数据结构基础:排序算法详解与冒泡排序优化
需积分: 9 94 浏览量
更新于2024-07-14
收藏 10.88MB DOCX 举报
数据结构是计算机科学中的基础概念,它涉及如何组织和管理数据,以便更有效地进行存储、访问和操作。在本文档中,主要讨论了数据结构中的基本算法,特别是排序算法,这是数据处理中的关键部分。排序算法根据其操作方式可以分为两类:内部排序和外部排序。
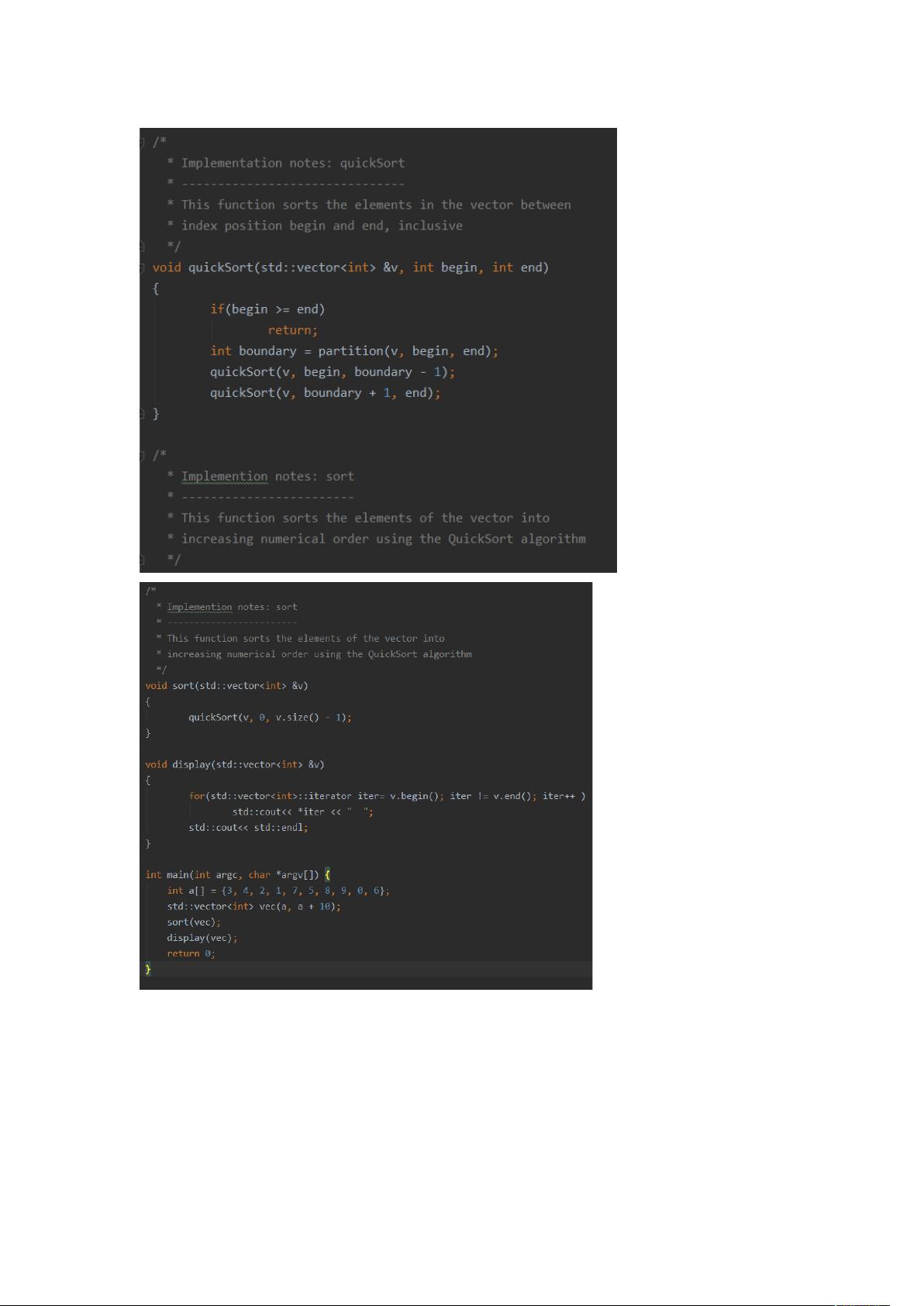
内部排序是指对内存中的数据进行排序,常见的内部排序算法有冒泡排序、插入排序、希尔排序、选择排序、快速排序、堆排序和归并排序。冒泡排序是一种简单直观的算法,它通过反复交换相邻元素来逐步提升最大或最小值至序列末尾。虽然冒泡排序的时间复杂度在最坏情况下是O(n^2),但通过引入鸡尾酒排序(一种改进的冒泡排序,包含两遍扫描,一次从左到右,一次从右到左)可以优化效率,使其平均性能有所提高。选择排序则是每次都找到剩余部分的最大(小)值,并将其放到已排序部分的末尾,这也属于O(n^2)的时间复杂度。
外部排序适用于数据量过大无法一次性加载到内存的情况,通常将数据分块处理,每个子文件或段在内存中排序后合并。这个过程涉及到多个步骤,如分割、排序、合并,最终生成有序文件。稳定的排序算法指的是在排序过程中相等的元素保持原有的相对顺序,如冒泡排序和插入排序。
总结来说,数据结构基本算法整理文档详细介绍了这些核心算法的工作原理、优缺点以及实现代码示例,这对于理解数据处理中的基本操作和优化策略至关重要。学习和掌握这些算法,可以帮助程序员设计出高效、稳定的程序,以适应不同规模的数据处理需求。
#include <iostream>
#include <vector>
#include <unistd.h>
using namespace std;
int quickSort(vector<int> &arr,int l,int r)
{
int len = r+1;


剩余63页未读,继续阅读
2022-07-11 上传
2022-07-13 上传
2022-06-16 上传
2021-12-27 上传
2021-10-10 上传
2019-05-13 上传
2021-12-19 上传
2019-09-23 上传

xiannvlei
- 粉丝: 18
- 资源: 22
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
