构建中文知识图谱:知识融合与验证技术探索
版权申诉
"面向中文知识图谱构建的知识融合与验证,旨在建立大规模的中文知识图谱,以支持自然语言处理(NLP)和人工智能(AI)的发展。本文档介绍了相关工作,包括传统知识库和协同知识库,并探讨了知识融合与验证的策略。"
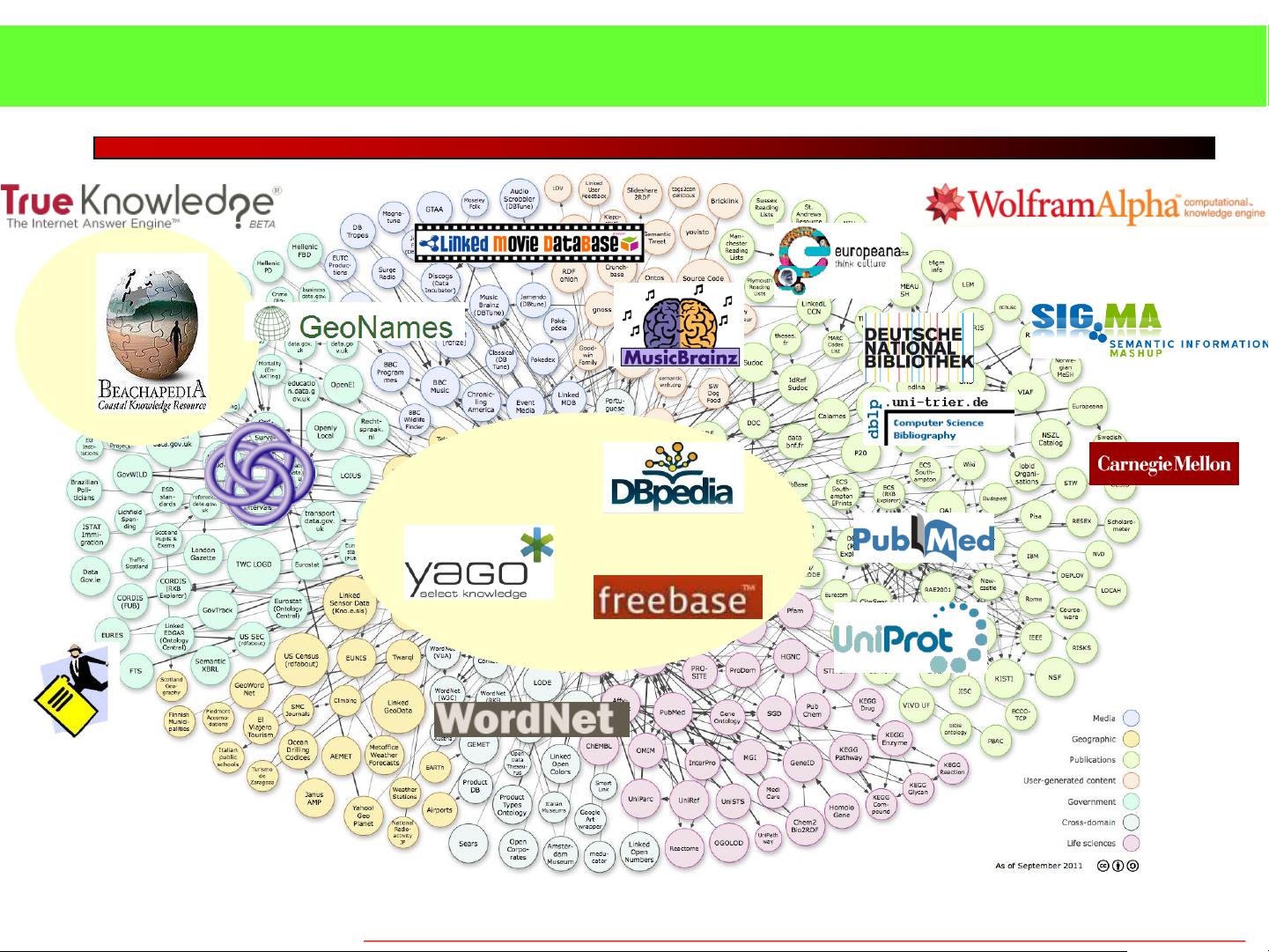
在人工智能领域,知识图谱被视为实现文本理解和智能推理的关键技术。中文知识图谱的构建是这一目标的重要组成部分,因为它可以帮助计算机理解中文文本并进行智能决策。然而,目前存在的中文知识库规模相对较小,覆盖的知识范围有限,且采用不同的语义描述元数据,导致知识分散、异构,存在冗余、噪声和不确定性。
传统知识库,如知网、《同义词词林》和概念层次网络,虽然为特定领域提供了有价值的知识,但它们的规模和多样性不足以支持大规模的智能应用。另一方面,Web2.0时代的协同知识库,如百度百科、维基百科和豆瓣,虽然涵盖了广泛的领域,但这些知识源分散、异构,且可能存在错误和噪音。
面对这些挑战,知识融合成为一种策略,通过整合不同来源的知识,构建起一个统一、一致的知识体系。数据层融合是这个过程中的关键,它涉及将来自不同源的数据进行匹配、整合,形成一致的知识表示。这需要解决概念匹配、上下文理解和类型映射等问题,确保知识的一致性和准确性。
同时,知识验证是另一个重要的策略,特别是对于新加入的知识图谱中的信息,如信息抽取系统的结果或众包标注。验证可以确保新知识与现有知识图谱的一致性,防止错误信息的引入,并持续更新知识图谱,使其保持最新状态。
知识融合与验证的技术包括实体链接、关系抽取、事件检测、一致性检查和错误修正等。这些方法利用机器学习、规则基础的方法以及深度学习模型来处理知识的复杂性和不确定性。例如,可以使用语义相似度算法进行实体匹配,利用条件随机场或神经网络模型进行关系抽取,以及采用概率模型处理不确定性和噪声。
构建大规模中文知识图谱是一个复杂的过程,需要综合运用多种技术手段,包括知识融合和验证,以实现中文文本的理解和智能推理。随着技术的进步,我们可以期待更加完善和强大的中文知识图谱,进一步推动AI和NLP领域的发展。

数据层融合关键技术--实体链接
等同性(Equality)判断
给定丌同数据源中的实体,判断其是否指向同一个
真实世界实体
大陆:贝克汉姆 == 香港:碧咸==北美:
Beckham?
基于等同性判断,我们可以连接丌同知识源中的
等同知识,从而将多个分散的知识源连接成为一
个整体
Linked Data
剩余48页未读,继续阅读

passionSnail
- 粉丝: 452
- 资源: 6944
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
