HDFS高可用(HA)配置:Namenode主备安装教程
需积分: 41 73 浏览量
更新于2024-07-18
收藏 671KB DOCX 举报
"HDFS分布式安装(HA)"
在构建高可用(HA)的Hadoop HDFS系统中,安装namenode的主备模式是至关重要的。这个过程涉及到多台服务器的配置,确保在主namenode出现故障时,备用namenode能够无缝接管,保证服务的连续性。以下是对HDFS namenode主备安装的详细步骤和关键知识点的解释:
首先,一个高可用的HDFS部署至少需要三台机器,这是因为要设置Zookeeper集群来监控和管理namenode的状态切换。Zookeeper是一个分布式协调服务,它在HDFS HA中扮演着重要角色,负责检测namenode的状态并决定何时进行主备切换。
在每台机器上,你需要安装三个Zookeeper实例以构成一个最小的Zookeeper集群。Zookeeper的奇数个节点设置是为了避免在集群中出现平票情况,从而确保决策的确定性。
接下来,需要安装两个namenode实例,通常分别被称为active namenode和standby namenode。它们共享同一份命名空间信息,但只有一个处于活动状态处理用户请求。standby namenode持续与active namenode保持同步,以便在需要时快速接管。
此外,还需要安装至少三个journalnode(推荐奇数个),这些journalnode组成了一个日志服务集群。active namenode会将所有的元数据更改写入journalnodes,standby namenode则通过这些journalnodes获取最新的命名空间修改,保证数据的一致性。
在硬件资源方面,namenode的内存需求与数据规模和集群规模直接相关。据估计,每一百万条数据大概需要1GB的内存峰值,但最终实际使用可能会低于这个值。
在安装过程中,确保先卸载系统自带的OpenJDK,然后安装Oracle JDK。这一步是必要的,因为Hadoop通常与Oracle JDK有更好的兼容性。具体的卸载和安装步骤包括查询已安装的Java版本、卸载OpenJDK、将JDK安装包放置在指定目录、解压缩、移动到/usr/java目录下,以及配置环境变量。
在`/etc/profile`文件中添加JDK的路径到`JAVA_HOME`、`CLASSPATH`和`PATH`变量中,并通过`source /etc/profile`命令使改动生效。完成这些配置后,便可以开始HDFS的安装和配置,包括设置HDFS相关的配置文件(如`hdfs-site.xml`),定义Zookeeper地址,namenode的主备角色,以及journalnode的相关信息。
在启动HDFS服务之前,还需要初始化和格式化命名空间。最后,启动HDFS的所有组件,包括datanode、resourcemanager、nodemanager等,并进行健康检查,确保所有服务都正常运行。
HDFS namenode的主备安装涉及多个步骤,包括Zookeeper和journalnode的配置,JDK的安装,环境变量设置,以及HDFS相关配置的调整。这一过程旨在确保在namenode故障时,系统的可用性和数据完整性不受到影响。
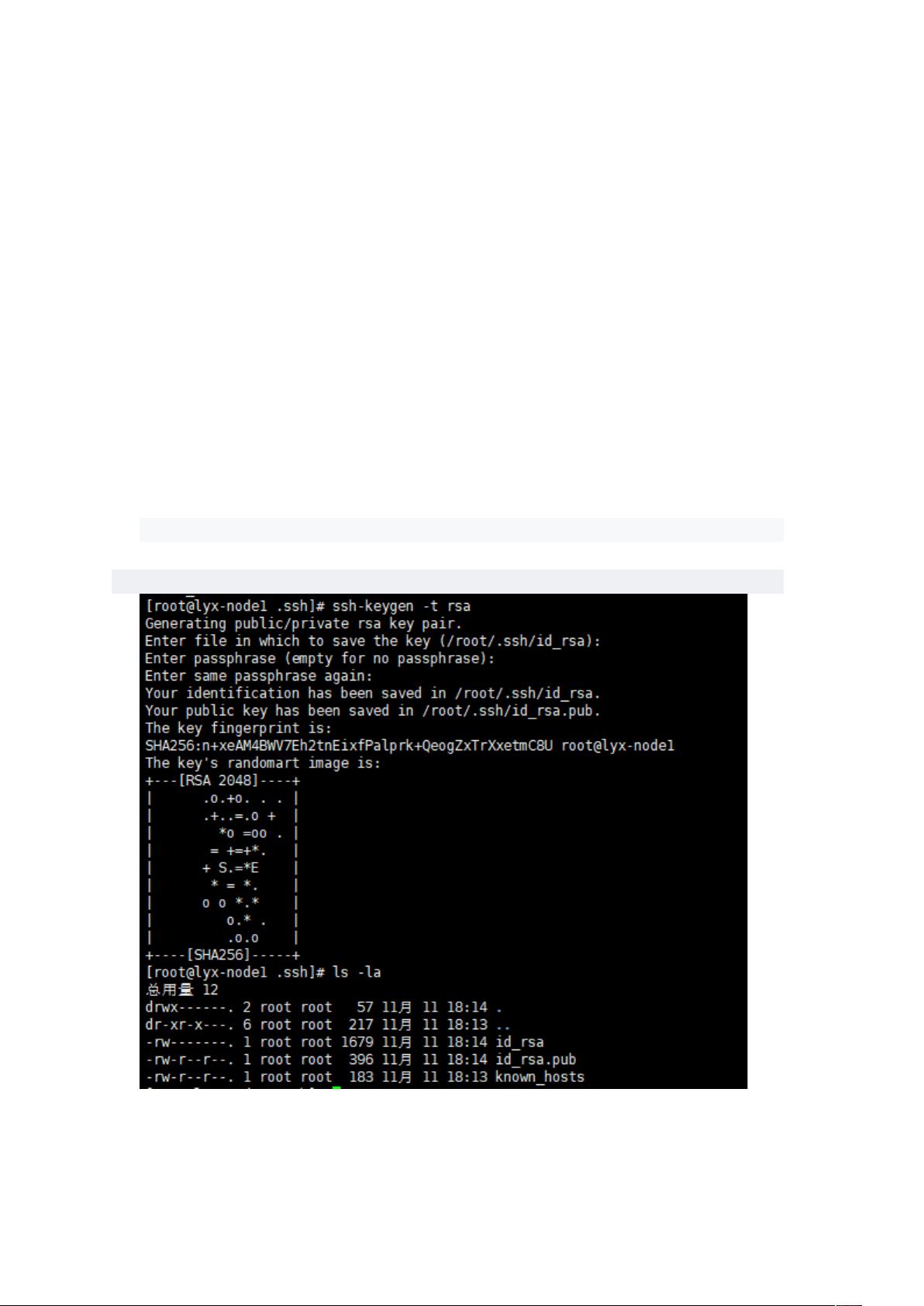
4.配置 SSH 无密码登录
思路:通过 B4 加密算生成了密钥,包括私钥和公钥,我们把公钥追加到用来认证授权的
中去。
每台机器配置本地免密登录,然后将其余每台机器生成的C')$'!2) 公钥内容追加到
其 中 一 台 主 机 的 $!2 中 , 然 后 将 这 台 机 器 中 包 括 每 台 机 器 公 钥 的
$!2 文件发送到集群中所有的服务器。这样集群中每台服务器都拥有所有服务
器的公钥,这样集群间任意两台机器都可以实现免密登录了。
1.第一台机器(node1)
ssh-keygen -t rsa
1
需要进入到.ssh 目录
剩余18页未读,继续阅读
点击了解资源详情
2023-03-17 上传
2023-03-16 上传
2023-03-16 上传
2023-06-06 上传
2023-06-05 上传
2023-06-28 上传

iroving
- 粉丝: 2
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
