理解基于规则的分类器:原理与应用示例
需积分: 44 159 浏览量
更新于2024-07-18
2
收藏 1.14MB PPT 举报
"基于规则的分类器是一种在数据挖掘领域常用的方法,它通过构建一系列‘如果…那么…’的规则来进行预测和分类。规则由条件(Condition)和结论(y)组成,条件是规则的前提,结论是根据条件得出的判断。例如,规则‘(BloodType=Warm)→(Viviparous=No)→Birds’表示如果生物的血型为暖血,那么它不胎生并且是鸟类。另一个例子是‘(TaxableIncome<50K)→(Refund=Yes)→Evade=No’,意味着如果应税收入小于50K,则可能预示着没有逃税。"
基于规则的分类器工作原理:
1. 规则生成:首先,从训练数据中学习到一系列规则,这些规则是从实例数据中归纳出来的,能够最好地概括数据的模式。
2. 分类过程:在对新数据进行分类时,会检查每个实例是否满足某条规则的条件。如果满足,就依据规则的结论进行分类。
举例说明:
以脊椎动物数据集为例,包含体温、表皮覆盖、胎生等属性,以及对应的类别标签。通过分析数据,可以生成如下规则:
- r1:如果胎生为否且飞行动物为是,则为鸟类。
- r2:如果胎生为否且水生动物为是,则为鱼类。
- r3:如果胎生为是且体温为恒温,则为哺乳类。
- r4:如果胎生为否且飞行动物为否,则为爬行类。
- r5:如果水生动物为半,则为两栖类。
- r6:如果胎生为否且飞行动物为否且表皮覆盖为羽毛,则为鸟类。
应用规则进行分类,如“鹰”满足r1,因此被归类为鸟类;而“灰熊”满足r3,被归类为哺乳类。
规则质量的评价指标:
1. 覆盖率(Coverage):规则覆盖的数据实例比例,表示规则的泛化能力。
2. 准确率(Accuracy):根据规则分类的结果与实际标签相符的比例,反映规则的精确性。
3. 其他指标还包括:错误率、查准率、查全率、F1分数、支持度和置信度等,它们在评估规则的性能和可靠性时起着关键作用。
总结:
基于规则的分类器是数据挖掘中的一个重要工具,它利用明确的逻辑规则对数据进行解释和预测。规则可以从数据中学习得到,并用于新数据的分类。评价规则的质量通常涉及覆盖率和准确率等指标,这些指标有助于优化分类模型,提高预测的准确性和可信度。在实际应用中,需要综合考虑规则的复杂性、可解释性以及预测性能,来构建有效的分类规则系统。
2021年8月8日
5
如何评价规则的质量
覆盖率( coverage ) :
准确率( accuracy ) :
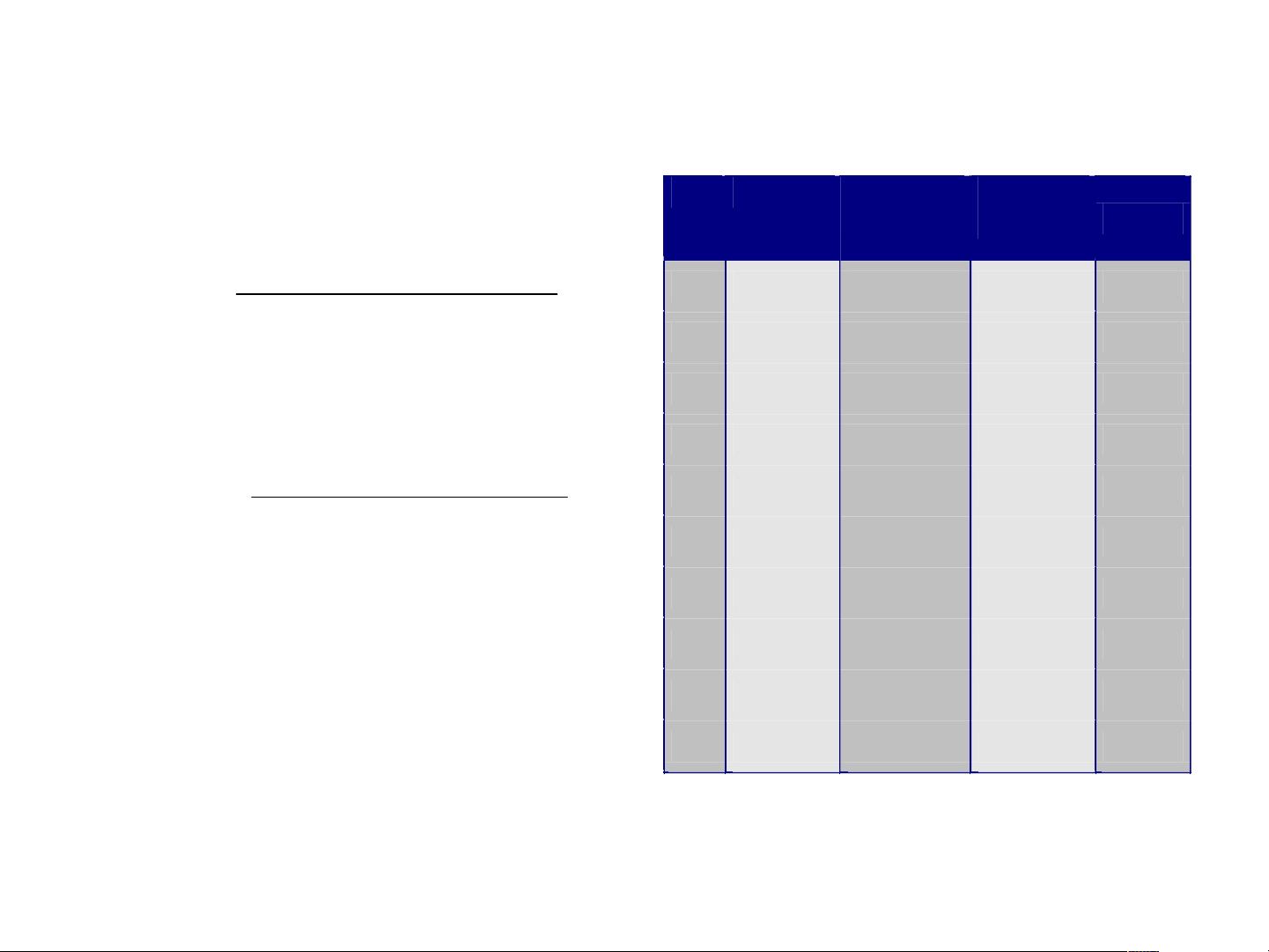
规则 : (Status=Single) No
coverage = 40%, accuracy = 50%
Tid
Refund Marital
Status
Taxable
Income
Class
1 Yes
Single
125K
No
2 No Married 100K
No
3 No
Single
70K
No
4 Yes Married 120K
No
5 No Divorced 95K
Yes
6 No Married 60K
No
7 Yes Divorced 220K
No
8 No
Single
85K
Yes
9 No Married 75K
No
10 No
Single
90K
Yes
10
covrage=
满足规则条件的记录个数
总记录个数
accuracy=
正确分类的个数
满足规则条件的记录个数
剩余24页未读,继续阅读
2021-02-06 上传
2021-05-29 上传
2021-05-11 上传
2021-06-29 上传
2021-09-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

懒熊宝贝
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
