利用维基百科同义词知识提升内容定向广告匹配性能
PDF格式 | 1.3MB |
更新于2024-07-15
| 110 浏览量 | 举报
本文探讨了"改进基于维基百科词典知识的上下文广告匹配"这一主题,针对Web广告业中普遍存在的挑战——同义词和多义性问题,以及传统关键词匹配技术在处理上下文匹配和为用户提供相关广告方面的不足。论文的主要作者是Guandong Xu、Zongda Wu、Guiling Li 和 Enhong Chen,他们于2013年2月18日提交了最初的研究,并在2014年1月14日进行了修订,最终于同年3月22日接受发表,被收录在KnowlInfSyst期刊,DOI为10.1007/s10115-014-0745-z。
传统的关键词匹配方法往往受限于词汇表中的低交集和缺乏充分的语义理解,导致广告选择效果不理想,用户可能无法看到与网页内容最相关的信息。为解决这些问题,作者提出了一种新的上下文广告策略。该方法的核心在于利用维基百科词典知识来增强目标页面(或广告)的语义表达。首先,他们将每个网页转换为一个关键词向量,这是一个关键步骤,因为它将文本内容转换为数值形式,便于计算机处理。
在这个过程中,作者引入了两个额外的特征:一是基于维基百科中词汇之间的关系(如同义词、反义词或上下位词等),通过词典知识网络扩展关键词的含义范围,提高广告的相关性;二是可能结合机器学习算法,如TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)或者Word2Vec等,来捕捉单词之间的语义关联,以便更准确地识别广告与上下文的匹配度。
通过这种维基词典知识融合的策略,论文作者旨在提升广告的匹配精度,减少同义词带来的歧义,从而提高用户的点击率,提供更好的用户体验。这项工作对于广告投放平台优化广告展示策略,以及搜索引擎和内容提供商改进内容相关广告推荐系统具有重要意义,为解决自然语言处理领域中的语义理解难题提供了新的视角和方法。
G. Xu et al.
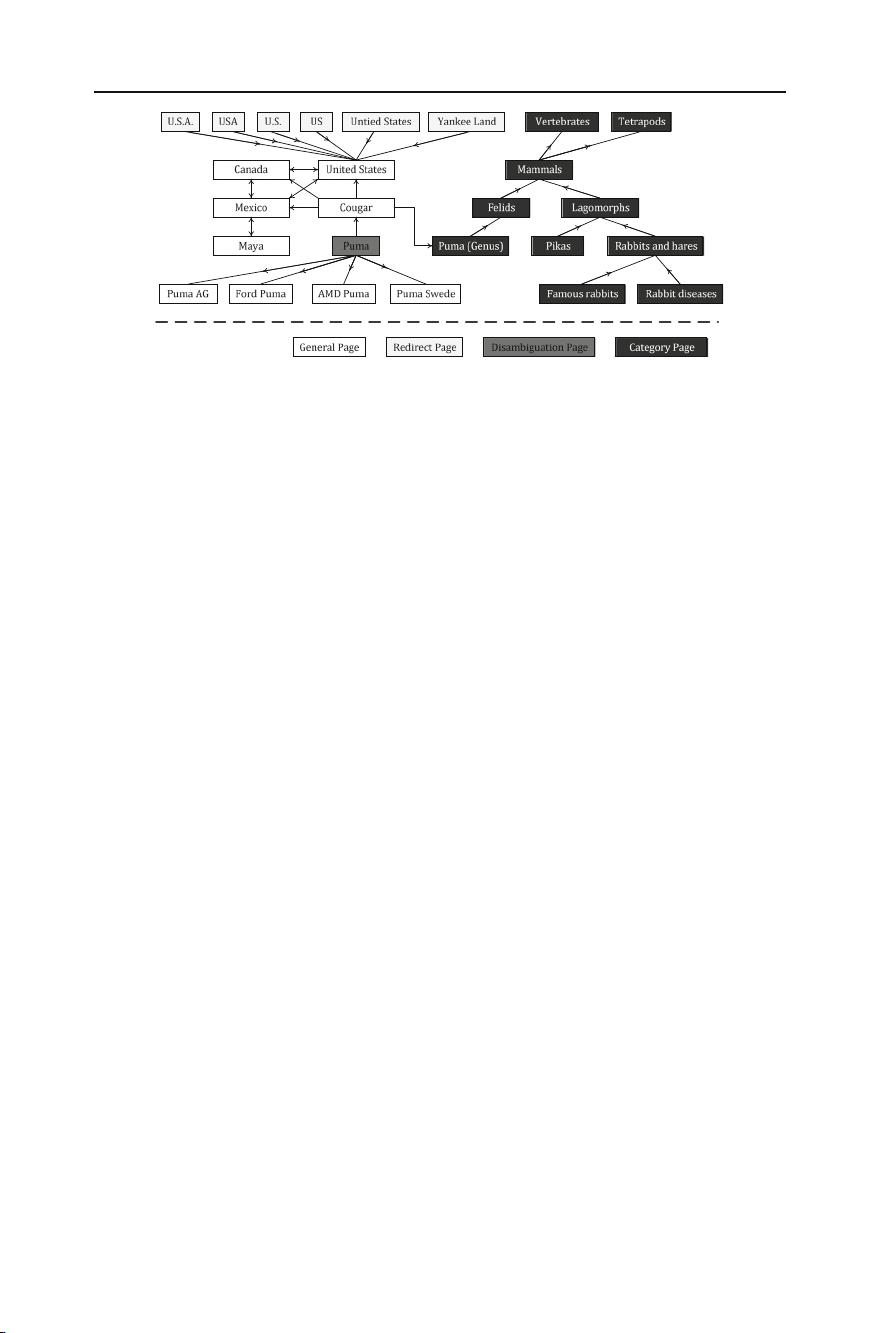
Fig. 2 Example structure from Wikipedia
Each article in Wikipedia describes a single concept, and its title is a succinct, well-
formed phrase that resembles terms in a conventional thesaurus. Each article must belong to
at least one category. Moreover, there are many hyperlinks between articles, which reflect
many semantic relations, such as equivalent relations (synonymy), hierarchical relations
(hyponymy) and associative relations. Below, we briefly introduce the linkage structure in
Wikipedia (see [20] for more details).
2.2.1 Redirect pages
In Wikipedia, there is only one article for each concept. However, there can be many equiv-
alent titles for a concept due to the existence of synonyms, etc. Wikipedia uses a redirect
page, which only contains redirect hyperlinks, to link each equivalent concept to the source
article. Redirect hyperlinks can handle capitalization and spelling variations, abbreviations,
synonyms, colloquialisms and scientific terms. As shown in Fig. 2, an entry with a consid-
erably higher number of redirect pages is “United States.” Its redirect pages correspond to
acronyms (U.S., U.S.A., US, USA), misspellings (Untied States) or synonyms (Yankee land).
2.2.2 Disambiguation pages
In Wikipedia, disambiguation pages are created for ambiguous terms, i.e., the terms that
denote two or more concepts, e.g., the term “Cell” may refer to many concepts such as the
basic life unit, a microprocessor architecture and a scientific journal. Wikipedia provides
disambiguation pages that contain various possible meanings, from which users can select
articles corresponding to their intended concepts. For example, the disambiguation page for
“Puma” lists 22 associated concepts, four of which are given in Fig. 2, from persons (Puma
Swede), to vehicles (Ford Puma) and a company (Puma AG).
2.2.3 Article pages
In Wikipedia, each article can link to several entries, thus forming an interconnected network
over articles. An editor can insert a hyperlink between a word or phrase and its corresponding
Wikipedia entry when editing an article. If we denote each article as a node, and each hyperlink
between articles as an edge, pointing from one node to another, then the articles and their
hyperlinks form a directed graph (see the left side of Fig. 2).
123

剩余32页未读,继续阅读
相关推荐


139 浏览量

weixin_38619467
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 模拟动态分区分配算法的程序设计与实现
- GoPro VR Player v3.0.5:免费360度全景视频播放器
- Kinect数据获取与Qt界面显示类设计原理
- 无需复杂库的MATLAB图像速度识别教程
- 基于Bootstrap和SSM的多文件上传流程及代码实现
- Java小程序开发:王磊的实训作品
- Java Web交易应用Spring Boot实战与部署
- 贵州2013公务员成绩排名快捷查询工具发布
- 掌握JDBC增删改查技术的PDF教程
- ThingSpeak平台与MATLAB集成的示例教程
- 全面掌握Modbus调试工具,实现TCP/RTU通信高效对接
- MCS-51单片机C语言编程100例详解
- 随机抽取软件:智能化的选择工具
- 文星直书文本编辑器v10.1:免费安装的写作与文档管理工具
- 秒杀活动必备:网站时间校准工具软件介绍
- 《大声回答哎》儿童互动故事PPT模板下载
