大模型推理显存分析与KVcache原理
需积分: 5 111 浏览量
更新于2024-06-16
收藏 13.59MB PDF 举报
"这篇文档是关于大模型推理过程中显存分析和KVcache原理的讨论,主要聚焦于Transformer模型。文档作者通过Huawei Ascend平台提供了深入的理解,包括Transformer的结构、参数量与模型大小的关系以及大模型训练时的内存占用情况。"
在深度学习领域,特别是自然语言处理(NLP)中,Transformer模型已经成为主流架构。Transformer的设计由Self-attention层和多层感知机(MLP)层构成,这两部分是模型的核心。Self-attention层允许模型在处理序列数据时考虑全局依赖,而MLP则用于非线性变换和信息整合。随着模型规模的增大,如LLAMA系列模型,其参数量急剧增加,导致在推理阶段对显存的需求也相应增大。
对于模型的参数量,我们可以看到,随着隐藏层维度(ℎ)和层数(𝑙)的增加,实际参数量会以平方级别增长。例如,LLAMA-6B模型有4096个隐藏层维度和32层,其参数量达到6442450944,模型大小约为6.7B,需要12GB的显存来存储FP16格式的权重。如果使用FP32格式,则需要双倍的显存空间。
在大模型的训练过程中,显存管理至关重要。即使是相对较小的模型如BERT,在训练时也会占据大部分显存,尤其是在大规模的数据集上。这促使研究者寻找解决方案,比如KVcache,这是一种优化策略,用于缓存和复用频繁访问的数据,以减少内存消耗。KVcache在大模型推理中尤其有用,因为它可以降低显存压力,通过存储和重用先前计算的结果,避免重复计算,从而提高计算效率。
在华为Ascend平台上,这样的内存优化技术是实现高效运行大型AI模型的关键。通过对Transformer的显存占用进行回顾和分析,以及理解和应用KVcache原理,开发者和研究人员能够更好地优化模型性能,同时减少硬件资源的需求,实现更高效的推理服务。
7
Huawei Ascend. ZOMI
Course https://chenzomi12.github.io/
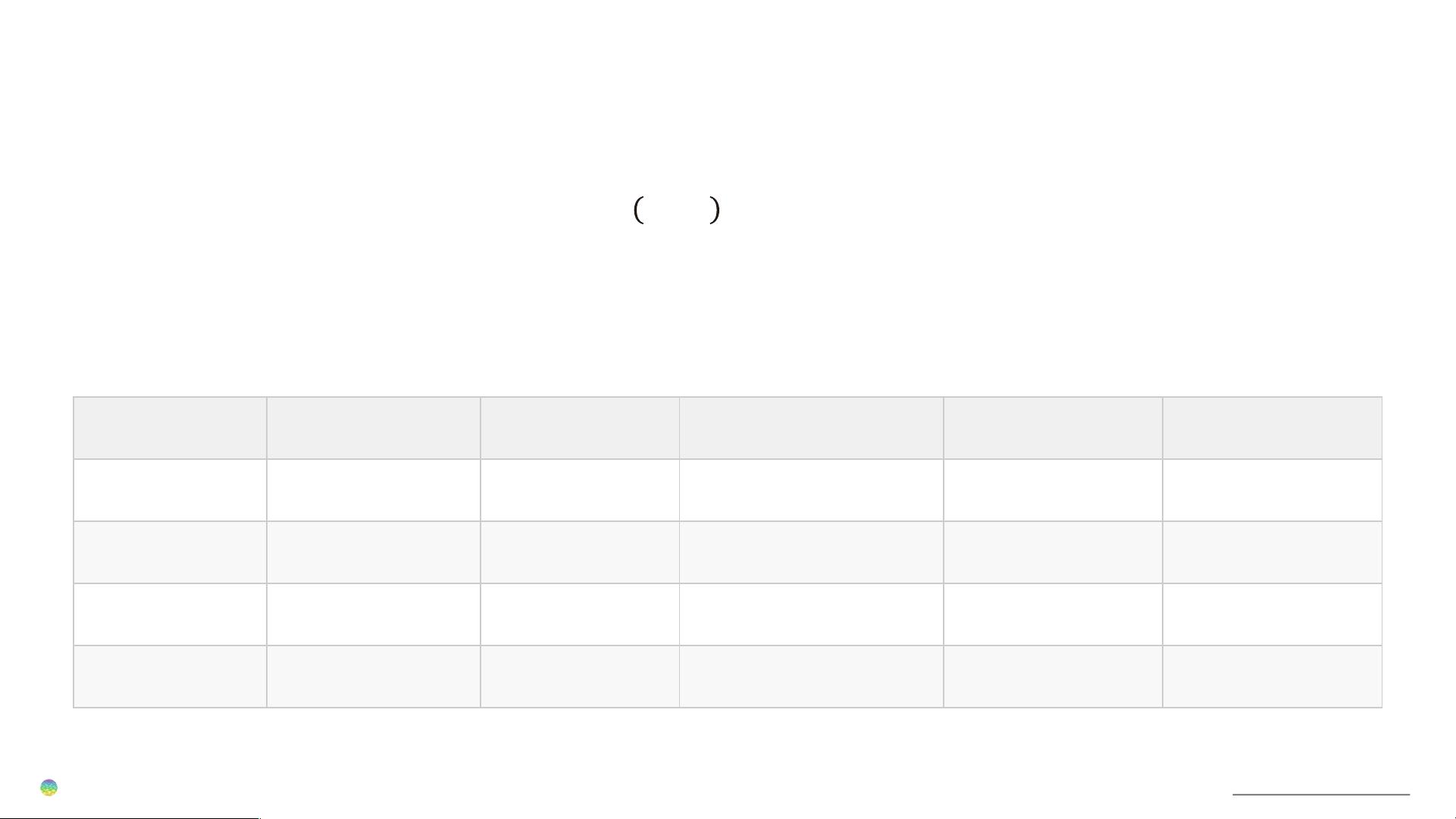
模型参数量与模型大小关系
模型名称 隐藏层维度 ℎ 层数 𝑙 12ℎ
!
实际参数量
模型大小 (FP16)
LLAMA-6B 4096 32 6442450944 6.7B 12 GB
LLAMA-13B 5120 40 12582912000 13.0B 23.4 GB
LLAMA-33B 6656 60 31897681920 32.5B 59.4 GB
LLAMA-65B 8192 80 64424509440 65.2B 120 GB
• 𝑙 层 Transformer 结构可训练参数量为 𝑙 12ℎ
!
+ 𝑽ℎ
• 模型使用 FP16/BF16 方式保存和加载到显存,那么占用 2 个 Byte
• 模型使用 FP32 方式保存和加载到显存,那么占用 4 个 Byte
剩余33页未读,继续阅读
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传
2025-03-06 上传

LittleBrightness
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 昆仑通态MCGS嵌入版_XMTJ温度巡检仪软件包解压教程
- MultiBaC:掌握单次与多次组批处理校正技术
- 俄罗斯方块C/C++源代码及开发环境文件分享
- 打造Android跳动频谱显示应用
- VC++实现图片处理的小波变换方法
- 商城产品图片放大镜效果的实现与用户体验提升
- 全新发布:jQuery EasyUI 1.5.5中文API及开发工具包
- MATLAB卡尔曼滤波运动目标检测源代码及数据集
- DoxiePHP:一个PHP开发者的辅助工具
- 200mW 6MHz小功率调幅发射机设计与仿真
- SSD7课程练习10答案解析
- 机器人原理的MATLAB仿真实现
- Chromium 80.0.3958.0版本发布,Chrome工程版新功能体验
- Python实现的贵金属追踪工具Goldbug介绍
- Silverlight开源文件上传工具应用与介绍
- 简化瀑布流组件实现与应用示例
