LinkedIn技术揭秘:Apache Samza与Yarn、Kafka的分布式流处理
77 浏览量
更新于2024-08-27
收藏 305KB PDF 举报
"基于Apache Samza,LinkedIn通过集成Yarn和Kafka构建其强大的分布式流处理架构,以此支撑大规模数据处理需求。"
Apache Samza是LinkedIn为实现高效、高可用的实时流处理而开发的开源系统,它与Apache Kafka深度集成,提供了一种处理持续流入的数据流的方式。Samza的核心特性包括其对容错机制的支持以及与Yarn的整合,这使得它能够在大型分布式环境中稳定运行。
Kafka是LinkedIn创建的开源消息系统,它作为Samza的主要数据源,能够处理大量的实时数据流。在LinkedIn的架构中,Kafka每天处理的数据量高达500TB,这表明了它在大数据处理领域的强大能力。为了应对如此大规模的数据,LinkedIn采用了集群图的概念,每个集群图专门处理特定类型的消息,并通过消息镜像策略来实现集群间的冗余和故障转移。
LinkedIn的集群设计考虑了数据中心的高可用性。每个数据中心内部有本地集群和聚合集群,形成一个层次化的拓扑结构。本地tier包含了数据中心内的所有本地集群,而聚合tier则由所有数据中心的聚合集群构成。当数据中心发生故障时,可以通过这种结构将流量切换到其他正常运行的数据中心,确保服务的连续性。
除了在线集群,LinkedIn还设置了离线聚合tier,这通常用于批量处理或数据分析任务,进一步分离实时流处理和离线处理的工作负载。这种分层和分隔的设计确保了LinkedIn能够在处理大量实时数据的同时,保持系统的稳定性和高效率。
通过Samza,LinkedIn能够实现实时处理业务事件,快速响应用户行为,以及构建复杂的实时数据管道。结合Yarn的资源管理和调度能力,Samza可以灵活地分配计算资源,处理各种规模的流处理任务。这种架构不仅提高了LinkedIn的运营效率,也为其他需要大规模流处理的组织提供了参考和借鉴。
基于基于ApacheSamza,揭秘,揭秘LinkedIn架构背后的技术架构背后的技术
Samza是由LinkedIn开源的一个分布式流处理系统。近日,LinkedIn资深SRE Jon Bringhurst发表了一篇博文,揭秘LinkedIn
是如何利用Samza与Yarn、Kafka进行扩展的。
Samza是由LinkedIn开源的一个分布式流处理系统,与之配合使用的是开源分布式消息处理系统Apache Kafka。很多人会将
Samza与Twitter Storm相媲美。近日,LinkedIn资深SRE(网站可靠性工程师)Jon Bringhurst发表了这篇博文,阐述
LinkedIn是如何利用Samza与Yarn、Kafka进行扩展的。
Samza是什么是什么
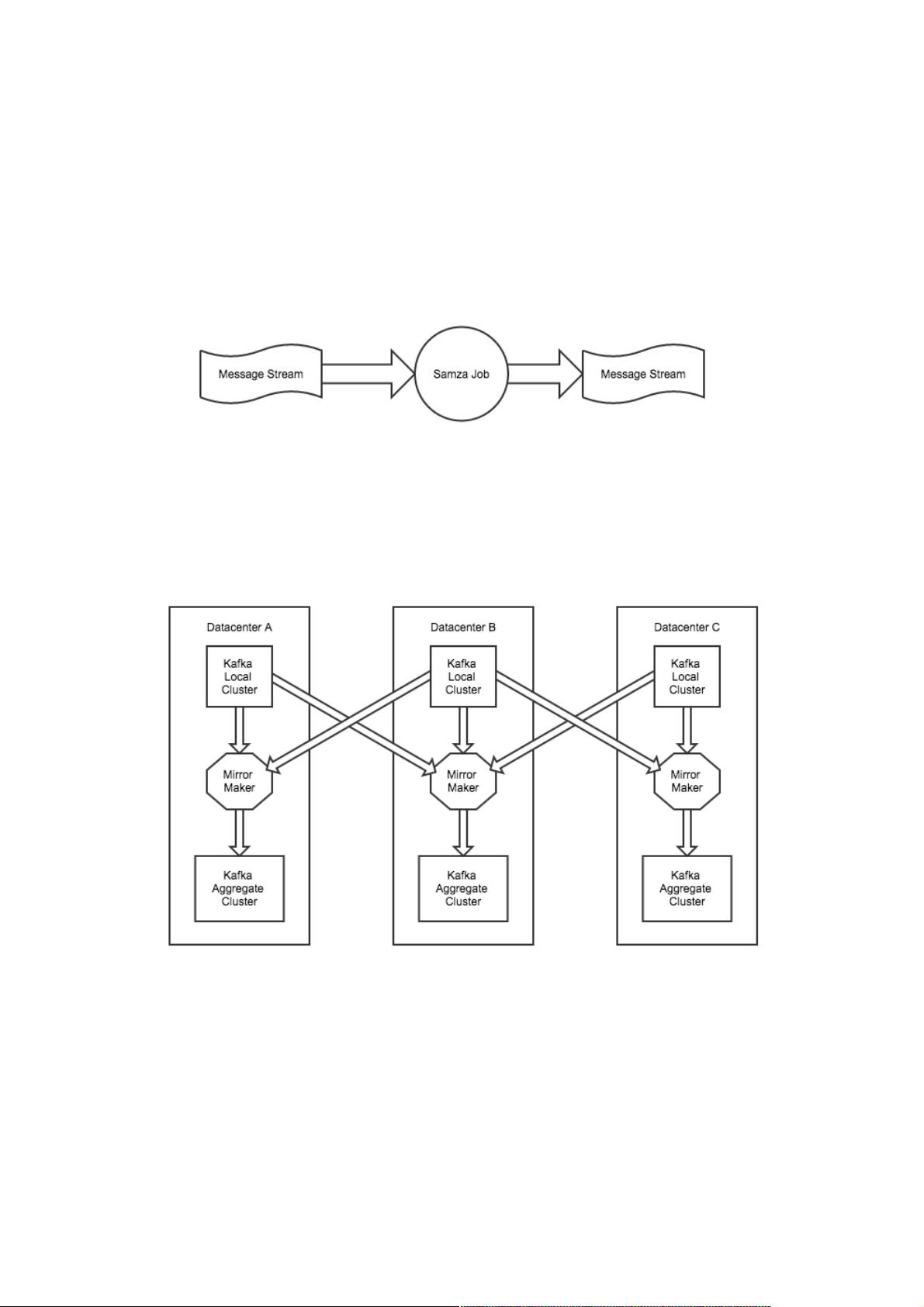
Apache Samza是一个开源框架,可以帮助开发者进行高速消息处理同时具有良好的容错能力。Samza可从Kafka中获取消息
并进行处理,处理完毕后把结果返回Kafka(LinkedIn自家的分布式消息系统Kafka)。一个简易的Samza处理过程如下图所
示:
尽管Samza的设计初衷为不同类型的流处理系统服务,在LinkedIn中我们对消息流的处理主要使用的还是Kafka。所以接下来
会先讲述Kafka然后再探讨Samza。
Kafka简述简述
每天经由Kafka进行处理的数据量多达500TB。或许你会想象有个大规模集群来对付如此庞大的数据,实际上不是的。我们实
际上使用的是集群图,每个集群图负责处理特定类型的消息。我们透过对不同集群图进行消息镜像处理从而控制集群到集群的
消息流向。
针对数据中心可能出现的宕机情况,我们为集群提供了一个拓扑结构,以便数据中心出错离线后继续保持消息的正常流动。每
一个数据中心里,我们都会配备一个本地的集群和一个聚合的Kafka集群。每个本地集群会穿越数据中心被镜像复制到聚合集
群。所以一旦某个数据中心出现异常,我们会转移去另一个数据中心而不造成重大影响。
我们把拓扑结构中的每一个水平层叫做“tier(层)”,tier由各个不同数据中心具相同功能的集群组成。例如在上图中,有一个本
地tier和一个聚合tier。
本地tier是所有数据中心中的本地集群的集合,聚合tier是所有数据中心的聚合集群的集合。
此外还有一个离线聚合tier(offline aggregate tier)。Production聚合tier会被镜像复制到离线聚合tier进行批处理作业(例如,在
Hadoop上进行map-reduce作业)。我们可利用它来分离production集群并在不同数据中心里进行批处理作业。
下载后可阅读完整内容,剩余3页未读,立即下载
2017-09-27 上传
2008-07-18 上传
2008-06-19 上传
2023-05-25 上传
2023-05-27 上传
2023-12-02 上传
2023-06-10 上传
2023-09-13 上传
2023-04-25 上传

weixin_38655011
- 粉丝: 9
- 资源: 916
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
