单色图像中3D手部姿态深度学习估计
需积分: 50 197 浏览量
更新于2024-09-07
1
收藏 6.05MB PDF 举报
"Learning to Estimate 3D Hand Pose from Single RGB Images" 这篇文章探讨了在现代计算机视觉领域中一个重要的挑战:仅凭单张彩色(RGB)图像估计三维(3D)手部姿态。随着低成本消费级深度相机的普及和深度学习技术的发展,传统的深度图像已经能够提供相对准确的手部三维姿势估计。然而,对于RGB图像,由于缺乏深度信息,任务变得更加复杂,因为姿态的确定远没有深度数据那样直观。
作者 Christian Zimmermann 和 Thomas Brox 从 University of Freiburg 提出了一种创新的方法,他们设计了一个深度网络,该网络不仅检测图像中的关键点,还学习到一种内在的三维关节结构(network-implicit 3D articulation prior)。这种网络结构能够根据输入的RGB图像,推断出手部的三维姿态,克服了由于缺少深度而带来的高度不确定性。
为了训练这样的网络,研究人员开发了一个大规模的3D手部姿势数据集,该数据集基于合成的手部模型,以模拟真实场景中的各种手部动作和姿态。通过这种方式,他们能够确保模型具有广泛的泛化能力,不仅仅局限于特定的训练样本。
实验部分展示了这项技术在多个测试集上的性能,包括针对手语识别的应用。结果表明,尽管面临着显著的挑战,但仅依靠单张RGB图像进行3D手部姿势估计是可行的,并且具有实际应用价值,比如在机器人交互、手势控制和人机界面等领域。
这篇文章的核心贡献在于提出了一种利用深度学习解决RGB图像中3D手部姿态估计问题的新方法,强调了通过学习隐含的三维结构来弥补无深度信息带来的难题。通过大规模的合成数据集训练和实际应用的验证,这项研究为未来的相关研究和实际应用提供了新的思路和技术支持。
Canonical Coordinates
Viewpoint
left/right
w
rel
= w
c
· R
>
R
w
c
w
rel
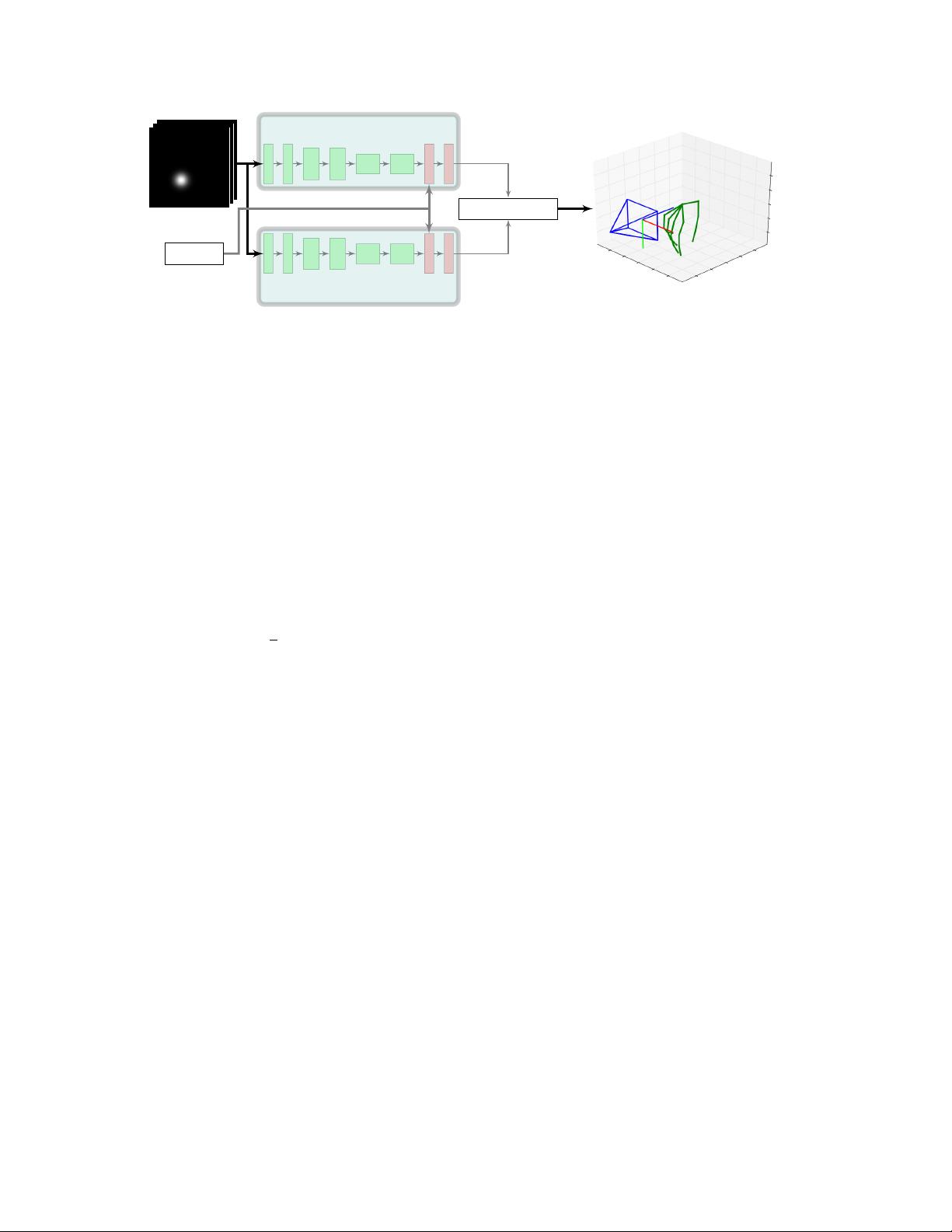
Figure 3: Proposed architecture for the PosePrior network. Two almost symmetric streams estimate canonical coordinates
and the viewpoint relative to this coordinate system. Combination of the two predictions yields an estimation for the relative
normalized coordinates w
rel
.
3. Hand pose representation
Given a color image I ∈ R
N ×M ×3
showing a single
hand, we want to infer its 3D pose. We define the hand pose
by a set of coordinates w
i
= (x
i
, y
i
, z
i
), which describe the
locations of J keypoints in 3D space, i.e., i ∈ [1, J] with
J = 21 in our case.
The problem of inferring 3D coordinates from a single
2D observation is ill-posed. Among other ambiguities, there
is a scale ambiguity. Thus, we infer a scale-invariant 3D
structure by training a network to estimate normalized co-
ordinates
w
norm
i
=
1
s
· w
i
, (1)
where s = kw
k+1
− w
k
k
2
is a sample dependent constant
that normalizes the distance between a certain pair of key-
points to unit length. We choose k such that s = 1 for the
first bone of the index finger.
Moreover, we use relative 3D coordinates to learn a
translation invariant representation of hand poses. This is
realized by subtracting the location of a defined root key-
point. The relative and normalized 3D coordinates are given
by
w
rel
i
= w
norm
i
− w
norm
r
(2)
where r is the root index. In experiments the palm keypoint
was the most stable landmark. Thus we use r = 0.
4. Estimation of 3D hand pose
We estimate three-dimensional normalized coordinates
w
rel
from a single input image. An overview of the general
approach is provided in Figure 2. In the following sections,
we provide details on its components.
4.1. Hand segmentation with HandSegNet
For hand segmentation we deploy a network architecture
that is based on and initialized by the person detector of Wei
et al. [19]. They cast the problem of 2D person detection as
estimating a score map for the center position of the hu-
man. The most likely location is used as center for a fixed
size crop. Since the hand size drastically changes across
images and depends much on the articulation, we rather
cast the hand localization as a segmentation problem. Our
HandSegNet is a smaller version of the network from Wei
et al. [19] trained on our hand pose dataset. Details on the
network architecture and its training prcedure are provided
in the supplemental material. The hand mask provided by
HandSegNet allows us to crop and normalize the inputs in
size, which simplifies the learning task for the PoseNet.
4.2. Keypoint score maps with PoseNet
We formulate localization of 2D keypoints as estimation
of 2D score maps c = {c
1
(u, v), . . . , c
J
(u, v)}. We train a
network to predict J score maps c
i
∈ R
N ×M
, where each
map contains information about the likelihood that a certain
keypoint is present at a spatial location.
The network uses an encoder-decoder architecture simi-
lar to the Pose Network by Wei et al. [19]. Given the image
feature representation produced by the encoder, an initial
score map is predicted and is successively refined in resolu-
tion. We initialized with the weights from Wei et al. [19],
where it applies, and retrained the network for hand key-
point detection. A complete overview over the network ar-
chitecture is located in the supplemental material.
4.3. 3D hand pose with the PosePrior network
The PosePrior network learns to predict relative, nor-
malized 3D coordinates conditioned on potentially incom-
plete or noisy score maps c(u, v). To this end, it must learn
the manifold of possible hand articulations and their prior
probabilities. Conditioned on the score maps, it will output
the most likely 3D configuration given the 2D evidence.
Instead of training the network to predict absolute 3D co-
ordinates, we rather propose to train the network to predict
coordinates within a canonical frame and additionally esti-
剩余11页未读,继续阅读
点击了解资源详情
1808 浏览量
110 浏览量
2021-05-29 上传
449 浏览量
132 浏览量
2014-07-29 上传
327 浏览量
192 浏览量

无名小卒000001
- 粉丝: 112
 我的内容管理
展开
我的内容管理
展开







最新资源
- 武汉大学数字图像处理课程课件精要
- 搭建个性化知识付费平台——Laravel开发MeEdu教程
- SSD7练习7完整解答指南
- Android中文API合集第三版:开发者必备指南
- Python测试自动化实践:深入理解更多测试案例
- 中国风室内装饰网站模板设计发布
- Android情景模式中音量定时控制与铃声设置技巧
- 温度城市的TypeScript实践应用
- 新版高通QPST刷机工具下载支持高通CPU
- C++实现24点问题求解的源代码
- 核电厂水处理系统的自动化控制解决方案
- 自定义进度条组件AMProgressView用于统计与下载进度展示
- 中国古典红木家具网页模板免费下载
- CSS定位技术之Position-master解析
- 复选框状态持久化及其日期同步技术
- Winform版HTML编辑器:强大功能与广泛适用性
