
图 2a为奖励曲线,纵轴的数值为连续 100 个 Episode 的平均奖励。从曲线的上升趋势
中我们可以看到 DQN 算法可以逐渐学习到比较好的策略来逐渐提高表现。
图 2b为损失函数曲线,纵轴的数值为进行开根号并对数处理后的损失函数数值。可以
看到随着训练的进行,损失函数逐渐减小,而 TD error 也逐渐减小。这也符合直观的训练
过程理解。
0 2500 5000 7500 10000 12500 15000 17500 20000
Episode
10
20
30
40
50
Mean Reward
Mean reward per 100 episode
(a) 奖励曲线
0 2500 5000 7500 10000 12500 15000 17500 20000
Episode
4
3
2
1
0
loss
Training loss(log10)
(b) 损失函数曲线
图 2: 奖励曲线和损失函数曲线
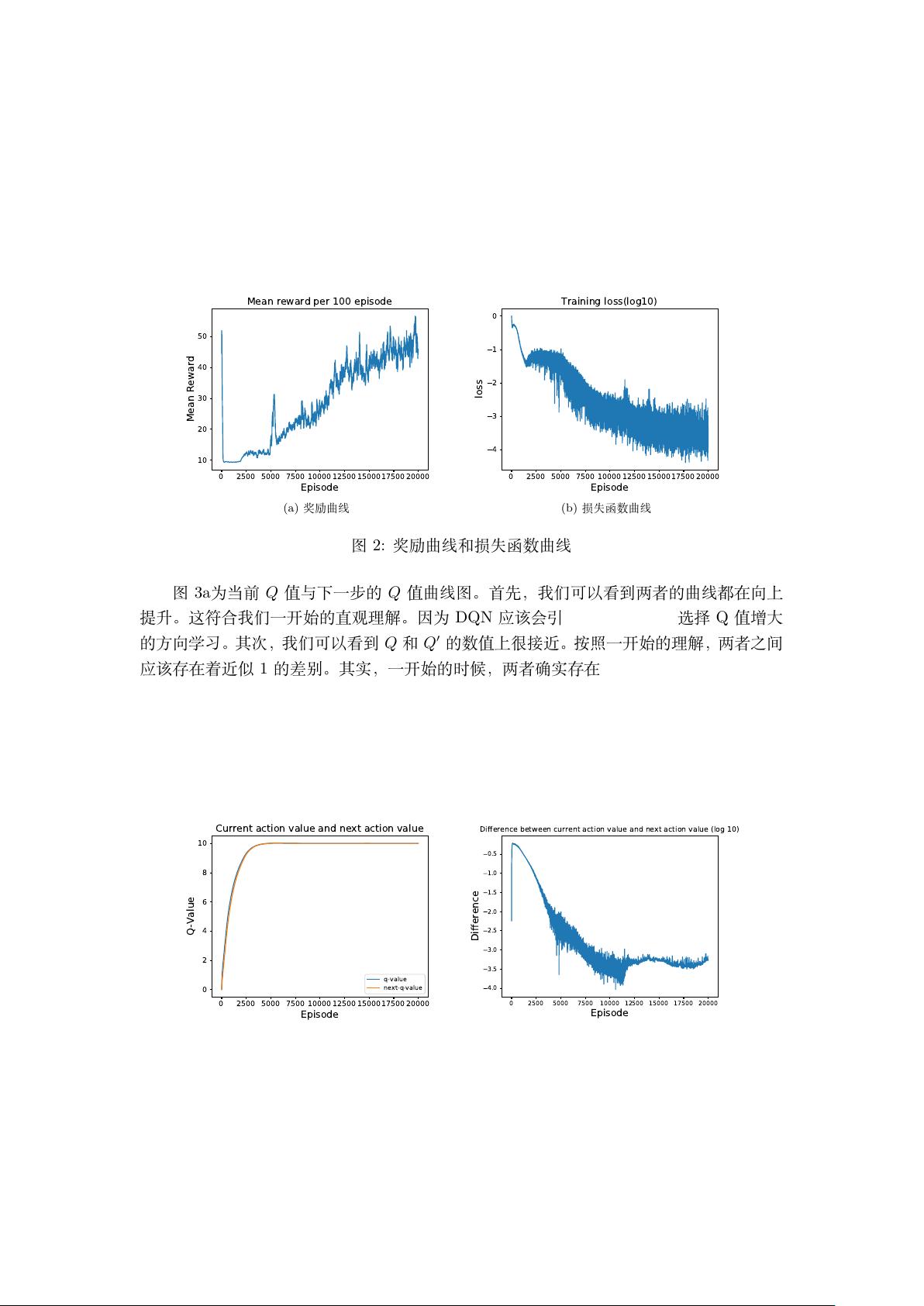
图 3a为当前 Q 值与下一步的 Q 值曲线图。首先,我们可以看到两者的曲线都在向上
提升。这符合我们一开始的直观理解。因为 DQN 应该会引导智能体不断地选择 Q 值增大
的方向学习。其次,我们可以看到 Q 和 Q
′
的数值上很接近。按照一开始的理解,两者之间
应该存在着近似 1 的差别。其实,一开始的时候,两者确实存在着近似 1 的差别。但随着
训练的进行,两者越来越接近。我们把两者之间的差取对数以后可以得到图 3b的结果。可
以看到,一开始两者之间的确是存在接近 1 的差别,但是后面就逐渐减小差别。这应该是
归结于状态空间为连续空间。连续空间的变化可能不够剧烈和明显,从而导致 DQN 的数值
变化也不明显。
0 2500 5000 7500 10000 12500 15000 17500 20000
Episode
0
2
4
6
8
10
Q-Value
Current action value and next action value
q-value
next-q-value
(a) 当前 Q 值与下一步的 Q 值曲线
0 2500 5000 7500 10000 12500 15000 17500 20000
Episode
4.0
3.5
3.0
2.5
2.0
1.5
1.0
0.5
Difference
Difference between current action value and next action value (log 10)
(b) 当前 Q 值与下一步的 Q 值之差的曲线
图 3: 当前 Q 值与下一步的 Q 值的相关曲线
图 4a为每一步正确动作和错误动作之间的 Q 值曲线。首先,正确动作的 Q 值曲线会
上升比较符合直观的理解,但是错误动作的 Q 值曲线应该会一直下降,而实验结果却有点
3
剩余11页未读,继续阅读

透明流动虚无
- 粉丝: 39
- 资源: 306
 我的内容管理
展开
我的内容管理
展开







最新资源
- 最优条件下三次B样条小波边缘检测算子研究
- 深入解析:wav文件格式结构
- JIRA系统配置指南:代理与SSL设置
- 入门必备:电阻电容识别全解析
- U盘制作启动盘:详细教程解决无光驱装系统难题
- Eclipse快捷键大全:提升开发效率的必备秘籍
- C++ Primer Plus中文版:深入学习C++编程必备
- Eclipse常用快捷键汇总与操作指南
- JavaScript作用域解析与面向对象基础
- 软通动力Java笔试题解析
- 自定义标签配置与使用指南
- Android Intent深度解析:组件通信与广播机制
- 增强MyEclipse代码提示功能设置教程
- x86下VMware环境中Openwrt编译与LuCI集成指南
- S3C2440A嵌入式终端电源管理系统设计探讨
- Intel DTCP-IP技术在数字家庭中的内容保护
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


