深度学习中的注意力机制:从文本识别到机器翻译
"本文将介绍注意力机制(Attention Mechanism),一种在文本识别、语音识别和机器翻译等任务中广泛使用的深度学习技术。"
注意力机制(Attention Mechanism)是深度学习领域中的一个重要概念,它源于神经网络模型,特别是序列到序列(Sequence-to-Sequence,Seq2Seq)模型中的应用。Seq2Seq模型最初由Sutskever等人在2014年的论文中提出,用于解决变长输入和输出的问题,例如机器翻译。
传统的Seq2Seq模型由编码器(Encoder)和解码器(Decoder)两部分组成。编码器负责处理输入序列,将其转化为固定长度的向量,然后解码器基于这个向量生成输出序列。然而,当输入序列较长时,整个序列的信息被压缩到一个单一的向量中,可能导致信息丢失,从而影响模型的性能。
注意力机制的引入解决了这个问题。它允许解码器在生成每个输出单元时,根据需要“关注”输入序列的不同部分,而不是仅仅依赖于一个固定长度的上下文向量。这样,模型可以动态地聚焦于输入序列中的关键信息,提高了处理长序列任务的能力。
具体来说,注意力机制分为几个步骤:
1. 编码阶段:编码器将输入序列通过循环神经网络(如LSTM或GRU)处理,生成一系列隐藏状态。
2. 注意力计算:解码器在每个时间步生成一个权重分布,这个分布反映了对输入序列中不同位置的关注程度。
3. 上下文向量生成:通过加权求和编码器的隐藏状态,根据注意力权重生成一个上下文向量,这个向量包含了当前解码时刻所需的重点信息。
4. 解码阶段:解码器使用这个上下文向量和其自身的隐藏状态来预测下一个输出单元。
在文本识别中,注意力机制帮助模型聚焦于输入文本的关键部分,提高识别准确性。在语音识别中,它可以使模型更加关注语音信号中的重要音节或语调。而在机器翻译中,注意力机制让模型能够灵活地关注源语言句子的不同部分,生成更准确的目标语言翻译。
除了基本的注意力机制,还有多种变体,如位置注意力(Positional Attention)、多头注意力(Multi-Head Attention)等,它们进一步扩展了模型的表达能力和处理复杂任务的能力。这些方法在Transformer模型中得到了广泛应用,Transformer模型是近年来在自然语言处理领域取得突破的重要工具。
注意力机制通过动态关注输入序列中的关键信息,增强了Seq2Seq模型在处理序列数据任务时的表现,为深度学习在多个领域带来了显著的性能提升。
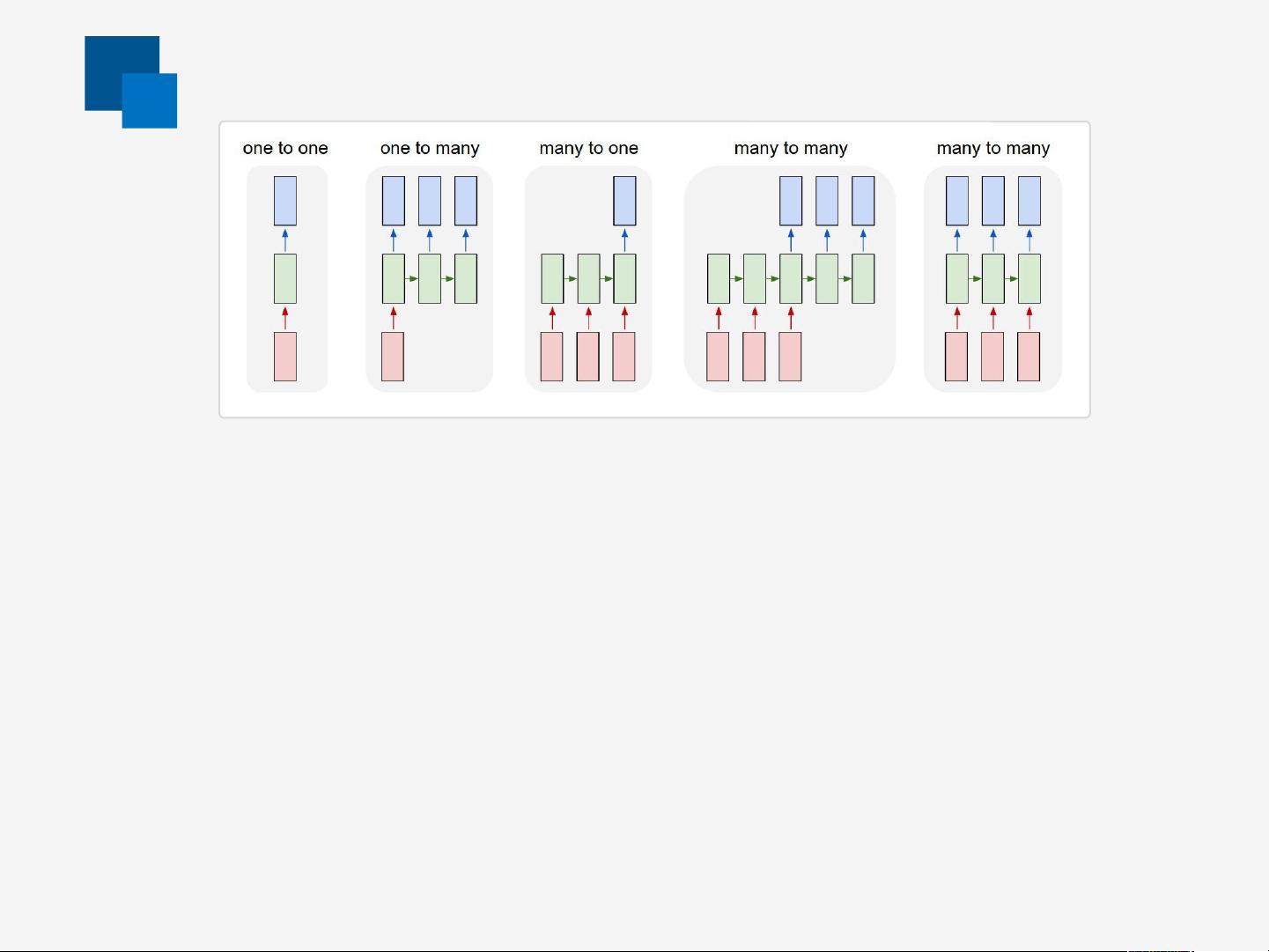
Sequences
矩形为向量,箭头为函数。红色表输入向量,蓝色表输出向量,绿色表 RNN 隐藏状态。
(1) Vanilla mode of processing without RNN, from !xed-sized input to !xed-
sized output (e.g. image classi!cation).
(2) Sequence output (e.g. image captioning takes an image and outputs a
sentence of words).
(3) Sequence input (e.g. sentiment analysis where a given sentence is
classi!ed as expressing positive or negative sentiment).
(4) Sequence input and sequence output (e.g. Machine Translation: an
RNN reads a sentence in English and then outputs a sentence in French).
(5) Synced sequence input and output (e.g. video classi!cation where we
wish to label each frame of the video).
(1) 如 CNN , (2)(3)(5) 如 RNN , (4) 如 encoder-decoder RNN 。
剩余24页未读,继续阅读
2019-06-11 上传
2019-06-02 上传
2021-01-27 上传
2023-04-25 上传
2023-05-18 上传
2024-04-08 上传
2023-09-02 上传
2023-05-04 上传
2023-09-19 上传

沤江一流
- 粉丝: 252
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
