LevelDB高级特性概述:高效写入与内存管理
需积分: 0 43 浏览量
更新于2024-08-05
收藏 349KB PDF 举报
LevelDB是由Google开发的一款高效的关键值(Key-Value)数据库,专为大规模数据处理而设计,能够处理十亿级别数据量。它具备以下关键特性:
1. **数据模型与存储**:
- LevelDB支持任意类型的byte数组键值对,不仅限于字符串,提供了灵活性。
- 数据持久化,主要数据存储在磁盘上,保证数据的安全性和可靠性。
- 按照键值的自然顺序进行存储,同时也支持自定义排序,这有助于优化查询性能。
2. **操作接口**:
- 提供基础的增删改查操作,如Write、Put、Delete,以及原子性的批量操作,简化了数据管理。
- 支持数据快照功能,读取操作与写操作隔离,确保一致性。
- 数据压缩(Snappy)用于减少存储空间占用和提高I/O效率。
3. **性能特性**:
- LevelDB强调写操作的性能,通常写入比读取更快,而顺序读写优于随机读写。
- 由于其底层设计,需要用户自行封装网络服务器,不直接支持客户端连接,类似于NoSQL数据库。
4. **并发与并发控制**:
- LevelDB一次仅允许一个进程访问特定数据库,以防止并发冲突。
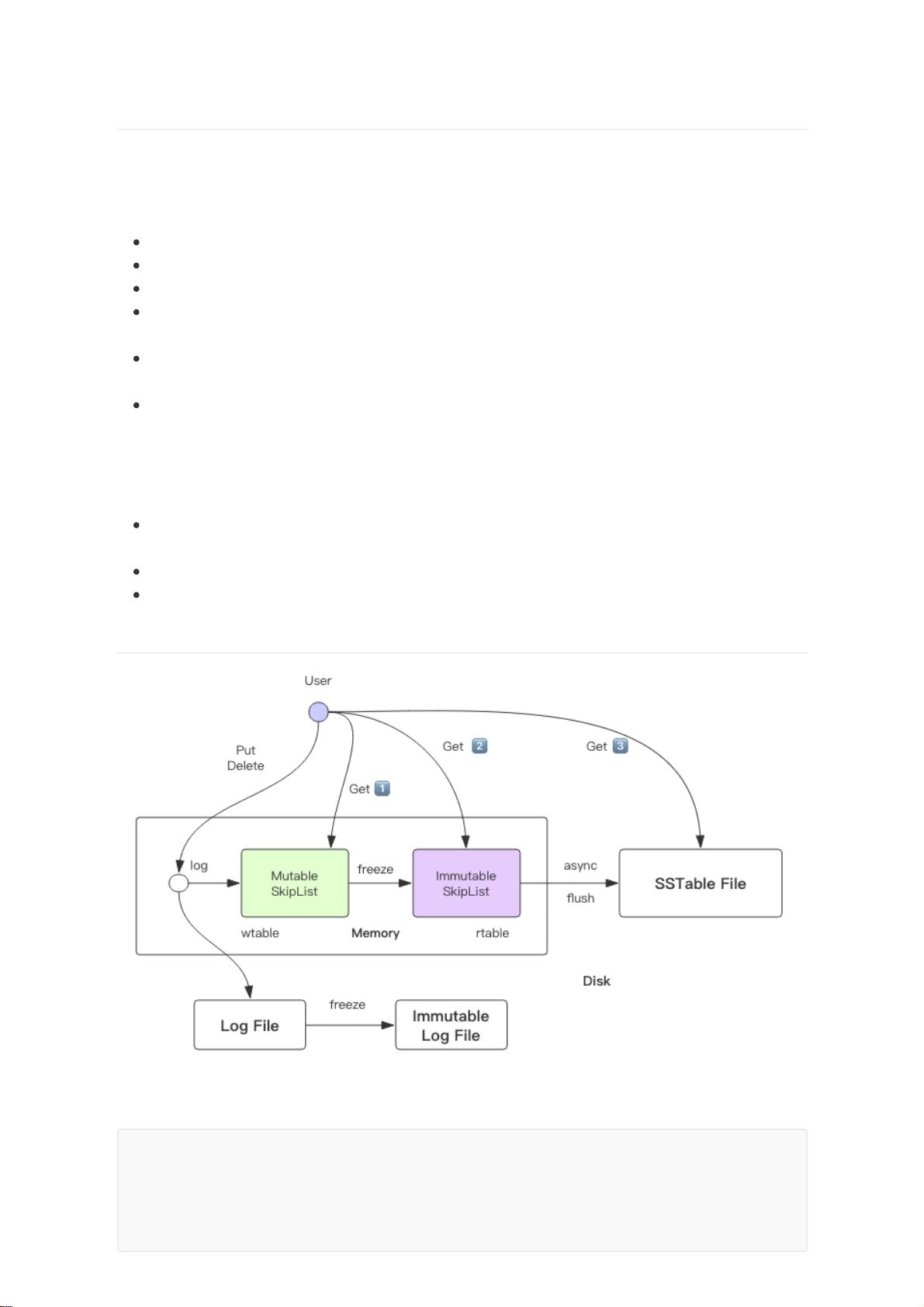
- 存储在内存中的数据结构有MemTable(使用SkipList实现的多级结构),wtable支持多线程读写,通过加锁机制保证并发控制。
5. **数据结构**:
- SkipList是一种数据结构,类似于有序集合,只包含键,不包含值。这对于查找操作特别有效。
- 在wtable中,删除操作实际上不是物理删除,而是通过增加一个标记(Node)来表示已删除。
6. **工作流程**:
- 当wtable的大小超过预设阈值,它会被转换为只读表rtable,由后台线程异步地将数据持久化到磁盘。
总结来说,LevelDB是一个高性能、低延迟的键值存储库,适用于需要大量写操作且不依赖复杂SQL查询的场景。然而,它的设计要求用户自己实现服务器集成,适合对性能有高要求的系统开发者使用。
leveldb 简介
Leveldb是一个google实现的非常高效的kv数据库,能够支持billion级别的数据量了。
特点
key、value支持任意的byte类型数组,不单单支持字符串。
LevelDb是一个持久化存储的KV系统,将大部分数据存储到磁盘上。
按照记录key值顺序存储数据,并且LevleDb支持按照用户定义的比较函数进行排序。
操作接口简单,基本操作包括写记录,读记录以及删除记录,也支持针对多条操作的原子批量操
作。
支持数据快照(snapshot)功能,使得读取操作不受写操作影响,可以在读操作过程中始终看到一
致的数据。
支持数据压缩(snappy压缩)操作,有效减小存储空间、并增快IO效率。
总体来说,LevelDb的写操作要大大快于读操作,而顺序读写操作则大大快于随机读写操作。
限制
LevelDB 只是一个 C/C++ 编程语言的库, 使用者应该封装自己的网络服务器。 所以无法像一般意义
的存储服务器(如 MySQL)那样, 用客户端来连接它。
非关系型数据模型(NoSQL),不支持sql语句,也不支持索引。
一次只允许一个进程访问一个特定的数据库。
leveldb 的架构
User 代表客户端,提供增删改查功能
virtual Status Put(const WriteOptions&, const Slice& key, const Slice& value);
virtual Status Delete(const WriteOptions&, const Slice& key);
virtual Status Write(const WriteOptions& options, WriteBatch* updates);
virtual Status Get(const ReadOptions& options, const Slice& key, std::string*
value);
下载后可阅读完整内容,剩余5页未读,立即下载
2018-01-04 上传
2021-10-03 上传
2013-07-24 上传
2021-06-14 上传
2022-09-23 上传
2022-05-14 上传
2019-10-20 上传
2023-04-28 上传
2022-09-19 上传

家的要素
- 粉丝: 28
- 资源: 298
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握压缩文件管理:2工作.zip文件使用指南
- 易语言动态版置入代码技术解析
- C语言编程实现电脑系统测试工具开发
- Wireshark 64位:全面网络协议分析器,支持Unix和Windows
- QtSingleApplication: 确保单一实例运行的高效库
- 深入了解Go语言的解析器组合器PARC
- Apycula包安装与使用指南
- AkerAutoSetup安装包使用指南
- Arduino Due实现VR耳机的设计与编程
- DependencySwizzler: Xamarin iOS 库实现故事板 UIViewControllers 依赖注入
- Apycula包发布说明与下载指南
- 创建可拖动交互式图表界面的ampersand-touch-charts
- CMake项目入门:创建简单的C++项目
- AksharaJaana-*.*.*.*安装包说明与下载
- Arduino天气时钟项目:源代码及DHT22库文件解析
- MediaPlayer_server:控制媒体播放器的高级服务器
