Nutch爬虫搭建与使用全面总结
"Nutch网页爬取总结:包括Nutch的安装步骤、JDK配置以及爬取过程中的注意事项。"
Nutch是一款开源的网络爬虫软件,用于抓取互联网上的网页并构建索引,是大数据领域中搜索引擎的重要组成部分。这篇总结详细介绍了如何在Ubuntu环境下搭建Nutch,以及配置和使用过程中的一些关键点。
首先,搭建Nutch需要准备以下工具:
1. Virtualbox:虚拟机软件,用于创建运行Ubuntu系统的环境。
2. Ubuntu Desktop或Ubuntu Server:作为Nutch的运行平台。
3. JDK:Java开发工具包,Nutch基于Java语言开发,因此需要安装JDK来运行。
4. Apache Nutch:Nutch的二进制发行版,包含所有必需的文件和脚本。
Nutch的安装过程主要包括以下步骤:
1. 安装Linux系统:在Virtualbox中安装Ubuntu,遵循标准的安装流程。
2. 安装JDK:将JDK的bin文件上传至Linux系统的~/tmp目录,通过chmod命令赋予执行权限,然后运行bin文件进行安装,并将安装目录移动到/usr/java下。
3. 配置环境变量:这是非常关键的一步,确保Nutch能够找到JDK。最初可能在~/.bash_profile或/etc/profile中配置,但考虑到需要管理员权限运行的部分,最终应在/etc/environment中配置环境变量,确保全局有效。
配置环境变量的方法如下:
- 使用gedit编辑/etc/profile和/etc/environment文件,分别添加JDK的路径到JAVA_HOME、JRE_HOME、CLASSPATH和PATH变量中。
完成以上步骤后,可以开始Nutch的部署和使用。Nutch的主要操作包括种子URL设置、爬取、解析、索引等。种子URL是爬虫开始抓取的网页集合,可以通过修改Nutch的配置文件来指定。爬取过程通常包括生成、fetch、parse、update和index等阶段,这些阶段可以通过Nutch提供的命令行工具执行。
在实际使用Nutch的过程中,可能会遇到各种问题,如网络连接错误、解析问题、配置错误等。解决这些问题通常需要检查网络设置、配置文件的正确性,以及确保Nutch与相关依赖库的兼容性。例如,Nutch的解析器需要与HTML解析库(如Tika)匹配,索引阶段则需要与Hadoop和Lucene等组件协同工作。
此外,Nutch的性能优化也是一个重要话题,包括设置合理的爬取速率、优化存储和计算资源,以及调整抓取策略以适应不同的网站结构。在大规模网络爬取时,理解Nutch的工作原理和架构,以及如何进行分布式部署,对于提升效率和处理能力至关重要。
Nutch提供了一个强大的框架,用于构建自定义的网络爬虫。通过深入理解和实践,可以掌握网络爬取的基本原理和技术,为数据分析和信息检索等领域奠定基础。
终端命令ŸŸ
%"""#""A&&
2.5 配置 nutch 查询索引
把 的 A 包到 # 的 A 目录下
终端命令ŸŸ
%&""&
终端命令ŸŸ
+++%#&A&"""#"A
启动 #
终端命令ŸŸ
%"""#""&
在 A 下会把 A+解压出 文件包
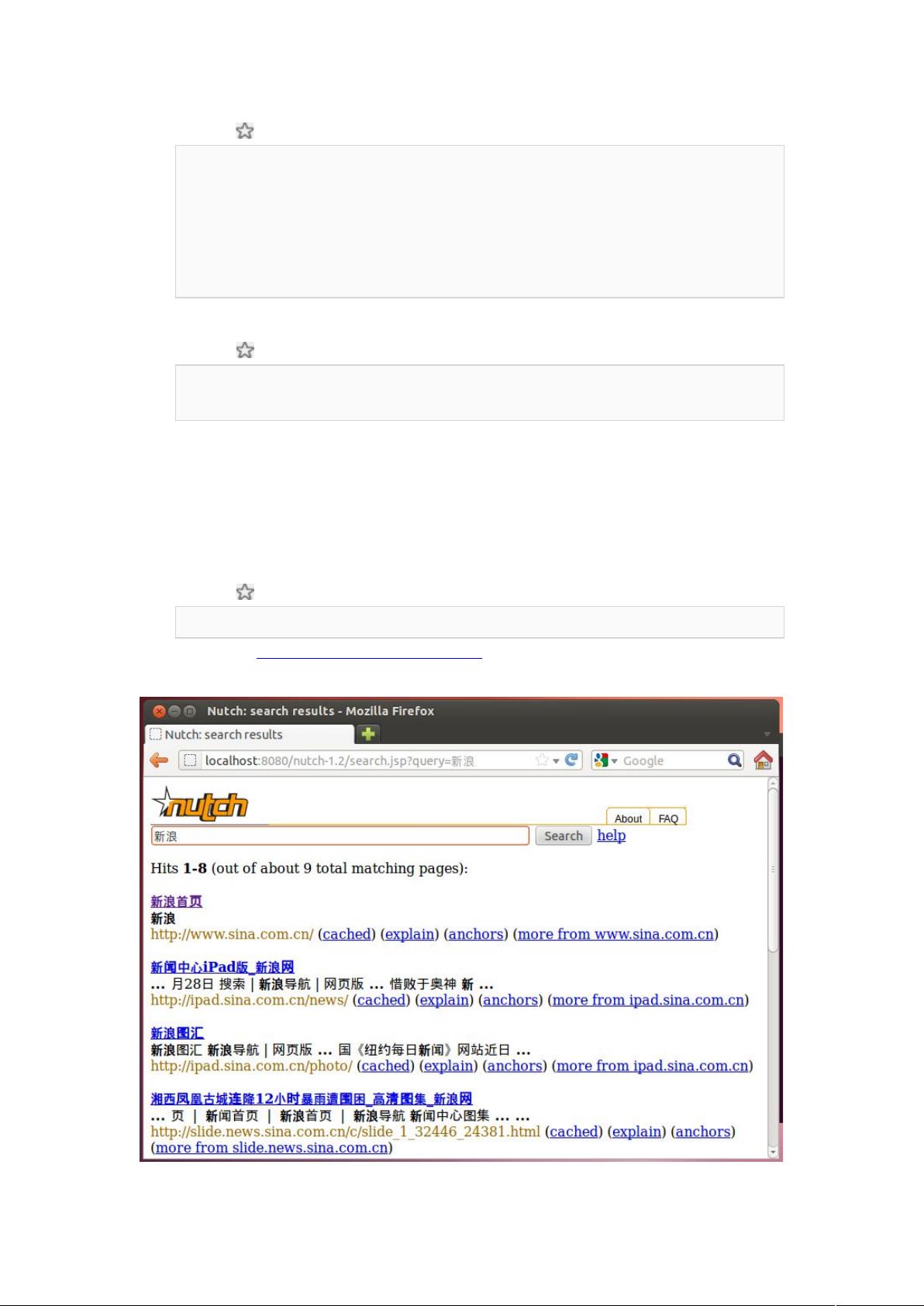
测试Ÿ9""9(("
进入 +主页$输入”新浪”$你发现没有结果而且出现乱码$下面解决这些问题先关闭
#。
终端命令ŸŸ
%"""#""A&
配置索引文件位置,因为并没有把刚才爬取下的网页和服务器关联。
终端命令ŸŸ
%&"""#"A""S1 DE;""
终端命令ŸŸ
%#&#&
T# 代码ŸŸ
<configuration>&&
&&&++++<property>&&
&&&&&&&&&&&<name></name>&&
&&&&&&&&&&&<value>""</value>&&
&&&&&&&</property>&&
</configuration>
配置 #+编码,在 # 文件的对应部分更改即可,同时删去原来的配置。
终端命令ŸŸ
%&"""#"&
终端命令ŸŸ
%#&*"#
剩余38页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
117 浏览量
2008-06-14 上传
127 浏览量
196 浏览量
2021-05-16 上传
185 浏览量

fangke216
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
