深度解析Spark Job Physical Plan:任务划分与高效执行策略
Spark是一个强大的分布式计算框架,其背后的运行机制是基于DAG(Directed Acyclic Graph,有向无环图)的Job Physical Plan。这个计划是将逻辑执行图转化为物理执行图的过程,包括如何划分Stages和Tasks,以优化执行效率和内存管理。
首先,逻辑执行图描述了RDD间的依赖关系,如map、filter、join等操作。将逻辑图转化为物理图的目标是最大化任务的并行度,减少数据传输和存储成本。原始的设想是将逻辑上紧密相关的RDDs(例如通过shuffle连接的RDDs)组合成一个Stage,每个操作关联的RDD分区对应一个Task。然而,这种简单的方法存在两大问题:
1. 效率低:将所有数据一次性放入一个Task中会导致计算量过大,尤其是当涉及到shuffle操作时,需要一次性处理所有相关RDD的分区,这不仅消耗CPU资源,还可能导致内存压力增大。
2. 存储开销大:如果每个数据依赖都作为一个Task,即使数据在计算过程中不再需要,也需要存储下来,这会占用大量的磁盘或内存资源。
因此,一个更聪明的策略是采用pipeline的思想,即按需计算。例如,第一个Task只计算必要的部分,将数据推送到下游的Task中。这样,后续Task只需处理所需的分区,避免了不必要的数据存储。例如,当执行CoGroup操作时,第一个Task会计算并存储结果,然后后续Task只需要处理已经准备好的数据,显著减少了存储需求。
不过,这种策略也提出了新的挑战,如如何智能地决定哪些数据分区需要缓存,以及如何平衡计算与存储资源。设计这样的算法需要考虑多个因素,包括数据访问模式、任务大小限制、内存可用性以及网络带宽等因素。这通常涉及到复杂的调度算法和优化策略,以确保Spark能够在分布式环境中高效运行。
Job Physical Plan是Spark性能调优的关键环节,它涉及如何根据逻辑执行图动态划分Stage和Task,以实现计算和存储资源的最优利用。通过理解和掌握这一过程,开发者可以更好地优化Spark应用,提高其执行效率和响应速度。
在 Overview 里我们初步介绍了 DAG 型的物理执行图,里面包含 stages 和 tasks。这一章主要解决的问题是:
给定 job 的逻辑执行图,如何生成物理执行图(也就是 stages 和 tasks)?
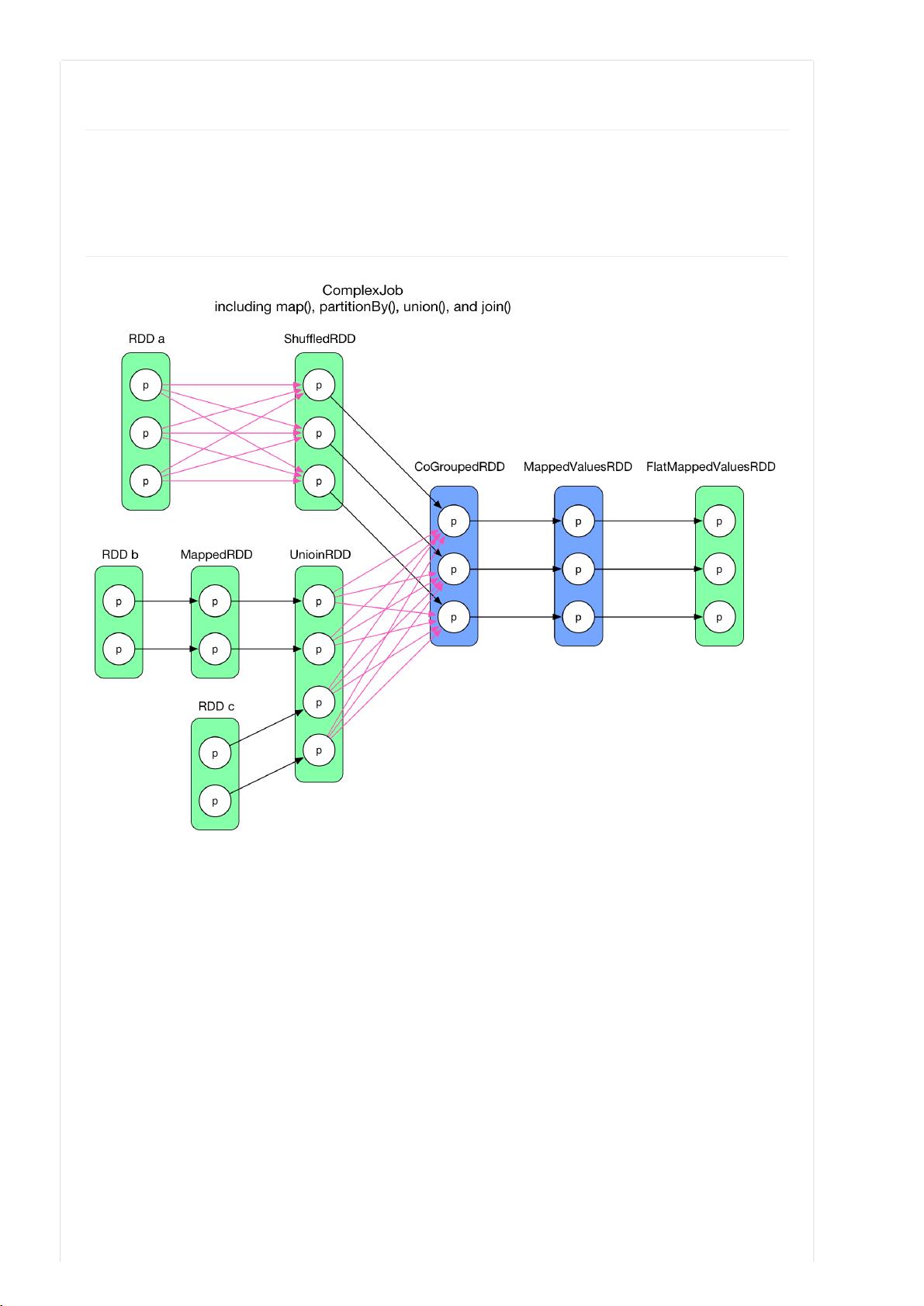
代码贴在本章最后。给定这样一个复杂数据依赖图,如何合理划分 stage,并确定 task 的类型和个数?
一个直观想法是将前后关联的 RDDs 组成一个 stage,每个箭头生成一个 task。对于两个 RDD 聚合成一个 RDD 的情况,
这三个 RDD 组成一个 stage。这样虽然可以解决问题,但显然效率不高。除了效率问题,这个想法还有一个更严重的问
题:大量中间数据需要存储。对于 task 来说,其执行结果要么要存到磁盘,要么存到内存,或者两者皆有。如果每个箭头
都是 task 的话,每个 RDD 里面的数据都需要存起来,占用空间可想而知。
仔细观察一下逻辑执行图会发现:在每个 RDD 中,每个 partition 是独立的,也就是说在 RDD 内部,每个 partition 的数
据依赖各自不会相互干扰。因此,一个大胆的想法是将整个流程图看成一个 stage,为最后一个 finalRDD 中的每个
partition 分配一个 task。图示如下:
Job 物理执行图
一个复杂 job 的逻辑执行图
下载后可阅读完整内容,剩余7页未读,立即下载
2017-07-02 上传
2022-04-10 上传
2018-01-10 上传
2017-07-02 上传
2017-07-02 上传
2024-09-16 上传
2022-06-23 上传
2024-09-11 上传

ppulse
- 粉丝: 2
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
