STM32F7与STM32F4复位序列差异解析
需积分: 29 150 浏览量
更新于2024-09-07
收藏 258KB PDF 举报
"STM32单片机资料,包含STM32F7与STM32F4的复位序列比较"
STM32系列单片机,尤其是STM32F7和STM32F4,因其高性能和广泛应用,在嵌入式开发领域备受欢迎。STM32F7基于更先进的Cortex-M7内核,而STM32F4则是基于Cortex-M4,这两者在复位序列上有显著的区别。
STM32F4的复位过程遵循Cortex-M3/M4的标准,系统在复位后会从0x00000000地址开始执行,这里存放的是主堆栈指针(MSP)的初始值,接着从0x00000004地址取出PC的初始值,即复位向量,然后程序从这个地址开始运行。中断向量表(IVT)的第一个表项是MSP,第二个是复位向量,其余表项按照顺序分别为NMI、Hard Fault等异常处理程序和各个中断服务函数的起始地址。在STM32F4中,中断向量表默认位于0地址,但可以通过修改系统控制寄存器(SCB)中的VTOR(Vector Table Offset Register)寄存器来重定位中断向量表,适应IAP(In-Application Programming)等场景的需求。
然而,STM32F7引入了新的变化。由于采用了Cortex-M7内核,其复位序列有所不同。首先,0地址不再是主程序的入口,而是被用来存放ITCM(In-System Tight Coupled Memory)RAM的起始地址。这意味着在STM32F7中,系统复位后并不直接从0地址开始执行,而是遵循Cortex-M7的复位流程。在Cortex-M7中,复位序列可能涉及到更复杂的内存管理,包括数据和指令缓存的初始化,以及可能存在的硬件加速器的配置。
STM32F7的复位后,处理器会从一个特定的地址开始执行,这个地址通常由芯片厂商在出厂时预设,用于执行必要的初始化步骤。一旦完成这些步骤,程序才会跳转到用户代码的入口点。这与STM32F4不同,后者复位后直接从0地址开始执行用户代码。在STM32F7中,开发者需要了解并适应这种变化,确保程序的正确引导。
总结来说,STM32F7与STM32F4在复位序列上的主要区别在于,STM32F7的0地址不再用于存放复位向量,而是用于ITCMRAM,而STM32F4则依然遵循Cortex-M4的传统复位流程。因此,在开发STM32F7项目时,必须考虑到这一差异,以便正确地配置程序的入口点和中断处理。同时,对Cortex-M7内核的新特性如数据和指令缓存的管理也要有深入的理解,以充分发挥STM32F7的性能优势。
STM32F7 与 STM32F4 复位序列比较
前言
初次接触到 STM32F7,总会有个疑惑,为什么 0 地址变成了 ITCM RAM 的起始地址。系统复位还是从地址 0 处开始执行
吗?如果是,那这似乎看起来是冲突的。实际上,STM32F7 基于 Cortex-M7 内核,Cortex-M7 和 Cortex-M3/M4 的复位序列
有了一些不一样。在本文中,将针对这个问题做详细讲解。
STM32F4 的复位序列
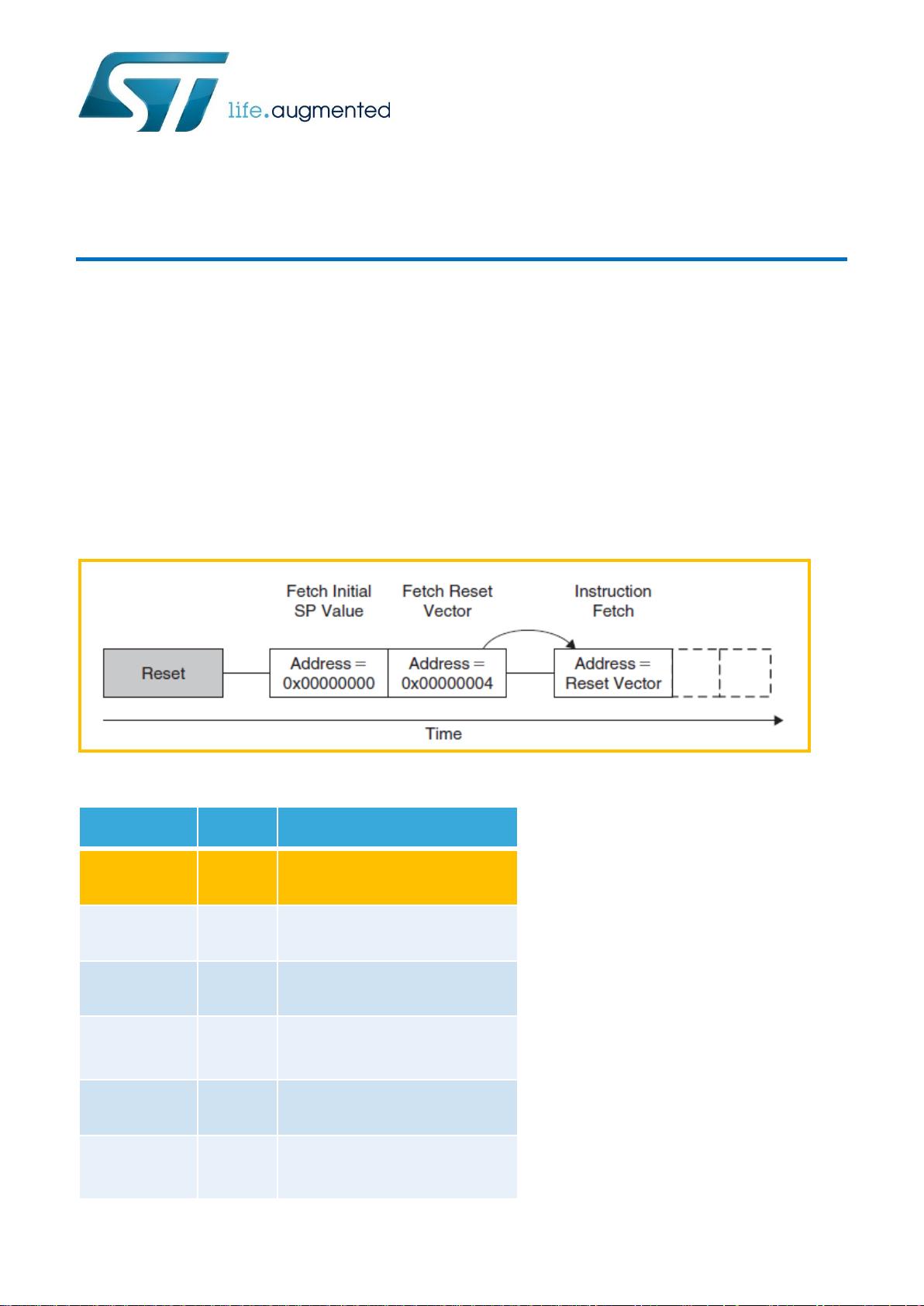
STM32F4 基于 Cortex-M4。对于基于 Cortex-M3/M4 的芯片,复位后总是从 0x00000000 地址处,取主堆栈指针(MSP)的
值,从 0x00000004 处,取出 PC 的初始值(这个值是复位向量),然后从这个值对应的地址处取指。
这两个值,就是中断向量表里的第一个和第二个表项的值。
地址
编号
值(4 字节大小)
0x00000000
0
MSP 初始值
0x00000004
1
复位向量地址
0x00000008
2
NMI 异常处理程序起始地址
0x0000000C
3
硬 fault 异常处理程序起始地
址
……
……
……
0x00000040
16
IRQ#0 中断处理程序起始地
址
下载后可阅读完整内容,剩余3页未读,立即下载
140 浏览量
2025-01-11 上传
3554 浏览量
369 浏览量

luolunchi
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- render_async实现Rails页面的快速异步渲染
- 易语言模块实现定时提醒功能
- MyBatis 3.3.1 新特性:批量插入支持及主键ID返回
- Garry的Mod错误报告与安全漏洞私报指南
- 基于MATLAB实现网络摄像机视频录制技术
- 探索Chrome扩展:chrome-extension-samples项目分析
- 毕业论文乳胶模板:使用TeXmaker高效编写
- 掌握ArcGIS API for JS的椭圆采集技巧
- 使用React JS和Webpack构建WebApp开发指南
- 易语言模块实现完全进制转换功能
- Infinite Scroll插件:自动加载下一页的实现
- LINUX动态库.so二次封装与嵌套技术解析
- LeetCode算法题解及分类总结
- 双鱼林JSP人事工资系统源码及资料下载
- 探索GitHub上的HTML项目进展
- 易语言日期处理源码包:高效罗列与管理
