SPSS Modeler数据处理详解:模型训练与数据优化
需积分: 0 189 浏览量
更新于2024-07-14
收藏 3.06MB DOC 举报
"该文档是关于使用SPSS Modeler进行数据处理的笔记,涵盖了数据流操作、数据类型、数据挖掘模型、数据预处理、模型评估和数据质量检查等多个方面。"
在SPSS Modeler中,数据处理涉及多个关键步骤和概念。首先,数据流是通过拖放方式管理的,允许用户将不同的数据处理节点连接起来,形成一个完整的分析流程。数据字段被分为连续、分类、标记和名义四种类型,每种类型都有特定的含义和用途。例如,连续字段代表数值范围,分类字段表示离散值,标记字段常用于二元变量如性别(0或1),而名义字段则包含各种集合。
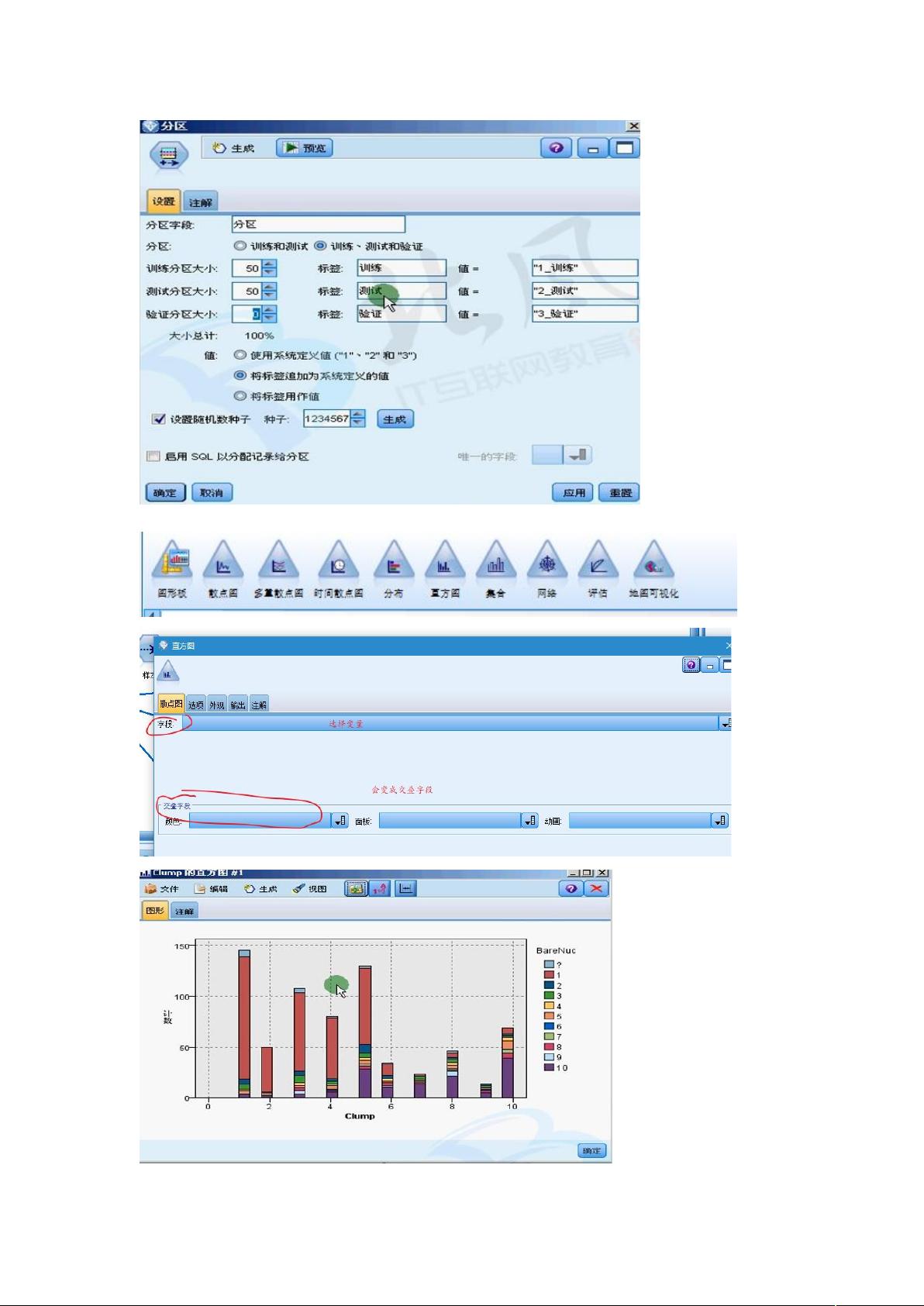
数据挖掘模型的训练过程可以是有导师或无导师的。有导师的模型允许用户在字段上打标签,便于人为控制和监督学习。在构建模型时,数据通常分为训练集、测试集和验证集,以便评估模型的性能和泛化能力。
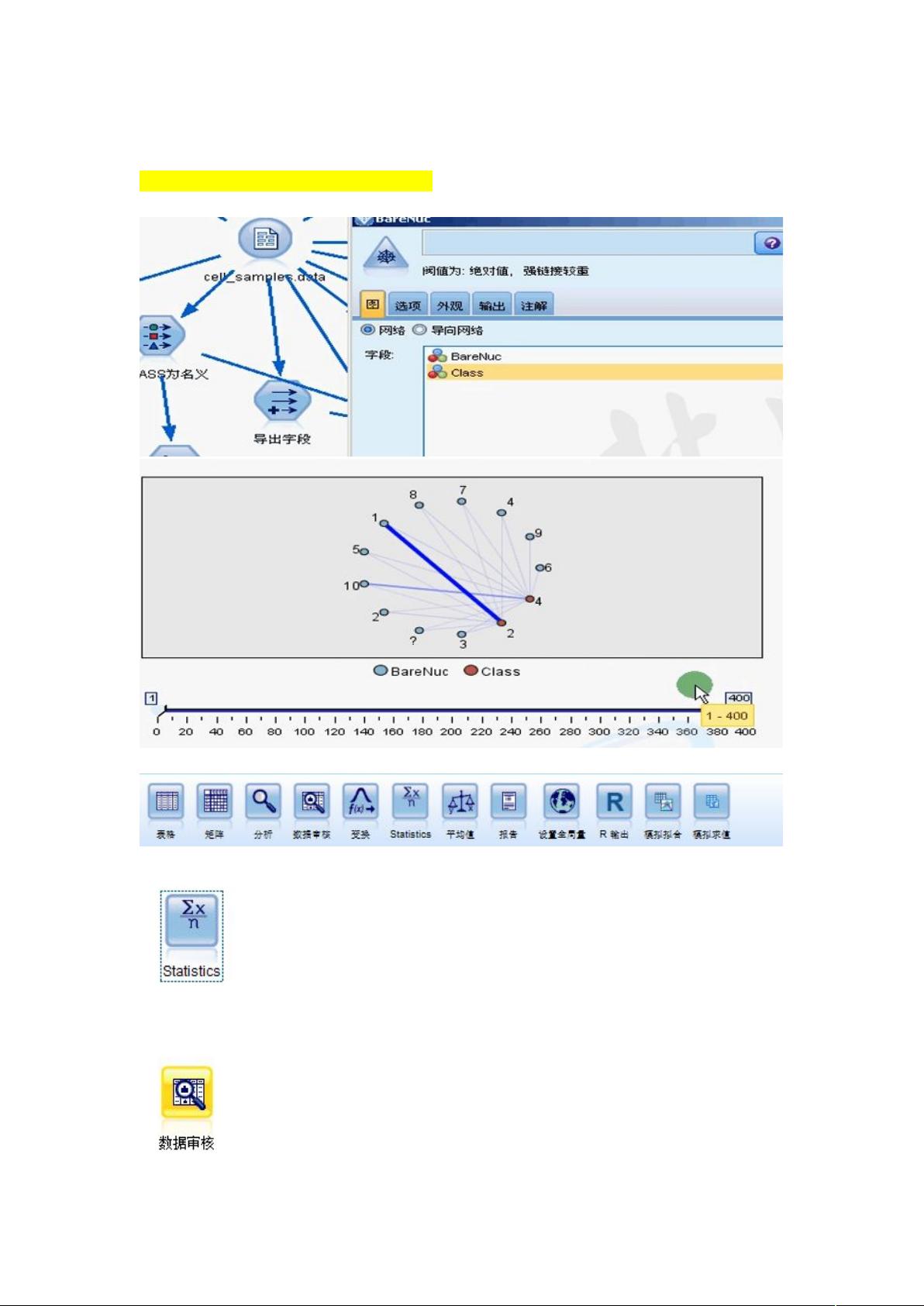
在数据预处理阶段,可以使用各种节点来进行操作,如匿名化保护数据隐私,重新分类调整数据分布,以及通过分区节点来分割数据。图形节点,如网络图,能直观展示字段间的关联性,帮助理解数据结构。例如,线的粗细表示关联性强弱。
此外,SPSS Modeler还提供了统计描述性分析和表格分类功能,以VSM为例,可以对数据进行深入理解。在数据质量方面,可以通过数据审核检查完整性(记录和字段的完整)、准确性(异常和错误)、一致性和及时性。
在模型构建和比较中,可以使用多种建模方法,并通过对比选择最佳模型。每个模型的详细情况可以通过双击查看,包括各个元素的重要性。模型的摘要信息有助于后期的分析和选择。
在数据合并时,可以利用记录选项来合并重复的关键字段,例如,通过ID或序号将两个数据集追加在一起。如果存在缺失值,可以采取填充或删除策略,但直接填充可能成本过高,需要根据具体情况分析。
例如,若要预测网银用户的消费行为,可能会基于信用卡数量设定阈值(如大于等于3张)作为开通网银的指标。在处理这种问题时,所有带问号的字段都需填写或处理,以确保模型的准确性。
SPSS Modeler提供了一套强大的工具,用于数据清洗、转换、建模和评估,以支持有效的数据分析和决策。
图形节点
、
剩余38页未读,继续阅读
3888 浏览量
208 浏览量

汀、人工智能
- 粉丝: 9w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Apache Flink流处理技术详解及应用操作
- VB计时器软件开发与源代码分析
- FW300网卡驱动最新下载与安装指南
- Altium Designer9原理及PCB库指南:涵盖STM32F103/107封装
- Colton Ogden开发的pongGame游戏教程
- 龙族rmtool服务器管理工具源码开放
- .NET反汇编及文件处理工具集下载使用介绍
- STM32 EEPROM I2C中断DMA驱动实现
- AI122/AI123可编程自动化控制器详细数据手册
- 触控笔LC谐振频率测试程序实现与展示
- SecureCRT 7.3.3 官方原版下载指南
- 力反馈功能增强:Arduino游戏杆库使用指南
- 彼岸鱼的GitHub项目HiganFish概述与统计
- JsonUtil工具类:实现对象与Json字符串间转换
- eNSP企业网络拓扑设计:全网互通与带宽优化策略
- 探索3D Lindenmayer系统在3D建模中的应用
