PySpider中文手册:安装、使用与高级特性详解
需积分: 49 131 浏览量
更新于2024-07-18
收藏 22.95MB PDF 举报
PySpider中文手册是一份全面指南,介绍了这款流行的Python爬虫框架的安装、基本用法和高级特性。该手册针对的是PySpider v1.0版本,最后更新日期为2018年9月20日,主要关注于以下几个核心部分:
1. **安装与基础使用**:
- 安装步骤详细说明了如何在Python环境中设置和配置PySpider,确保读者可以顺利启动并进行基础爬取任务。
- 基本用法部分讲解了如何定义爬虫规则(self.crawl)、配置文件(config.json)以及数据存储目录(data目录)。
2. **高级功能**:
- phantomjs被提及,可能是指使用PhantomJS作为浏览器渲染引擎,用于处理JavaScript依赖的网页内容。
- PySpider的Web UI(图形用户界面)被强调,它提供了强大的调试工具,使得开发者能够直观地监控和管理爬虫运行。
3. **经验和心得**:
- 提供作者的经验分享,可能包括优化技巧、最佳实践和避免常见问题的方法,帮助用户提高工作效率。
4. **常见坑与案例**:
- 针对可能遇到的问题和挑战,手册列出了用户可能遇到的一些常见问题及其解决方案,确保用户在实践中少走弯路。
- 实际案例部分展示了如何通过PySpider解决实际问题或完成特定任务,具有很高的实用价值。
5. **资源获取与支持**:
- 提供了Gitbook源码链接,让读者可以查看和学习源代码,同时也指导如何将其转化为电子书或下载离线阅读格式,如PDF、ePub和Mobi。
6. **版权与授权**:
- 手册遵循知识署名-相同方式共享4.0协议,确保了内容的开放性和可复制性。
这份PySpider中文手册是一份深入浅出的指南,对于希望掌握Python爬虫技术的读者来说,无论是初学者还是进阶者,都能从中获得宝贵的实战指导和理论知识。

PySpider基本⽤法
使⽤PySpider的基本步骤
下⾯来介绍⼀下PySpider的使⽤的步骤和操作:
运⾏PySpider
在某个⽬录下的终端命令⾏中输⼊pyspider即可启动运⾏。
注:
如果是⽤虚拟环境安装的PySpider,记得先进去虚拟环境后再运⾏PySpider
⽐如⽤的pipenv,则是先pipenvshell,再pyspider
pyspider等价于pyspiderall
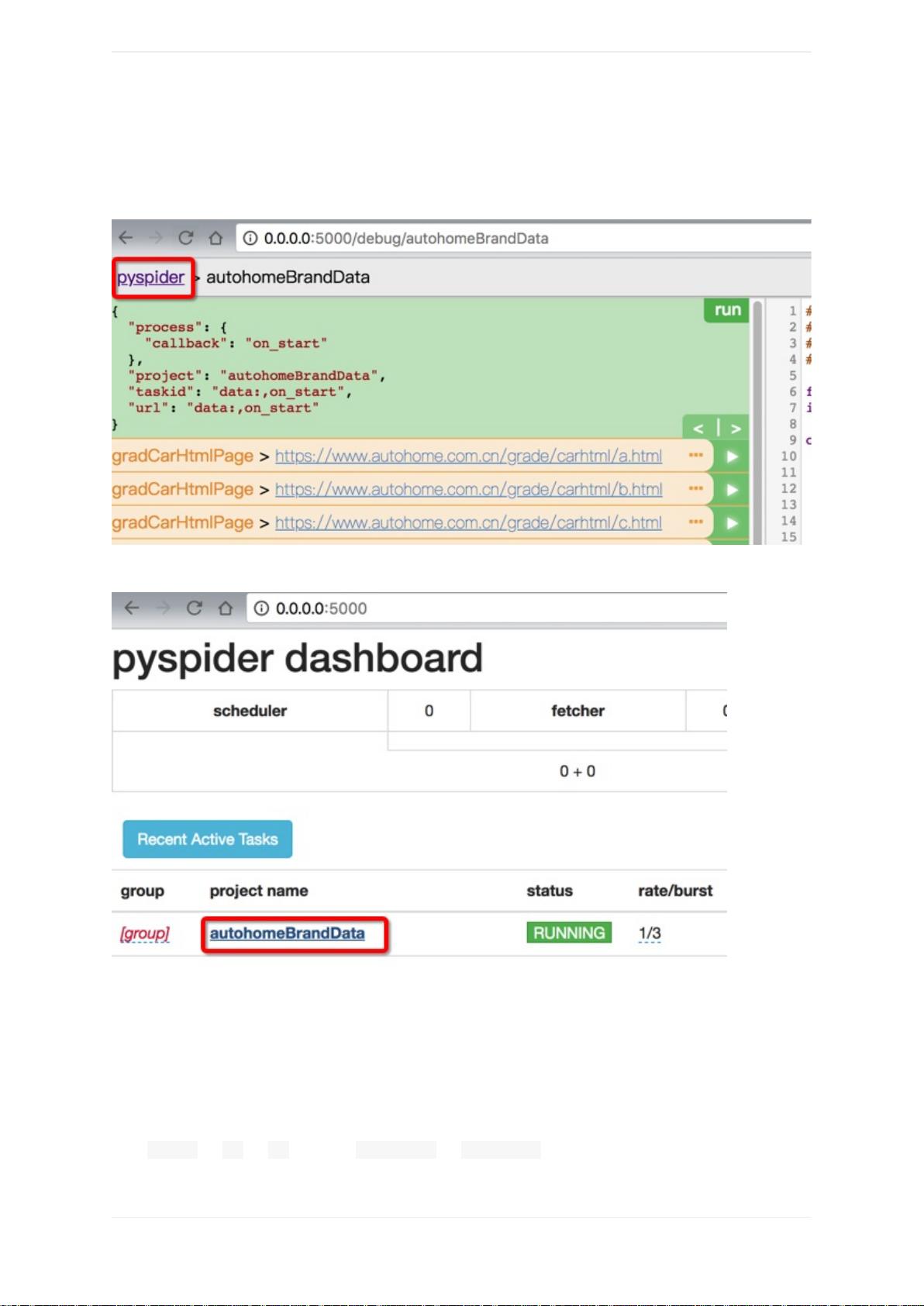
进⼊ WebUI
然后去⽤浏览器打开:
http://0.0.0.0:5000/
即可进⼊爬⾍的管理界⾯了,此界⾯⼀般称为:WebUI
新建爬⾍项⽬
点击Create,去新建⼀个爬⾍项⽬
输⼊:
爬⾍名称:
⼊⼝地址:⾃动⽣成的代码中,会作为起始要抓取的url
也可以不填
后续也可以去代码中修改的
然后再点击新建的爬⾍项⽬,进⼊调试⻚⾯
新建出来的项⽬,默认状态是TODO
点击新建出来的项⽬名,直接进⼊调试界⾯
然后右边是编写代码的区域
左边是调试的区域,⽤于执⾏代码,显示输出信息等⽤途
调试爬⾍代码
编写代码,调试输出信息,保存代码
PySpider基本⽤法
8
剩余41页未读,继续阅读
2024-03-01 上传
352 浏览量
151 浏览量
622 浏览量
113 浏览量
132 浏览量
2021-04-26 上传
2021-07-02 上传

队长给我球23333
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 流浪汉环境性能比较:Virtualbox vs Parallels
- WatchMe项目使用TypeScript进行开发的介绍
- Nali:全面支持IPv4/IPv6离线查询IP地理及CDN信息工具
- 利用pdfjs-2.2.228-dist实现零插件PDF在线预览技术
- MATLAB与jEdit集成:实用工具包发布
- Vagrant、Ansible和Docker搭建Django应用环境
- 使用Delphi更改计算机名称的详细教程
- TrueNAS CORE中iocage-homeassistant插件的高级安装方法
- rack程序:命令行工具高效处理天气雷达数据
- VS2017下实现C# TCP一对多通信程序源码
- MATLAB项目管理器:快速切换与路径管理
- LightDM GTK+ Greeter设置编辑器的Python图形界面介绍
- 掌握CSS技巧,提升网页设计美感
- 一维RCWA算法在matlab中的实现与应用
- Hot Reload插件:提升Flutter开发效率的Vim工具
- 全面掌握Dubbo:Java面试题及详细答案解析
