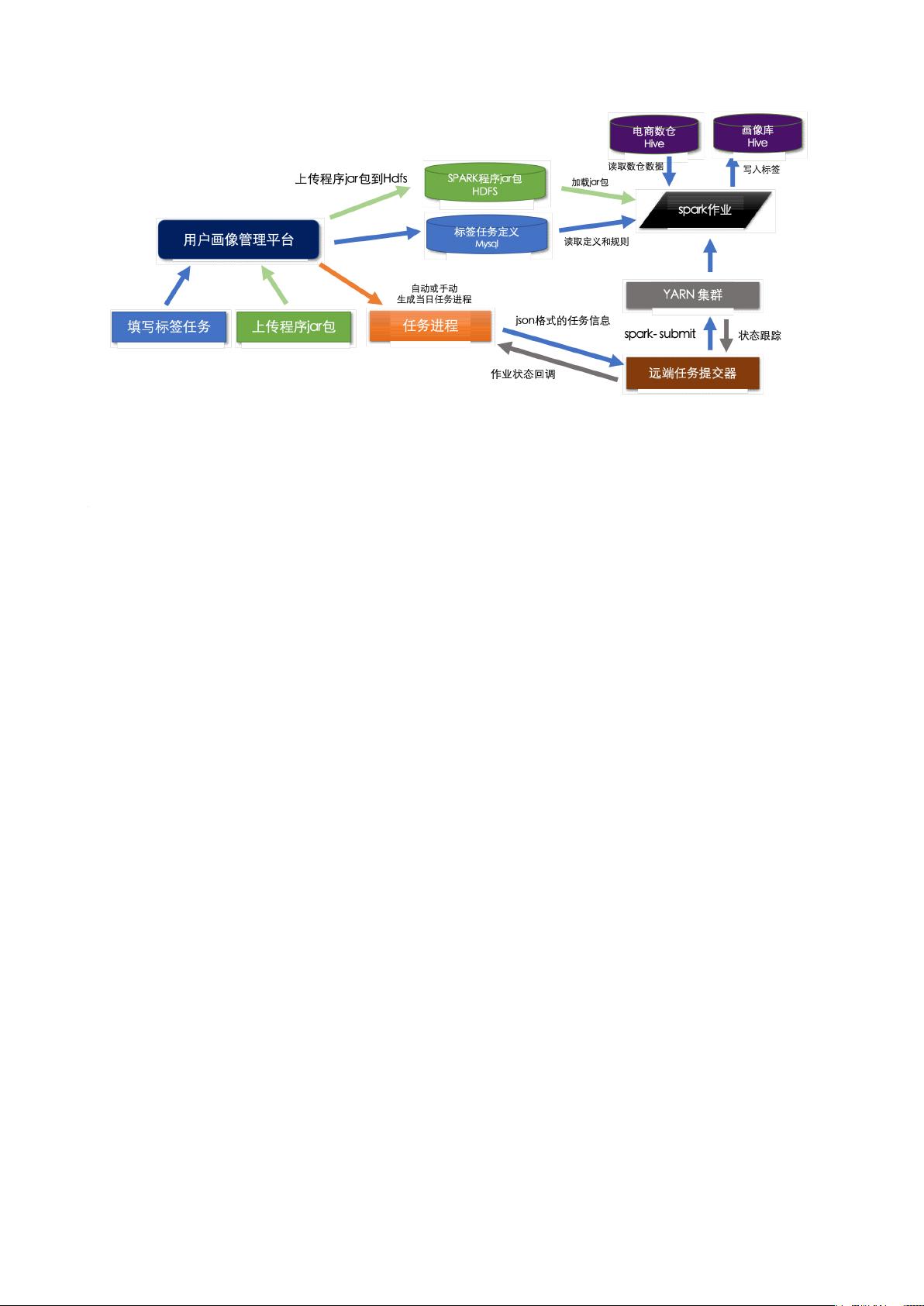
- 提供了可视化界面,便于用户定义和管理标签,包括规则设定和实时监控。平台还整合了后台调度系统,自动化地从数据仓库中抽取和计算用户画像,实现数据驱动的用户细分。这有助于企业快速响应市场变化,优化运营策略。
4. 结构和实践
- 用户画像的架构通常涉及数据采集、预处理、特征工程、模型训练和结果展示等步骤。在Spark MLlib的支持下,可以利用分布式计算能力加速模型训练,处理海量数据。此外,用户画像的持续优化也依赖于数据的实时更新和模型的迭代调整。
Spark MLlib配套课件资源深入介绍了如何利用Spark的机器学习能力构建用户画像,这对于任何希望在大数据背景下提升用户理解和营销效果的企业来说,都是一份宝贵的实战指南。通过理解和应用这些内容,企业能够更有效地利用数据资产,提升客户体验和业务效能。

点击了解资源详情
2018-04-04 上传
2017-12-22 上传
2021-01-07 上传
2023-06-06 上传
2023-03-16 上传
2023-07-13 上传
2023-07-13 上传
2023-08-31 上传

lastinglate
- 粉丝: 74
- 资源: 26
 我的内容管理
展开
我的内容管理
展开







最新资源
- 机载相控阵雷达信号模拟器的设计
- loadRunner开发手册
- vss 基础教程 (基础概念,服务器端,客户端等)
- 2006年下半年软件水平考试下午试卷
- 高重频PD雷达导引头抗距离遮挡技术
- 非均匀采样信号重构技术及其在PD雷达HPRF信号处理中的应用
- 2006年下半年软件水平考试上午试卷
- 弹载无线电寻的装置的基本体制
- 单脉冲雷达导引头仿形技术
- 如何理解C和C++复杂类型声明
- C#帮忙文档C#入门基础
- java初学者使用资料
- python 精要参考
- 访问控制资源文献-PEI模型
- Weblogic Admin Guide
- Actualtests Oracle 1Z0-042 V03.27.07.pdf
