泰坦尼克号案例:逻辑回归预测生存概率
本次案例研究的主题围绕着经典电影《泰坦尼克号》的情境展开,实际上是将其转化为一个实际的机器学习问题。泰坦尼克号沉船事件中,由于救生艇数量有限,优先权被赋予了妇女和儿童,这暗示了一个明显的生存优先级顺序。在这个案例中,我们的目标是利用历史数据,即乘客的个人信息(如年龄、性别、舱位等)和他们的生存结果,通过训练一个二分类模型——逻辑回归,来预测其他未知乘客的生存概率。
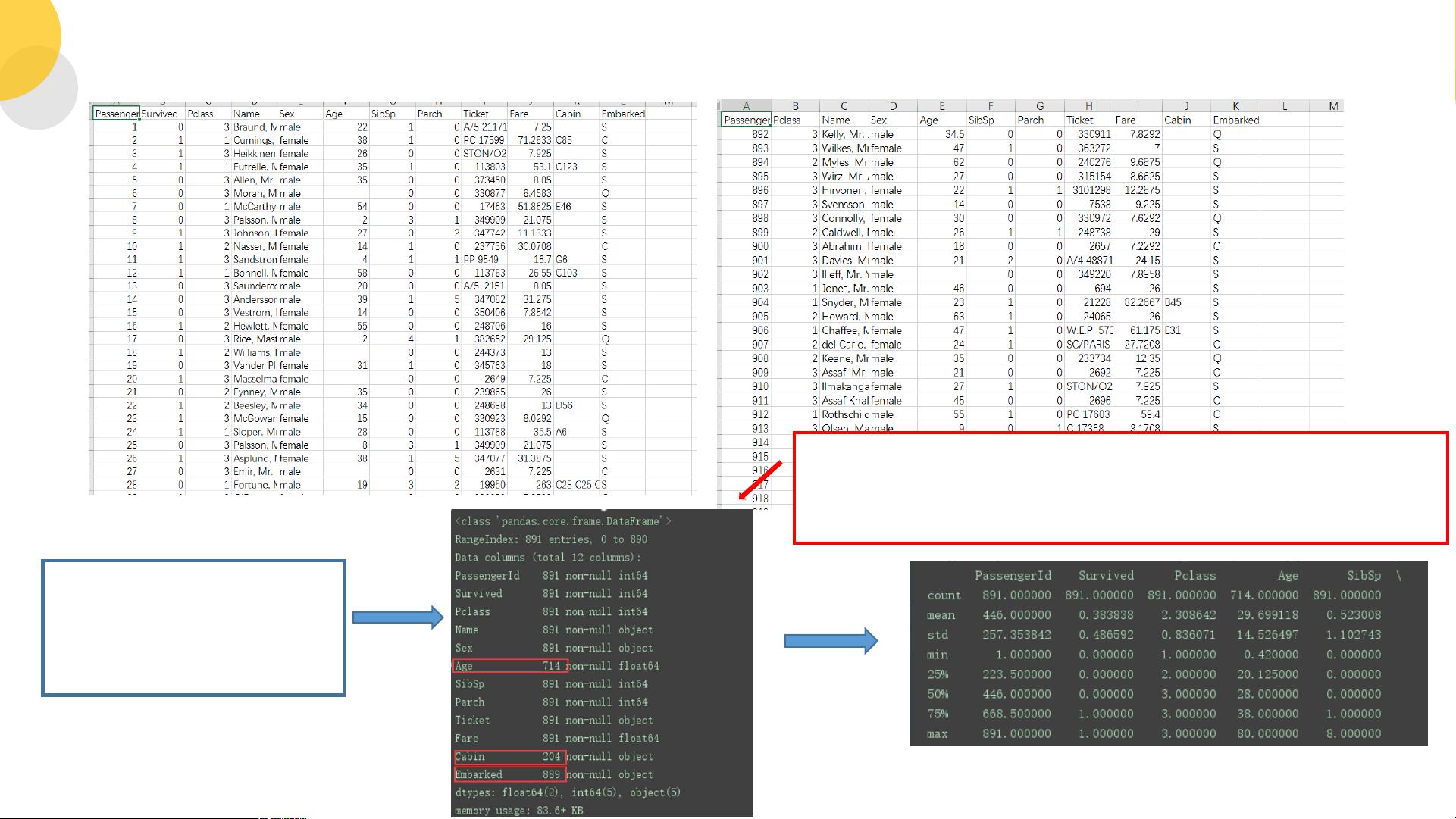
首先,数据的认识是关键。数据集包含了891名乘客的信息,其中部分属性如年龄(Age)和舱位(Cabin)存在缺失值。年龄数据缺失较多,而Cabin信息则只有部分记录。这表明在数据分析初期,需要进行数据清洗和预处理,以确保模型的准确性和可靠性。
数据预处理是整个流程中的重要环节。业内共识指出,数据的质量直接影响模型性能。对于缺失值,Lil_Rachel选择使用随机森林(RandomForest)算法来填充年龄数据,这是一种通过集成多个决策树来减少过拟合的机器学习方法。Cabin属性的处理则将其转换为“有”或“无”两个类别,这是将类别型特征转换为数值型特征的过程,以便逻辑回归能够处理。
接着,因子化(Feature Encoding)是一个必要的步骤,它将非数值型的类别特征转换为可以被模型理解的数值形式。例如,Cabin的Yes/No编码可能变成数字0和1。这种转换有助于保持模型的简洁性和可解释性。
在建模阶段,逻辑回归被选定为处理这个问题的合适工具,因为它能够处理二分类问题,且其直观的输出概率有助于理解哪些因素对生存预测更重要。逻辑回归模型通过估计每个特征与生存之间的关系强度和方向,形成预测决策边界。
最后,模型的系统优化涉及到对模型参数的调整和验证,以达到最佳性能。这可能包括交叉验证、网格搜索等方法,确保模型能够在测试数据上表现良好,并避免过拟合或欠拟合的问题。
总结来说,这个泰坦尼克号案例不仅是关于一个浪漫故事,更是运用统计学和机器学习技术分析历史数据的实际操作,通过数据预处理、特征工程和模型构建,旨在揭示影响乘客生存的关键因素,从而模拟现实世界中的决策制定过程。
初探数据
在 python 中 pandas ,
把 csv 文件读入成
dataframe 格式,完成
数据导入
训练数据中总共有 891 名乘客,属性的数据不
全, Age 属性只有 714 名乘客有记录 Cabin 只有 204
名乘客是已知的
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
105 浏览量
1729 浏览量
453 浏览量
1346 浏览量
2022-01-27 上传
457 浏览量
2021-10-08 上传

Lil_Rachel
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易酷免费影视系统:开源网站代码与简易后台管理
- Coursera美国人口普查数据集及使用指南解析
- 德加拉6800卡监控:性能评测与使用指南
- 深度解析OFDM关键技术及其在通信中的应用
- 适用于Windows7 64位和CAD2008的truetable工具
- WM9714声卡与DW9000网卡数据手册解析
- Sqoop 1.99.3版本Hadoop 2.0.0环境配置指南
- 《Super Spicy Gun Game》游戏开发资料库:Unity 2019.4.18f1
- 精易会员浏览器:小尺寸多功能抓包工具
- MySQL安装与故障排除及代码编写全攻略
- C#与SQL2000实现的银行储蓄管理系统开发教程
- 解决Windows下Pthread.dll缺失问题的方法
- I386文件深度解析与oki5530驱动应用
- PCB涂覆OSP工艺应用技术资源下载
- 三菱PLC自动调试台程序实例解析
- 解决OpenCV 3.1编译难题:配置必要的库文件
