XGBoost算法解析:构建与优化目标函数
需积分: 0 171 浏览量
更新于2024-08-04
收藏 534KB DOCX 举报
"非编程作业1,讨论XGBoost算法及其决策树原理"
XGBoost算法是一种广泛应用的梯度提升决策树(Gradient Boosting Decision Tree, GBDT)框架,尤其在机器学习竞赛和实际项目中表现出色。它由陈天奇博士开发,其核心在于优化了GBDT的效率和泛化能力。
XGBoost模型基于 CART (Classification and Regression Trees) 决策树,通过连续添加树来逐步提高预测准确率。每一棵树的预测结果会累加到总预测分数上。模型的形式可以表示为所有CART树的预测分数之和:
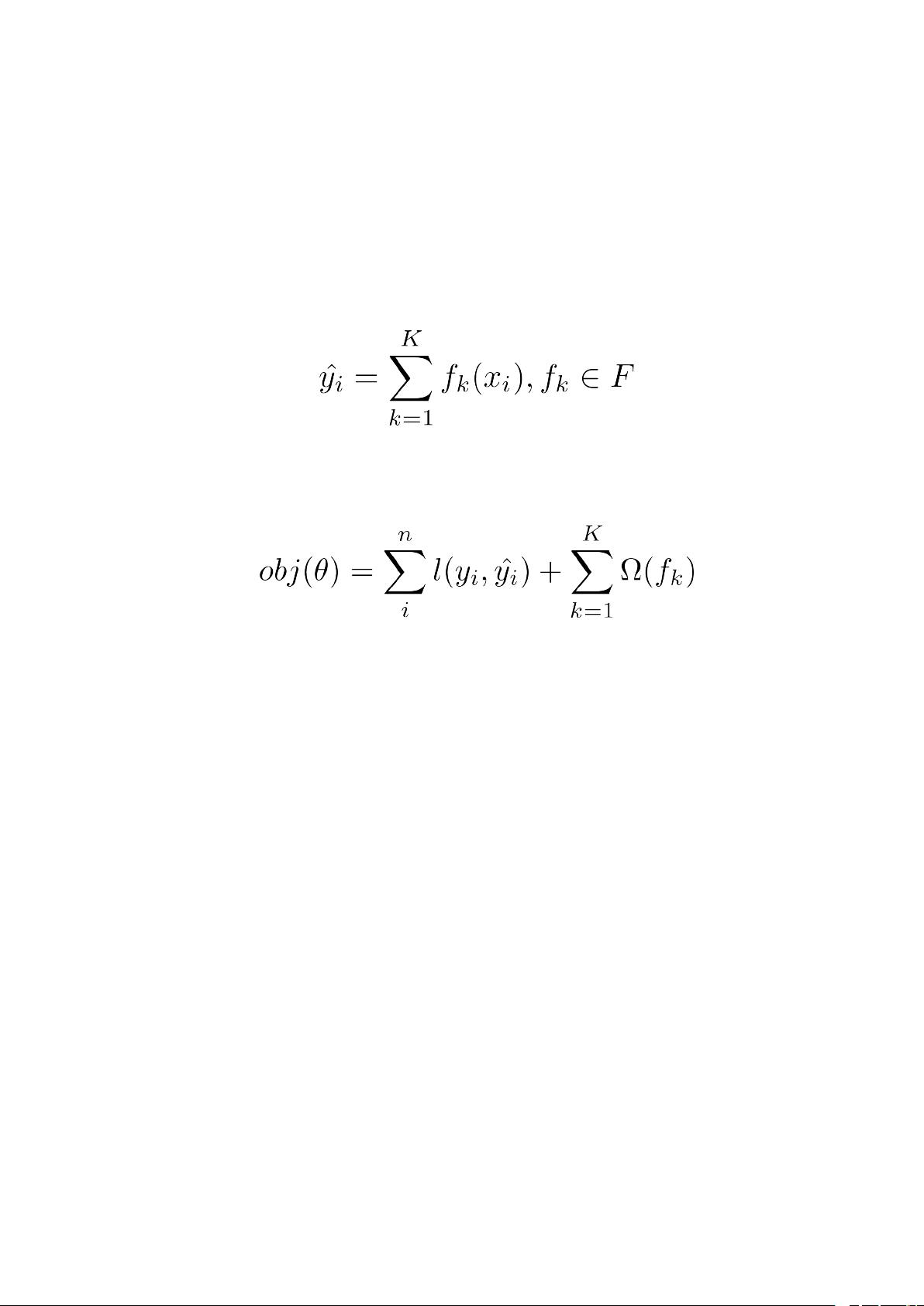
\( \hat{y} = \sum_{k=1}^{K} f_k(x) \)
这里,\( K \) 是树的数量,\( f_k \) 表示第 \( k \) 棵CART树。XGBoost的目标函数包含了损失函数和正则项,用于平衡模型的拟合程度和复杂度:
\( L = \sum_{i=1}^{n} l(y_i, \hat{y}_i) + \sum_{k=1}^{K}\Omega(f_k) \)
其中,\( n \) 是样本数量,\( l \) 是损失函数,\( \Omega(f_k) \) 是正则化项,用于防止过拟合。正则项通常包括树的复杂度(如叶子节点数量)和叶子节点分数的平方和。
XGBoost采用加法训练方法,逐棵优化决策树。在第 \( t \) 步,它寻找一棵能最大程度减少目标函数的CART树 \( f_t \),这棵树是基于前 \( t-1 \) 棵树的预测结果构建的:
\( \arg\min_{f_t} L + \Omega(f_t) \)
当损失函数为均方误差(MSE)时,可以利用泰勒展开简化优化过程。在一阶和二阶导数的基础上,XGBoost仅需考虑二次可微的损失函数。
CART树的结构用函数 \( q(x) \) 表示,它将样本映射到特定的叶子节点,而 \( w_q(x) \) 是样本在该叶子节点上的预测值。正则化项可以写为:
\( \Omega(f) = \lambda \sum_{j=1}^{T} w_j^2 + \gamma T \)
这里的 \( \lambda \) 和 \( \gamma \) 控制树的复杂度,较大的值会使树更加简单,因为更多的叶子节点会被较大的惩罚。
最终,XGBoost通过求解优化问题来确定每棵树的结构和叶子节点分数,以最小化目标函数。这种方法使得XGBoost能够高效地构建出既能有效拟合数据又避免过拟合的强预测模型。
总结来说,XGBoost算法是通过迭代构建CART决策树,逐步改进预测性能,同时通过正则化控制模型复杂度,确保良好的泛化能力。它在处理各种预测任务,特别是分类和回归问题时,展现出优秀的性能。
1.(b)
XGBoost 算法
XGBoost 算法的原理是在一颗 CART 决策树上不断加树,使得算法的精确了不
断提升。xgboost 的模型就是选用一批 CART 决策树做预测,然后简单的将各个
树的预测分数相加,其数学模型如下:
其中 K 是树的棵数,F 表示所有的可能的 CART 树,f 表示其中某一课具体的
CART 树。该模型就由 K 棵 CART 树组成。该模型的目标函数如下:
这个目标函数分为两部分,其中第一部分是损失函数,第二部分是正则项,
正则项由 K 棵树的正则化项相加而来。
XGBoost 通过加法训练来最小化目标函数以找到最佳的参数组。参数蕴含在
每棵 CART 树中。确定一棵 CART 树需要两部分:第一是树的结构,第二是每个叶
子结点上的分数。将叶子结点作为参数容易实现:在树的结构确定时,只需要将
正则化项设为各个叶子结点的平方和,此时整个目标函数就是 K 棵树的所有叶子
结点的函数,可以用梯度下降或者随即下降来优化目标函数。但确定 K 棵树的结
构比较困难,需要用特殊的算法,即加法训练。加法训练的思想就是分步骤优化
目标函数:首先优化第一棵树,然后在此基础上优化第二颗树,以此类推,直到
优化完 K 棵树:
下载后可阅读完整内容,剩余4页未读,立即下载
2024-01-15 上传
2011-11-06 上传
2022-07-09 上传
2022-11-12 上传
2021-10-21 上传
2022-01-23 上传
2021-09-26 上传
2024-07-10 上传
2022-08-08 上传

柏傅美
- 粉丝: 30
- 资源: 325
 我的内容管理
展开
我的内容管理
展开







最新资源
- NIST REFPROP问题反馈与解决方案存储库
- 掌握LeetCode习题的系统开源答案
- ctop:实现汉字按首字母拼音分类排序的PHP工具
- 微信小程序课程学习——投资融资类产品说明
- Matlab犯罪模拟器开发:探索《当蛮力失败》犯罪惩罚模型
- Java网上招聘系统实战项目源码及部署教程
- OneSky APIPHP5库:PHP5.1及以上版本的API集成
- 实时监控MySQL导入进度的bash脚本技巧
- 使用MATLAB开发交流电压脉冲生成控制系统
- ESP32安全OTA更新:原生API与WebSocket加密传输
- Sonic-Sharp: 基于《刺猬索尼克》的开源C#游戏引擎
- Java文章发布系统源码及部署教程
- CQUPT Python课程代码资源完整分享
- 易语言实现获取目录尺寸的Scripting.FileSystemObject对象方法
- Excel宾果卡生成器:自定义和打印多张卡片
- 使用HALCON实现图像二维码自动读取与解码
