KNN算法与kd树详解:从原理到实战应用
下载需积分: 0 | PDF格式 | 1.62MB |
更新于2024-08-05
| 160 浏览量 | 举报
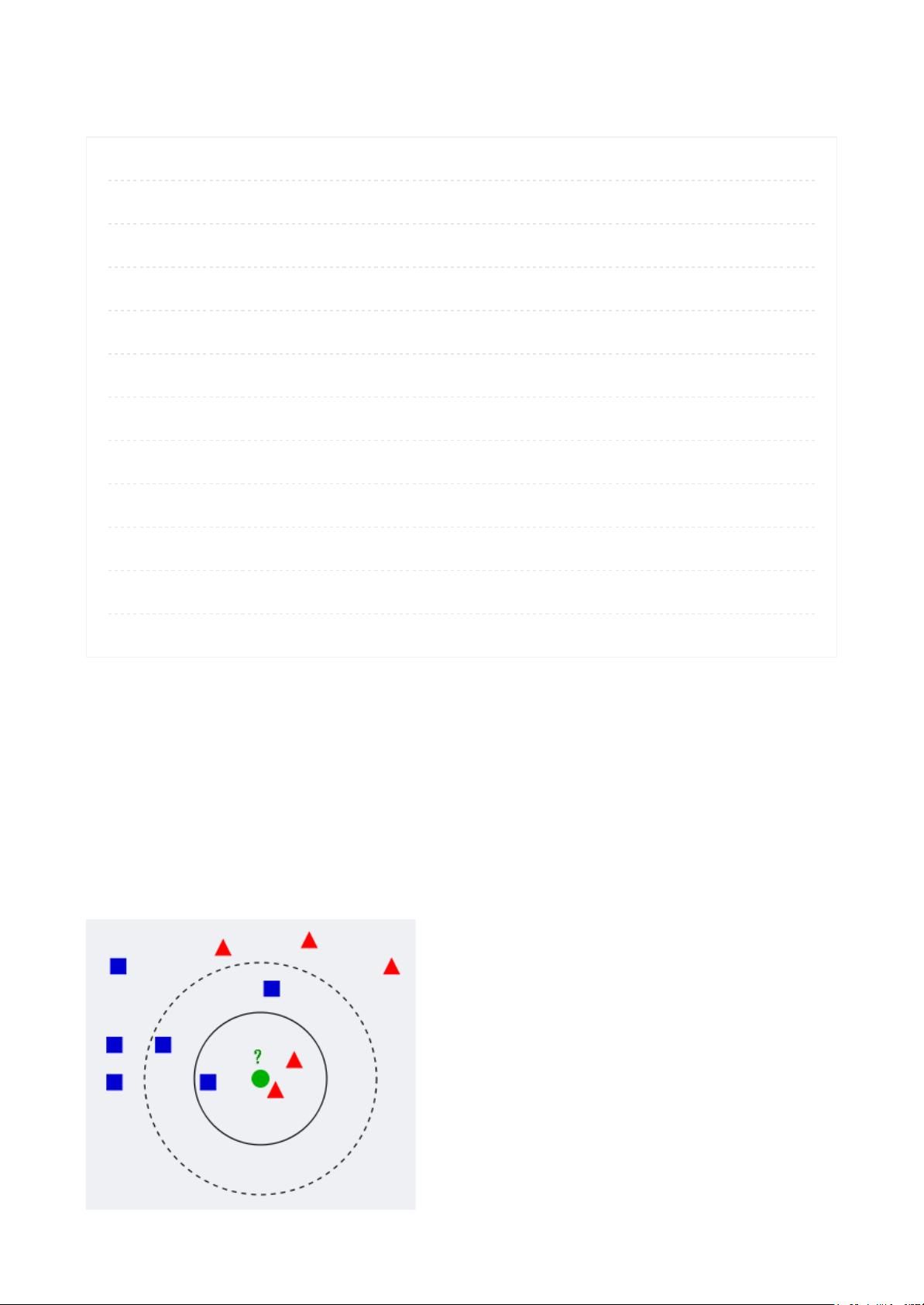
"22. KNN及kd树1" 这篇文章主要介绍了K近邻算法(K-Nearest Neighbor, KNN)及其在高维空间中的优化实现——kd树。KNN是一种基础的机器学习分类算法,它根据新样本与训练集中最相似的k个样本的类别进行预测。在1.1节中,我们理解了KNN的基本概念,即对于一个新样本,通过寻找其在训练集中的k个最近邻来进行分类决策。
1.2节讨论了距离度量的选择,常用的有欧式距离、曼哈顿距离和马氏距离,这些度量方法用于衡量样本间的相似性。选择合适的k值至关重要,因为它影响了模型的复杂度和过拟合风险。较小的k值可能导致过拟合,而较大的k值可能增加预测误差,因此通常需要通过交叉验证等方法来确定最佳的k值。
文章的重心在于2.1至2.6部分,这里详细讲解了kd树的实现。kd树是一种空间分割数据结构,特别适合高维空间中的搜索问题。2.2节解释了kd树的工作原理,它是通过不断将数据一分为二(划分成两个子空间),形成一棵树状结构,从而实现快速的最近邻搜索。2.3至2.4部分介绍了kd树的构建过程,包括如何划分和插入新的数据点。2.5节则着重于kd树的最近邻搜索算法,以及2.6节提到的改进版本——最佳二分搜索算法(Best-Bin First, BBF)。
最后,文章还提到了kd树的实际应用,如在SIFT特征匹配算法中的使用,这种情况下,通过KNN和kd树的结合,可以更有效地进行图像检索和特征点匹配,提高了搜索的效率和准确性。
总结来说,KNN算法和kd树是解决高维空间搜索问题的重要工具,它们在实际的计算机视觉和机器学习任务中扮演着关键角色,特别是在处理大规模数据和提高搜索效率方面。理解和掌握这些技术对于从事IT行业的人来说,无论是开发图像处理系统还是设计推荐引擎,都是必不可少的知识点。"
下载后可阅读完整内容,剩余9页未读,立即下载
相关推荐




不能汉字字母b
- 粉丝: 22
- 资源: 291
 我的内容管理
展开
我的内容管理
展开







