腾讯TDW实践:Hive在大数据分析中的应用
需积分: 10 28 浏览量
更新于2024-07-24
收藏 1.07MB PDF 举报
"HIVE在腾讯分布式数据仓库的实践分享"
在腾讯的分布式数据仓库(TDW)中,HIVE扮演着关键角色,它是一个基于Hadoop的查询和数据管理系统,专为大规模数据集设计。HIVE提供了SQL-like的查询语言,使得非编程背景的用户也能方便地对大数据进行分析。在TDW中,HIVE经过定制和优化,以适应腾讯的业务需求,包括数据挖掘、产品报表和经营分析等。
TDW是腾讯内部最大的分布式系统,集成了各个业务的数据,提供离线海量数据分析服务。其特性包括:
1. 存储和计算容灾:即使集群中部分节点故障,也不影响数据的存储和计算,确保系统的高可用性。
2. 线性扩展:通过增加硬件节点,可以线性扩展存储和计算能力,以应对数据量的增长。
3. SQL支持:提供丰富的SQL操作,如select、insert、join、where、groupby等,以及各种函数,满足多样化的查询需求。
4. 过程语言:基于Python的PL/python,用于编写复杂的数据处理逻辑。
5. 多维分析:支持rollup、cube和grouping等操作,便于进行多角度的数据透视分析。
6. MapReduce集成:用户可以直接在HIVE中提交MapReduce任务,利用并行计算处理大数据。
7. 多种存储结构:包括文本、结构化、列存储、ProtoBuf和DB存储,适应不同的数据类型和性能需求。
8. SQL/MED:可以访问和管理PostgreSQL、Oracle等外部数据库,实现数据源的统一管理。
9. 开发工具:提供TDWIDE集成开发环境和PLClient命令行工具,提高开发效率。
10. 任务调度系统:图形化配置任务依赖和数据流转,自动化执行分析任务。
11. 其他功能:如showprocesslist、killquery、selectexpr、insert values等操作,增强系统的易用性和管理性。
TDW的核心架构由HIVE、MapReduce、HDFS和PostgreSQL组成,其中HIVE负责将SQL语句转化为MapReduce任务或PostgreSQL查询,MapReduce处理并行计算,HDFS提供分布式存储,而PostgreSQL则用于小规模数据的存储和计算。
截至分享时,TDW已拥有5000+台机器,覆盖腾讯90%以上的产品,活跃的TDW集成开发环境用户超过200人,每天执行的分析SQL达到50000+,生成的MRjob数量超过100000,且在过去的半年里,服务的SLA达到了99.99%,显示出极高的稳定性和效率。
通过这些实践,我们可以看出,HIVE在腾讯的分布式数据仓库中起到了关键的桥梁作用,它简化了大数据分析的复杂性,提高了工作效率,同时也为腾讯的业务决策提供了强有力的数据支持。
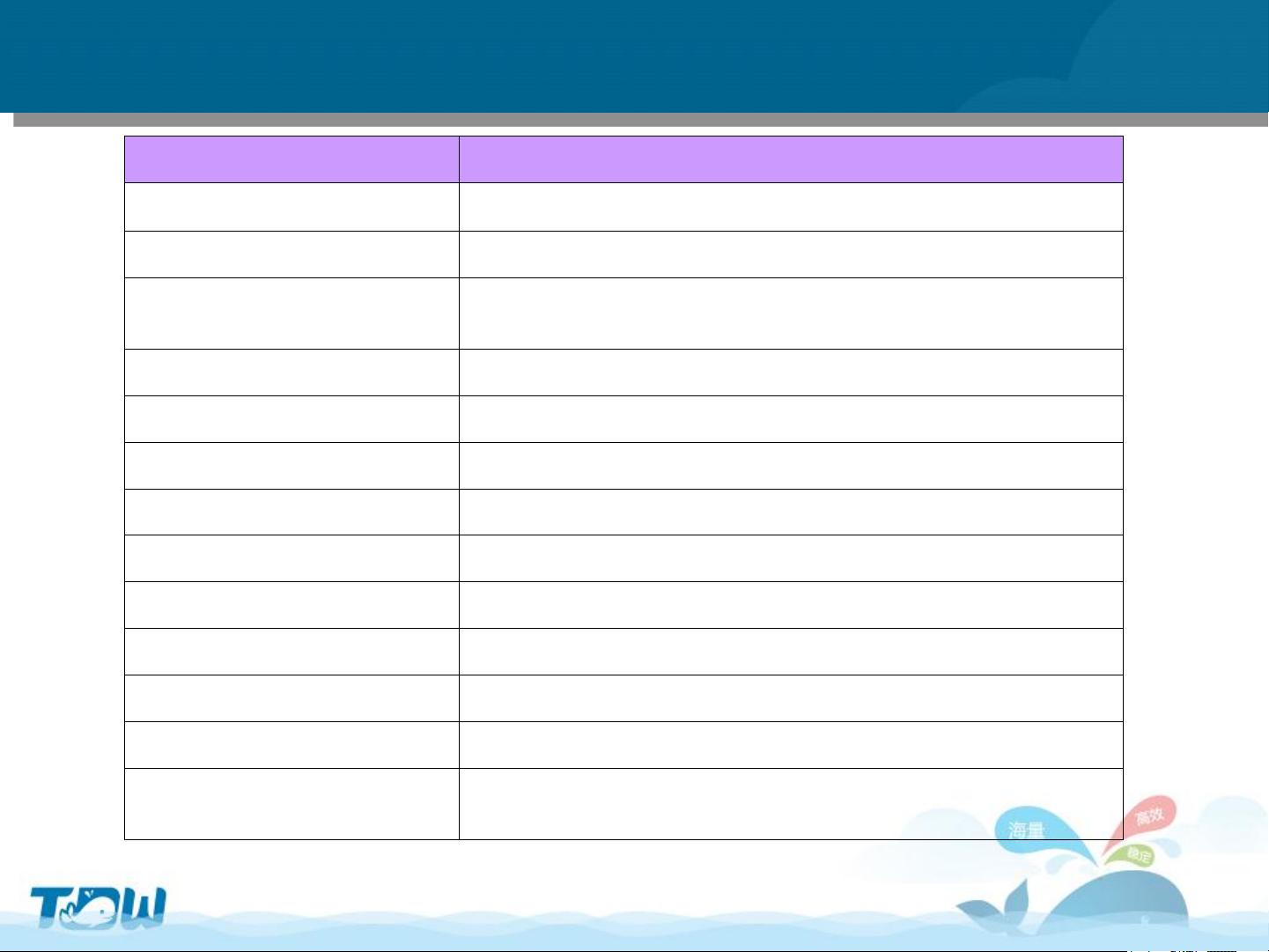
TDW特性
特性
说明
存储和计算容灾 集群中个别节点down机不影响存储和计算
存储和计算线性扩展 通过添加节点线性扩展存储和计算能力
SQL语言
select、insert、join、where、groupby、having、limit
、orderby、分区、视图等
SQL函数 简单函数、聚合函数、窗口函数、数据挖掘函数
过程语言 以python语言为母体的PL/python
多维分析 rollup、cube、grouping
MapReduce 允许提交MR任务
多种存储结构 文本/结构化/列存储/ProtoBuf/DB存储
SQL/MED 可访问和管理PostgreSQL、Oracle数据
开发工具 集成开发环境TDW IDE、命令行工具PLClient
任务调度系统 图形化的任务依赖配置、数据流转配置
系统DB 元数据与普通表一样可以通过TDW SQL进行访问
其他
Show processlist、kill query、select expr、insert
values、show create table、comment on操作等
剩余24页未读,继续阅读
2021-07-10 上传
2013-08-04 上传
2020-12-22 上传
2012-07-29 上传
2021-09-27 上传


newzq
- 粉丝: 29
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
