大数据组件对比:Pulsar vs Kafka,FlinkCDC vs Debezium,数据湖三剑客解析
需积分: 5 49 浏览量
更新于2024-08-04
收藏 2.48MB PDF 举报
"大数据技术组件选型对比.pdf"
大数据技术组件在现代数据分析和处理中起着至关重要的作用。本文主要对比了几种关键的大数据组件,包括消息中间件Pulsar与Kafka,数据同步工具Flink CDC与Debezium,以及数据湖解决方案Databricks、Iceberg和Hudi。
首先,Pulsar与Kafka作为流行的消息中间件,各自拥有其特点。Pulsar以其强大的流处理能力和灵活的数据同步机制脱颖而出,支持DataStream API和SQL同步数据,使得数据处理更为方便,尤其适合需要进行ETL操作的场景。同时,Pulsar的分布式架构不仅提供了水平扩展能力,还增强了对分布式系统的接入,比如与Hive、HDFS、Iceberg、Hudi等大数据存储系统的集成。相比之下,DataX和Debezium在数据同步上可能需要用户编写脚本或模板,增加了使用难度。
接着,Flink CDC是一个高效的数据同步工具,其分布式架构不仅限于数据读取能力,还能很好地适应大数据场景下的系统接入。Flink CDC支持众多数据库和数据源的连接,如TiDB、MySQL、Pg、HBase、Kafka和ClickHouse等,提供了丰富的Connector选择。这与传统工具如Debezium相比,降低了用户使用门槛。
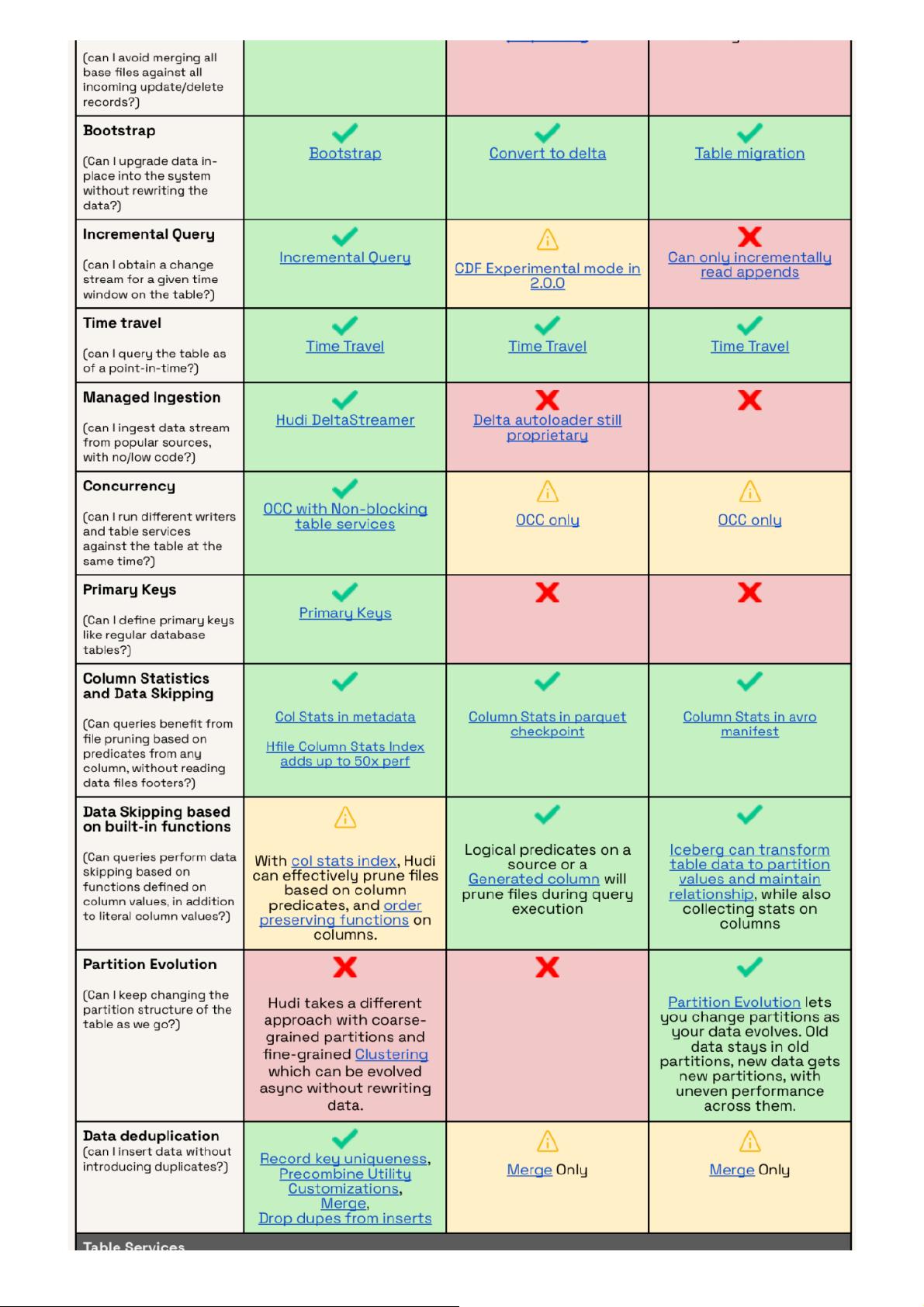
在数据湖领域,Databricks的ChangeDataFeed和Iceberg、Hudi各有特色。Iceberg的增量读取功能虽强大,但缺乏更新和删除操作,对于变更数据捕获和事务数据处理存在局限。而Apache Iceberg的隐藏分区特性,允许分区演进,以优化性能,但也带来了复杂性,尤其是对分区演进历史不熟悉的情况下。Hudi则通过其多模式索引子系统,实现了高性能索引,支持异步构建和更改,兼容多种索引技术,并且元数据以优化格式存储,点查找性能显著提升,这对于处理大规模数据时的查询效率至关重要。
大数据组件选型需考虑具体业务需求、性能需求以及生态支持。例如,如果项目中需要高度灵活的数据同步和ETL操作,Flink CDC可能是更好的选择;如果关注数据湖的高性能查询,Hudi的索引系统可能更合适。每个组件都有其优势和适用场景,全面理解它们的特点是做出明智决策的关键。
剩余13页未读,继续阅读
2022-11-29 上传
2022-01-13 上传
2022-11-11 上传
2021-11-17 上传
2022-06-21 上传
2024-05-25 上传
2024-11-21 上传

毕设小程序软件程序猿
- 粉丝: 159
- 资源: 655
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
