处理不确定数据库的Top-k查询
"这篇论文探讨了在不确定数据库中处理Top-k查询的问题,提出了新的概率性公式化方法,并构建了一个框架,以应对不确定数据环境中的挑战。该框架结合了传统Top-k语义和可能世界语义,确保了在访问元组数量和物质化搜索状态方面的优化。实验结果显示,与直接物质化的方法相比,提出的技巧在不同数据分布下具有显著的效率提升。"
在不确定数据库中,Top-k查询处理是一个关键问题,因为传统的处理方法在面对数据不确定性时不再适用。不确定性引入了一种新的层面,即结果的可信度和概率性。传统的Top-k查询通常寻找数据库中评分最高的k个元素,但在不确定数据库中,每个数据项都有一个概率分布,这使得确定哪些元素实际上是前k个变得复杂。
论文作者Mohamed A. Soliman、Ihab F. Ilyas和Kevin Chen-Chuan Chang提出了一种新的概率性公式化方法,将传统的Top-k查询语义与可能世界理论相结合。可能世界语义允许我们考虑所有可能的数据实例,而不仅仅是当前观察到的不确定实例。这种“婚姻”式的结合使得在不确定环境中定义查询结果的排名和选择变得更加合理。
为了处理这些挑战,他们构建了一个框架,该框架基于状态空间模型,可以高效地执行查询。这个框架的关键在于它能够有效地管理不确定性,减少对数据库元组的访问次数,同时最小化需要物质化的搜索状态。通过这种方式,他们保证了在不确定数据集上的查询性能。
此外,作者证明了他们的技术在访问的元组数量和物质化状态方面是优化的,这意味着在处理不确定数据时,它们能够以最少的计算资源获取最准确的结果。实验部分展示了这些技术在各种数据分布下的高效性,与直接物质化整个数据集的传统方法相比,性能提升了几个数量级。
这篇论文对于理解和解决不确定数据库中的Top-k查询问题提供了重要的理论基础和实用解决方案,对于处理现实世界中广泛存在的不精确或模糊数据具有重要意义。
Top-k Query Processing in Uncertain Databases
Mohamed A. Soliman Ihab F. Ilyas
School of Computer Science
University of Waterloo
{m2ali,ilyas}@uwaterloo.ca
Kevin Chen-Chuan Chang
Department of Computer Science
University of Illinois at UrbanaChampaign
kcchang@cs.uiuc.edu
Abstract
Top-k processing in uncertain databases is semanti-
cally and computationally different from traditional top-k
processing. The interplay b etween score and uncertainty
makes traditional techniques inapplicable. We introduce
new probabilistic formulations for top-k queries. Our for-
mulations are based on “marriage” of traditional top-k se-
mantics and possible worlds semantics. In the light of these
formulations, we construct a framework that encapsulates a
state space model and efficient query processing techniques
to tackle the challenges of uncertain data settings. We prove
that our techniques are optimal in terms of the number of
accessed tuples and materialized search states. Our exper-
iments show the efficiency of our techniques under different
data distributions with orders of magnitude improvement
over na
¨
ıve materialization of possible worlds.
1 Introduction
Efficient processing of uncertain (probabilistic) data is a
crucial requirement in different domains including sensor
networks [21, 8], moving objects tracking [7, 9] and data
cleaning [12, 3]. Several probabilistic data models have
been proposed, e.g., [10, 11, 4, 15, 16, 2 0, 2], to capture data
uncertainty at different levels. According to most of these
models, tuples have membership probability, e.g., based on
data source reliability [13], or fuzzy query predicates, a s ad-
dressed in [18]. Tuple attributes could a lso contain multiple
values drawn from discrete or continuous domains [20, 6],
e.g., a set of possible customer names in a dirty database, or
an interval of possible sensor readings.
Many uncertain data models, e.g., [15, 2, 20], adopt
possible worlds semantics, where an uncertain relation is
viewed as a set of possible instances (worlds). The struc-
ture of these worlds could be governed by underlying gen-
eration rules, e.g., mutual exclusion of tuples that represent
the same real-world entity. Such rules could arise naturally
with unclean data [13, 3], or could be customized to en-
force application requirements, reflect domain semantics, or
maintain lin eage and data inter-dependencies [ 5, 20]. The
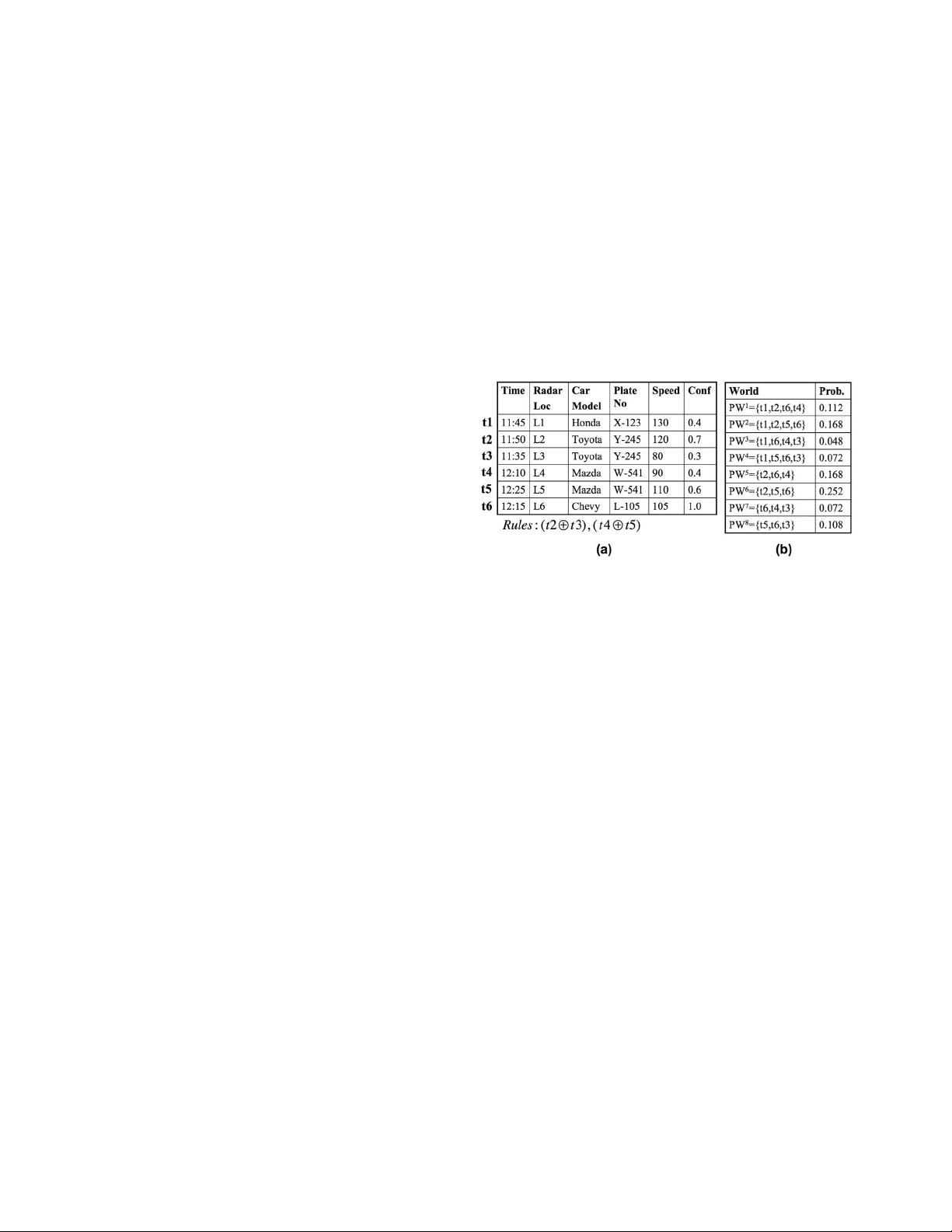
Figure 1. Uncertain Database and Possible
Worlds Space
following is a running example for an uncertain database
that we use in this paper.
Example 1 Consider a radar-controlled traffic, where car
speed readings are stored in a database. Radar units detect
speed automatically, while car identification ,e.g., by plate
number, is usually performed by a human operator. In this
database, multiple sources of errors (uncertainty) exist. For
example, radar readings can be interfered by high voltage
lines, close by cars cannot be precisely distinguished, or
human operators might make identification mistakes. Fig-
ure 1(a) is a snapshot of a radar database in the last hour.
Each reading is associated with a confidence field “conf”
indicating its membership probability. Based on radar lo-
cations, the same car cannot be detected by radars at two
different locations within 1 hour interval. This constraint is
captured by the indicated exclusiveness rules.
1.1 Uncertain Data Model
The uncertain data model we adopt is based on possi-
ble worlds semantics with two pillars. The first pillar is
membership uncerta inty, where each tuple belongs to the
database with a probability, hereafter called confidence.
The second p illar is generation rules, which are arbitrary
logical formulas that determine valid worlds. Tuples that
are correlated with no rules are called independent.
1-4244-0803-2/07/$20.00 ©2007 IEEE. 896
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐





lcx87
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Web远程教学系统需求分析指南
- 禅道6.2版本发布,优化测试流程,提高安全性
- Netty传输层API中文文档及资源包免费下载
- 超凡搜索:引领搜索领域的创新神器
- JavaWeb租房系统实现与代码参考指南
- 老冀文章编辑工具v1.8:文章编辑的自动化解决方案
- MovieLens 1m数据集深度解析:数据库设计与电影属性
- TypeScript实现tca-flip-coins模拟硬币翻转算法
- Directshow实现多路视频采集与传输技术
- 百度editor实现无限制附件上传功能
- C语言二级上机模拟题与VC6.0完整版
- A*算法解决八数码问题:AI领域的经典案例
- Android版SeetaFace JNI程序实现人脸检测与对齐
- 热交换器效率提升技术手册
- WinCE平台CPU占用率精确测试工具介绍
- JavaScript实现的压缩包子算法解读
